Калькулятор достоверности
Не каждый результат эксперимента имеет статистический вес. Некоторые значения могут быть следствием ошибки. Калькулятор достоверности помогает понять, какие из них являются значимыми для статистики и могут служить основанием для формулировки выводов.
Что такое статистическая значимость
Это показатель вероятности того, что разница между контрольным и тестовым вариантами экспериментальных данных не является случайной или ошибочной.

Простыми словами, в A/B-тестировании он показывает, с какой вероятностью тот факт, что улучшенная версия тестируемой страницы имеет более высокие оценки, не будет случайным.
Измерить надежность результатов позволяет оценка достоверности. Если она высокая, можно считать исход исследования значимым. Это помогает сделать заключение о том, что именно внесенные изменения, а не случайность, повлияли на улучшение показателей.
- 95-100% – высокая статистическая значимость. Внесенные изменения стоит применить на сайте.
- 90-95% – результат имеет невысокий процент значимости для статистики. Рекомендуется делать корректировки осторожно, а лучше повторить A/B-тестирование.
- Менее 90% – данные не значимы для статистики. Не рекомендуется вносить такие изменения.
Этот параметр применяется не только в маркетинге, он также важен для бизнеса. Компании используют его, чтобы проводить эксперименты и отслеживать их влияние на коэффициент конверсии бизнеса. При проведении опросов помогает оценить, насколько ответам можно доверять.
Как провести A/B-тестирование
A/B тестирование чаще всего заключается в сравнении двух веб-страниц, которые отличаются лишь одним измененным элементом. При этом страница А остается прежней и служит контрольной. На странице В вносится небольшое изменение, она является тестовой.
Чтобы получить статистически значимый результат, необходимо тестировать страницу, на которой меняется только один элемент. Корректирование сразу нескольких элементов не позволит понять, какое именно изменение привело к улучшению показателей.
Коррекциям и тестированиям подлежат прежде всего те элементы, которые нужны для проявления активности пользователей и увеличения конверсии:
- призывы к действию;
- кнопки CTA;
- заголовки;
- рекламные тексты;
- изображения;
- описания товаров.
Изменение может предполагать не только полную замену элемента, но и коррекцию:
После того, как создана дублирующая исходную страница с каким-либо измененным элементом, запускают A/B-тест. При этом половина трафика направляется на контрольную страницу А, а вторая половина – на тестовую В. При этом посетители никогда не узнают, что вошли в фокус-группу и стали участниками маркетинговых исследований.
При получении статистически значимых результатов эксперимента лидером тестирования становится та версия, которая лучше сказывается на конверсии.
Существует несколько правил работы с A/B-тестами:
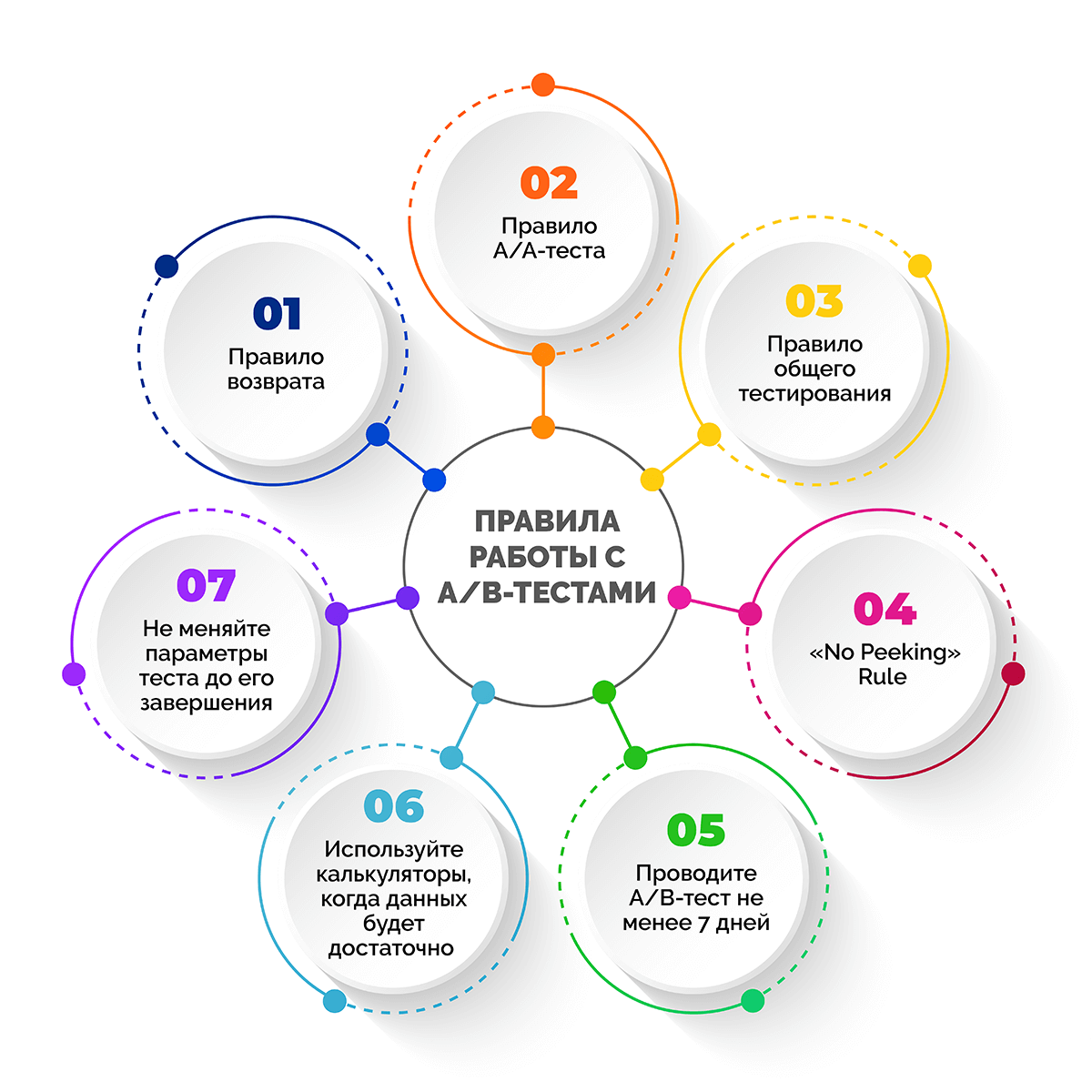
- Правило возврата. Пересмотр ранее проведенных тестов хотя бы раз в полгода способствует возникновению новых идей и даже может заставить изменить подход к тестированию.
