Всё, что вы не знали о CAP теореме
Во время моего первого опыта работы с распределенными системами я постоянно сталкивался с некой CAP-теоремой, пришлось изрядно покопать, чтобы изучить и осознать её со всех сторон. Я не являюсь мастером баз данных, но надеюсь, что мое маленькое исследование мира распределённых систем будет полезно для обычных разработчиков. В статье я расскажу о том, что такое CAP, его проблемы и альтернативы, а также рассмотрим некоторые популярные системы баз данных через CAP призму.
CAP теорема
Эта теорема была представлена на симпозиуме по принципам распределенных вычислений в 2000 году Эриком Брюером. В 2002 году Сет Гилберт и Нэнси Линч из MIT опубликовали формальное доказательство гипотезы Брюера, сделав ее теоремой.
По словам Брюера, он хотел, чтобы сообщество начало дискуссию о компромиссах в распределённых системах и уже спустя некоторое количество лет начал вносить в неё поправки и оговорки.
Что стоит за CAP
В CAP говорится, что в распределенной системе возможно выбрать только 2 из 3-х свойств:
- C (consistency) — согласованность. Каждое чтение даст вам самую последнюю запись.
- A (availability) — доступность. Каждый узел (не упавший) всегда успешно выполняет запросы (на чтение и запись).
- P (partition tolerance) — устойчивость к распределению. Даже если между узлами нет связи, они продолжают работать независимо друг от друга.
В основном это всё треугольник
Многие статьи сводятся к вот такому вот простому треугольнику.
Применяем на практике
Для применения CAP теоремы на практике, я выбрал 3 наиболее, на мой взгляд, подходящие и достаточно популярные системы баз данных: Postgresql, MongoDB, Cassandra.
Посмотрим на Postgresql
Следующие пункты относятся к абстрактной распределенной БД Postgresql.
- Репликация Master-Slave — одно из распространенных решений
- Синхронизация с Master в асинхронном / синхронном режиме
- Система транзакций использует двухфазный коммит для обеспечения consistency
- Если возникает partition, вы не можете взаимодейстовать с системой (в основном случае)
Посмотрим на MongoDB
Следующие пункты относятся к абстрактной распределенной БД MongoDB.
- MongoDB обеспечивает strong consistency, потому что это система с одним Master узлом, и все записи идут по умолчанию в него.
- Автоматическая смена мастера, в случае отделения его от остальных узлов.
- В случае разделения сети, система прекратит принимать записи до тех пор, пока не убедится, что может безопасно завершить их.
Посмотрим на Cassandra
Cassandra использует схему репликации master-master, что фактически означает AP систему, в которой разделение сети приводит к самодостаточному функционированию всех узлов.
Казалось бы всё просто… Но это не так.
Проблемы CAP
На тему проблем в CAP теореме написано множество подробных и интересных статей, здесь, на Хабре, поэтому я оставлю ссылку на CAP больше не актуален и мифы о CAP теореме. Обязательно почитайте их, но относитесь к каждой статье, как к своего рода новому взгляду и не принимайте слишком близко к сердцу, потому что одни ругают, другие хвалят. Сам же я не буду слишком углублятся, а постараюсь выдать некоторую необходимую компиляцию.
Итак, проблемы CAP теоремы:
- Далёкие от реального мира определения
- В рамках разработки, выбор в основном лежит между CP и AP
- Множество систем — просто P
- Чистые AP и CP системы могут быть не тем, что ожидаешь
Что не так с определениями?
Consistency в CAP фактически означает линеаризуемость (и ее действительно трудно достичь). Чтобы объяснить, что такое линеаризуемость, давайте посмотрим на следующую картинку:
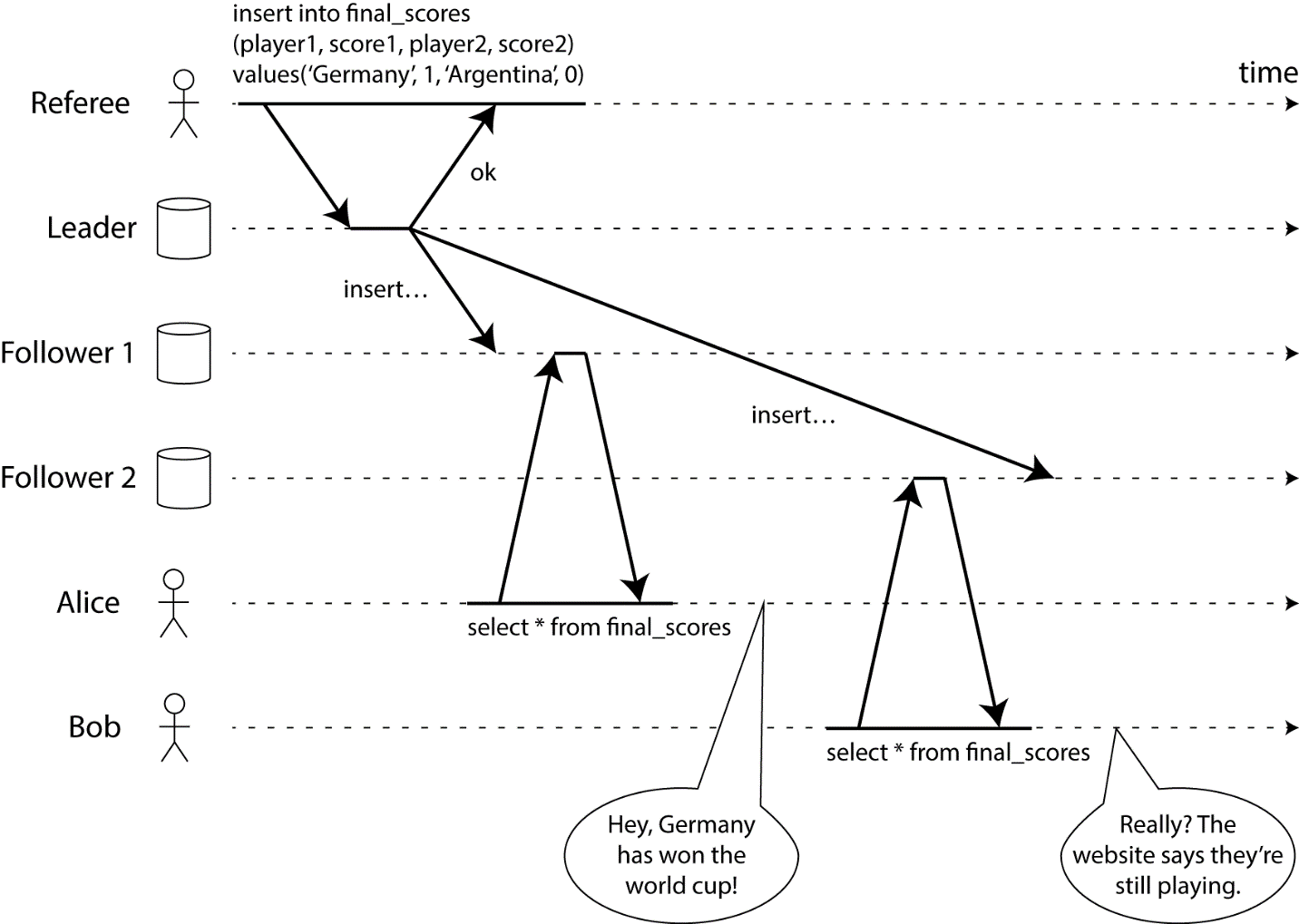
В описанном случае рефери закончил игру, но не каждый клиент получает один и тот же результат. Чтобы сделать его систему линеаризованной, нам нужно мгновенно синхронизировать данные между рефери и другими источниками данных, чтобы, когда рефери закончит игру, каждый клиент получил правильную информацию.
Availability в CAP, исходя из определения имеет две серьёзные проблемы. Первая — нет понятия частичной доступности, или какой-то её степени (проценты например), а есть только полная доступность. Вторая проблема — неограниченное время ответа на запросы, т.е. даже если система отвечает час, она всё ещё доступна.
Устойчивость к распределению не включает в себя упавшие узлы, и вот почему:
- По определению. В availability так и прописано «. every node (if not failed) always. «
- Исходя из доказательства. Доказательства CAP теоремы гласят что на узлах должен исполняться некоторый код.
- Ну и немного моих (и не только) домыслов. В случае падения узла, система может восстановиться, пообщаться с другими узлами и продолжить работу как ни в чем ни бывало. В случае разделения сети — придётся ждать восстановления соединения.
AP / CP выбор
Коммуникация узлов между собой обычно происходит через асинхронную сеть, которая может задерживать или удалять сообщения. Интернет и все наши центры обработки данных обладают этим свойством, и это не маловероятные инциденты, поэтому CA системы в рамках разработки рассматриваются крайне редко.
Многие системы — просто P
Представьте систему, в которой два узла (Master, Slave) и клиент. Если вдруг вы потеряли связь с Master, клиент может читать из Slave, но не может писать — нет CAP-availability.
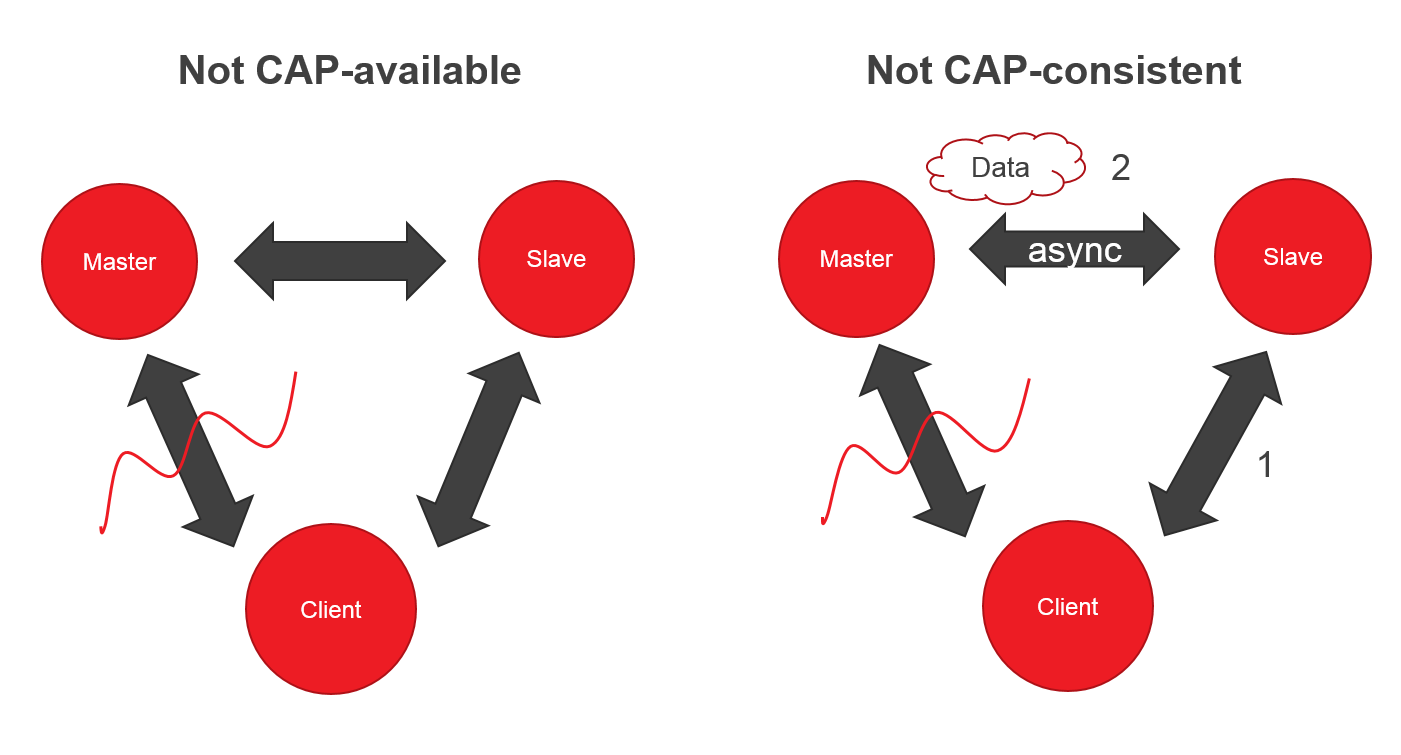
Ок, вроде CP система, но если Master и Slave синхронизируются асинхронно, то клиент, может запросить данные от Slave раньше успешной синхронизации — теряем CAP-consistency.
Чистые AP и CP системы
Чистые AP системы, могут включать в себя просто 2 генератора чисел. Чистые CP системы, могут вообще не быть доступны, т.к. буду пытаться придти к согласованному состоянию и не будут нам отвечать. Идём дальше, CP системы дают нам не ожидаемый нами strong consistency, а eventual consistency. О нём поговорим чуть позже.
Как с этим жить
В конце концов, это всего лишь попытка классифицировать что-то абстрактное, поэтому вам не нужно изобретать велосипед. Я рекомендую использовать следующий подход при попытке работать с распределенными БД:
- Помните об определениях CAP и об их ограничениях.
- Используйте теорему PACELC вместо CAP, она позволяет взглянуть на систему ещё с одного ракурса.
- Помните про принципы ACID / BASE и насколько они применимы к вашей системе.
- Любые телодвижения следует делать, учитывая проект, над которым вы работаете.
PACELC
Теорема PACELC была впервые описана и формализована Даниелом Дж. Абади из Йельского университета в 2012 году. Поскольку теорема PACELC основана на CAP, она также использует его определения.
Вся теорема сводится к IF P -> (C or A), ELSE (C or L).
Latency — это время, за которое клиент получит ответ и которое регулируется каким-либо уровнем consistency. Latency (задержка), в некотором смысле представляет собой степень доступности.
Немного о BASE
BASE — это своеобразный контраст ACID, который говорит нам, что истинная согласованность не может быть достигнута в реальном мире и не может быть смоделирована в высокомасштабируемых системах.
Что стоит за BASE:
- Basic Availability. Система отвечает на любой запрос, но этот ответ может быть содержать ошибку или несогласованные данные.
- Soft-state. Состояние системы может меняться со временем из-за изменений конечной согласованности.
- Eventual consistency (конечная согласованность). Система, в конечном итоге, станет согласованной. Она будет продолжать принимать данные и не будет проверять каждую транзакцию на согласованность.
Свежий взгляд
Теперь, когда мы знаем о большинстве подводных камней, давайте попробуем рассмотреть те же самые популярные системы баз данных через призму полученных знаний.
Postgresql
Postgresql действительно допускает множество различных конфигураций системы, поэтому их очень сложно описать. Давайте просто возьмем классическую Master-Slave репликацию с реализацией через Slony.
- Система работает в соответствии с ACID (существует пара проблем с двухфазным коммитом, но это вне рамок статьи).
- В случае разрыва связи, Slony попытается переключиться на новый Master, и у нас есть новый мастер с его согласованностью.
- Когда система функционирует в нормальном режиме, Slony делает все, чтобы достичь strong consistency. На самом деле, ACID — причина большой задержки в этой системе.
- Классификация системы — PC / EC (A).
MongoDB
Давайте узнаем что-то новое о MongoDB:
- Это ACID в ограниченном смысле на уровне документа.
- В случае распределенной системы — it’s all about that BASE.
- В случае отсутствия разделений сети, система гарантирует, что чтение и запись будут согласованными.
- Если Master узел упадёт или потеряет связь с остальной системой, некоторые данные не будут реплицированы. Система выберет нового мастера, чтобы оставаться доступной для чтения и записи. (Новый мастер и старый мастер несогласованы).
- Система рассматривается как PA / EC (A), так как большинство узлов остаются CAP-available в случае разрыва. Помните, что в CAP MongoDB обычно рассматривается как CP. Создателль PACELC, Даниэль Дж. Абади, говорит, что существует гораздо больше проблем с согласованностью, чем с доступностью, поэтому PA.
Cassandra
- Предназначена для «скоростного» взаимодействия (low-latency interactions).
- ACID на уровне записи.
- В случае распределенной системы — it’s all about that BASE.
- Если возникает разрыв связи, остальные узлы продолжают функционировать.
- В случае нормального функционирования — система использует уровни согласованности для уменьшения задержки.
- Система рассматривается как PA / EL (A).
Выводы
- Компромиссы распределённых систем — это то, с чего стоит начинать процесс проектирования.
- Достаточно трудно классифицировать абстрактную систему, гораздо лучше сначала сформировать требования исходя из технического задания, а уже затем правильно сконфигурировать нужную систему баз данных.
- Не перетруждайтесь, мы ведь просто любопытные разработчики, если в чем-то есть сомнения — обратитесь к эксперту.
Go — Slices
Go Slice — это абстракция над массивом Go. Go Array позволяет вам определять переменные, которые могут содержать несколько элементов данных одного и того же типа, но он не предоставляет встроенного метода для динамического увеличения его размера или получения собственной подматрицы. Ломтики преодолевают это ограничение. Он предоставляет множество функций утилиты, требуемых для массива, и широко используется в программировании Go.
Определение среза
Чтобы определить срез, вы можете объявить его как массив без указания его размера. Кроме того, вы можете использовать функцию make для создания среза.
var numbers []int /* a slice of unspecified size */ /* numbers == []int*/ numbers = make([]int,5,5) /* a slice of length 5 and capacity 5*/Функции len () и cap ()
Срез — это абстракция над массивом. Он фактически использует массивы в качестве базовой структуры. Функция len () возвращает элементы, представленные в срезе, где функция cap () возвращает емкость среза (т. Е. Сколько элементов он может разместить). В следующем примере объясняется использование slice
package main import "fmt" func main() < var numbers = make([]int,3,5) printSlice(numbers) >func printSlice(x []int)
Nil slice
Если разрез объявлен без ввода, то по умолчанию он инициализируется как нуль. Его длина и емкость равны нулю.
package main import "fmt" func main() < var numbers []int printSlice(numbers) if(numbers == nil)< fmt.Printf("slice is nil") >> func printSlice(x []int)
Subslicing
Slice позволяет определить нижнюю границу и верхнюю границу, чтобы получить ее часть, используя [нижняя граница: верхняя граница] .
Функции append () и copy ()
Можно увеличить емкость среза с помощью функции append () . Используя функцию copy () , содержимое среза источника копируется в целевой срез.
SAP CAP function and action with Unstructured/Dynamic Type Input/Output
While developing enterprise ready cloud applications using Cloud Application Application programming model (CAP), you can define / model custom operations specific to business entity or process via functions or actions in addition to CRUD operations.
- Actions are used for operations, which add or modify data via POST request.
- Functions are used to only retrieve data via GET request.
Both actions and functions can be bound which means this custom operation is connected to a business entity or unbound which means this operation can be on one or more entities. More information can be found here.
In most cases, You will have a fixed structure/type input or output for custom operations. However in very few cases you might have an operation where input or output changes time to time. In this blog post, i will show how you can define such an action or function which takes input and provides output with dynamic type.
CAP currently support 3 protocols i.e. OData V4, Rest, GraphQL. Out of these 3 protocols, only in Rest protocol based services you can define functions and actions with dynamic input and/or output.
Let’s look at an example:
Service Definiation:
@protocol: 'rest' service RootService < @open type object <>; action MyAction(input : object) returns object; function MyFunction(category : Integer) returns object; >By annotating the service with @protocol: ‘rest’, the service becomes rest compliant. In above example, cds type “object” is annotated with @open to indicate that the structure or type is unknown. Then it is used in both MyAction and MyFunction operations.
Service Implementation
const cds = require("@sap/cds"); module.exports = cds.service.impl(async function (srv) < srv.on('MyAction', async(req)=>< req.data["AdditionalField"] = "AdditionalFieldValue"; return req.data; >), srv.on('MyFunction', async(req)=>< let result = <>; if(req.data.category === 1)< result.category = 'Category 1'; result.field1 = "Random Field Value"; result.field2 = [] >else< result.category = ; result.field1 = "Random Field Value"; result.field2 = [, ]; > return result; >) >);In the implementation of MyAction operation, an additional field is added with the incoming data. Simillarly the result of MyFunction operation is different based on the input category. Both of these implementations are coded just to indicate that the resultant structres are dynamic.
Testing the above code and its corresponding responses.
| Operation | Request/Response |
| MyAction | Request: |
POST http://localhost:4004/root/MyAction Content-Type: application/json < "input":< "field1":123, "field2":"Value" >>< "input": < "field1": 123, "field2": "Value" >, "AdditionalField": "AdditionalFieldValue" >POST http://localhost:4004/root/MyAction Content-Type: application/json < "input":< "field1":123, "field2":[10,20] >>< "input": < "field1": 123, "field2": [ 10, 20 ] >, "AdditionalField": "AdditionalFieldValue" >GET http://localhost:4004/root/MyFunction(category=1) Accept: application/jsonGET http://localhost:4004/root/MyFunction(category=2) Accept: application/json< "category": < "Info": "Category2" >, "field1": "Random Field Value", "field2": [ < "f1": "f1 Value1" >, < "f1": "f1 Value2", "f2": "f2 Value2" >] >Note that this is currently possible in CAP services with Rest Protocol only. Hope this feature will be added for other protocols as well.
More information aboue cloud application programming model can be found here. You can follow my profile to get notification of the next blog post on CAP. Please feel free to provide any feedback you have in the comments section below and ask your questions about the topic in sap community using this link.
Go Slices: usage and internals
Go’s slice type provides a convenient and efficient means of working with sequences of typed data. Slices are analogous to arrays in other languages, but have some unusual properties. This article will look at what slices are and how they are used.
Arrays
The slice type is an abstraction built on top of Go’s array type, and so to understand slices we must first understand arrays.
An array type definition specifies a length and an element type. For example, the type [4]int represents an array of four integers. An array’s size is fixed; its length is part of its type ( [4]int and [5]int are distinct, incompatible types). Arrays can be indexed in the usual way, so the expression s[n] accesses the nth element, starting from zero.
var a [4]int a[0] = 1 i := a[0] // i == 1 Arrays do not need to be initialized explicitly; the zero value of an array is a ready-to-use array whose elements are themselves zeroed:
// a[2] == 0, the zero value of the int type The in-memory representation of [4]int is just four integer values laid out sequentially:

Go’s arrays are values. An array variable denotes the entire array; it is not a pointer to the first array element (as would be the case in C). This means that when you assign or pass around an array value you will make a copy of its contents. (To avoid the copy you could pass a pointer to the array, but then that’s a pointer to an array, not an array.) One way to think about arrays is as a sort of struct but with indexed rather than named fields: a fixed-size composite value.
An array literal can be specified like so:
b := [2]string
Or, you can have the compiler count the array elements for you:
b := [. ]string
In both cases, the type of b is [2]string .
Slices
Arrays have their place, but they’re a bit inflexible, so you don’t see them too often in Go code. Slices, though, are everywhere. They build on arrays to provide great power and convenience.
The type specification for a slice is []T , where T is the type of the elements of the slice. Unlike an array type, a slice type has no specified length.
A slice literal is declared just like an array literal, except you leave out the element count:
letters := []string
A slice can be created with the built-in function called make , which has the signature,
func make([]T, len, cap) []T where T stands for the element type of the slice to be created. The make function takes a type, a length, and an optional capacity. When called, make allocates an array and returns a slice that refers to that array.
var s []byte s = make([]byte, 5, 5) // s == []byte
When the capacity argument is omitted, it defaults to the specified length. Here’s a more succinct version of the same code:
s := make([]byte, 5) The length and capacity of a slice can be inspected using the built-in len and cap functions.
len(s) == 5 cap(s) == 5 The next two sections discuss the relationship between length and capacity.
The zero value of a slice is nil . The len and cap functions will both return 0 for a nil slice.
A slice can also be formed by “slicing” an existing slice or array. Slicing is done by specifying a half-open range with two indices separated by a colon. For example, the expression b[1:4] creates a slice including elements 1 through 3 of b (the indices of the resulting slice will be 0 through 2).
b := []byte // b[1:4] == []byte, sharing the same storage as b The start and end indices of a slice expression are optional; they default to zero and the slice’s length respectively:
// b[:2] == []byte // b[2:] == []byte // b[:] == b This is also the syntax to create a slice given an array:
x := [3]string s := x[:] // a slice referencing the storage of x Slice internals
A slice is a descriptor of an array segment. It consists of a pointer to the array, the length of the segment, and its capacity (the maximum length of the segment).

Our variable s , created earlier by make([]byte, 5) , is structured like this:
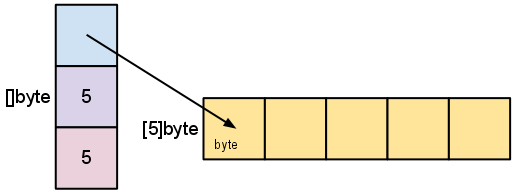
The length is the number of elements referred to by the slice. The capacity is the number of elements in the underlying array (beginning at the element referred to by the slice pointer). The distinction between length and capacity will be made clear as we walk through the next few examples.
As we slice s , observe the changes in the slice data structure and their relation to the underlying array:
s = s[2:4] 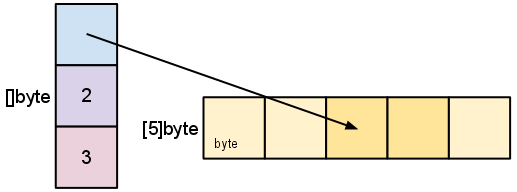
Slicing does not copy the slice’s data. It creates a new slice value that points to the original array. This makes slice operations as efficient as manipulating array indices. Therefore, modifying the elements (not the slice itself) of a re-slice modifies the elements of the original slice:
d := []byte e := d[2:] // e == []byte e[1] = 'm' // e == []byte // d == []byte
Earlier we sliced s to a length shorter than its capacity. We can grow s to its capacity by slicing it again:
s = s[:cap(s)] 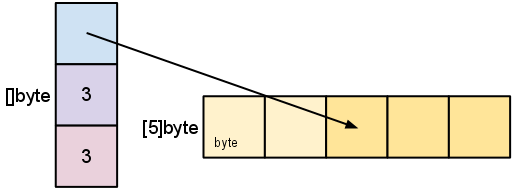
A slice cannot be grown beyond its capacity. Attempting to do so will cause a runtime panic, just as when indexing outside the bounds of a slice or array. Similarly, slices cannot be re-sliced below zero to access earlier elements in the array.
Growing slices (the copy and append functions)
To increase the capacity of a slice one must create a new, larger slice and copy the contents of the original slice into it. This technique is how dynamic array implementations from other languages work behind the scenes. The next example doubles the capacity of s by making a new slice, t , copying the contents of s into t , and then assigning the slice value t to s :
t := make([]byte, len(s), (cap(s)+1)*2) // +1 in case cap(s) == 0 for i := range s < t[i] = s[i] >s = t The looping piece of this common operation is made easier by the built-in copy function. As the name suggests, copy copies data from a source slice to a destination slice. It returns the number of elements copied.
func copy(dst, src []T) int The copy function supports copying between slices of different lengths (it will copy only up to the smaller number of elements). In addition, copy can handle source and destination slices that share the same underlying array, handling overlapping slices correctly.
Using copy , we can simplify the code snippet above:
t := make([]byte, len(s), (cap(s)+1)*2) copy(t, s) s = t A common operation is to append data to the end of a slice. This function appends byte elements to a slice of bytes, growing the slice if necessary, and returns the updated slice value:
func AppendByte(slice []byte, data . byte) []byte < m := len(slice) n := m + len(data) if n >cap(slice) < // if necessary, reallocate // allocate double what's needed, for future growth. newSlice := make([]byte, (n+1)*2) copy(newSlice, slice) slice = newSlice >slice = slice[0:n] copy(slice[m:n], data) return slice > One could use AppendByte like this:
p := []byte p = AppendByte(p, 7, 11, 13) // p == []byte
Functions like AppendByte are useful because they offer complete control over the way the slice is grown. Depending on the characteristics of the program, it may be desirable to allocate in smaller or larger chunks, or to put a ceiling on the size of a reallocation.
But most programs don’t need complete control, so Go provides a built-in append function that’s good for most purposes; it has the signature
func append(s []T, x . T) []T The append function appends the elements x to the end of the slice s , and grows the slice if a greater capacity is needed.
a := make([]int, 1) // a == []int a = append(a, 1, 2, 3) // a == []int
To append one slice to another, use . to expand the second argument to a list of arguments.
a := []string b := []string a = append(a, b. ) // equivalent to "append(a, b[0], b[1], b[2])" // a == []string
Since the zero value of a slice ( nil ) acts like a zero-length slice, you can declare a slice variable and then append to it in a loop:
// Filter returns a new slice holding only // the elements of s that satisfy fn() func Filter(s []int, fn func(int) bool) []int < var p []int // == nil for _, v := range s < if fn(v) < p = append(p, v) >> return p > A possible “gotcha”
As mentioned earlier, re-slicing a slice doesn’t make a copy of the underlying array. The full array will be kept in memory until it is no longer referenced. Occasionally this can cause the program to hold all the data in memory when only a small piece of it is needed.
For example, this FindDigits function loads a file into memory and searches it for the first group of consecutive numeric digits, returning them as a new slice.
var digitRegexp = regexp.MustCompile("[0-9]+") func FindDigits(filename string) []byte
This code behaves as advertised, but the returned []byte points into an array containing the entire file. Since the slice references the original array, as long as the slice is kept around the garbage collector can’t release the array; the few useful bytes of the file keep the entire contents in memory.
To fix this problem one can copy the interesting data to a new slice before returning it:
func CopyDigits(filename string) []byte
A more concise version of this function could be constructed by using append . This is left as an exercise for the reader.