- Правило А/А-теста. Одновременное тестирование абсолютно идентичных веб-страниц при определенной выборке дает возможность увидеть, не рано ли приступать к А/Б-тестированию. Если показатели похожи, а стандартное отклонение значений не превышают 10%, пора переходить к реальному сплит-тесту.
- Правило общего тестирования. Тестировать можно не только сайты, но и другие маркетинговые инструменты: рассылки, всплывающие окна, опросы и даже определять самое удачное время получения письма пользователем.
- «No Peeking» Rule или правило «Не подглядывать». Просматривая промежуточные цифры до завершения теста, есть соблазн закончить его раньше времени. Данное правило звучит так: как положительный, так и отрицательный результат, полученный при малой выборке, с высокой вероятностью окажется случайным. Поэтому не стоит доверять данным, если они были получены до окончания эксперимента.
- Другие правила:
- Проводите A/B-тест последовательно и не менее 7 дней;
- Используйте калькуляторы только после того, как статистических данных станет достаточно для анализа;
- Не меняйте параметры теста до его завершения, это приведет к их искажению.
Вместо многочисленных A/B-тестов можно подключить к рекламной кампании сквозную аналитику на основе коннекторов. Она покажет, какие корректировки положительно влияют на конверсию, а какие сливают бюджет.
С чем можно столкнуться при A/B-тестировании
Разберем основные трудности, ошибки и подводные камни, которые часто встречаются при проведении А/Б-тестов.
- Тестирование нескольких элементов одновременно. Так бывает, когда нужно протестировать, например, письмо для email-рассылки с коротким и длинным текстом. При этом в длинном письме не только больше текста, но и другая его структура, формулировка предложений, добавлены визуальные элементы, которых нет в коротком письме. Тестирование в данном случае заведомо непоказательно.
- Проблема подглядывания. Частично о ней мы уже упоминали выше. В данном случае проблема заключается в том, что p-value может как расти, так и опускаться ниже нужного уровня значимости в процессе тестирования. Эти колебания случайны, поэтому вывод о значимости для статистики рискует быть ошибочным, если делать его до завершения эксперимента.
- Непостоянство данных. Параметры сайтов нестабильны, они могут меняться в зависимости от ряда факторов, поэтому и итоги A/B-тестирования тоже могут отличаться. Вот основные факторы влияния:
- сезон или время года;
- праздничные дни, период каникул, отпусков;
- день недели;
- появление в СМИ статей о компании;
- изменения в рекламе;
- изменения в SEO-продвижении;
- распространяемое мнение о компании, слухи, отзывы.
Чтобы сгладить последствия влияния внешних факторов, нужно взять за правило: регулярно проводить мониторинг корректировок и отслеживать закономерности, а также перепроверять то, что выдает А/В-тестирование.
Как определить уровень значимости
Чтобы в конце тестирования сделать правильные выводы, необходимо определить их уровень значимости (significance level). Он показывает, при каких условиях тот или иной вариант будет закономерным. Обычно достоверным считается показатель, полученный в пределах от 90 до 95%.
Для проверки статистической значимости нужно:
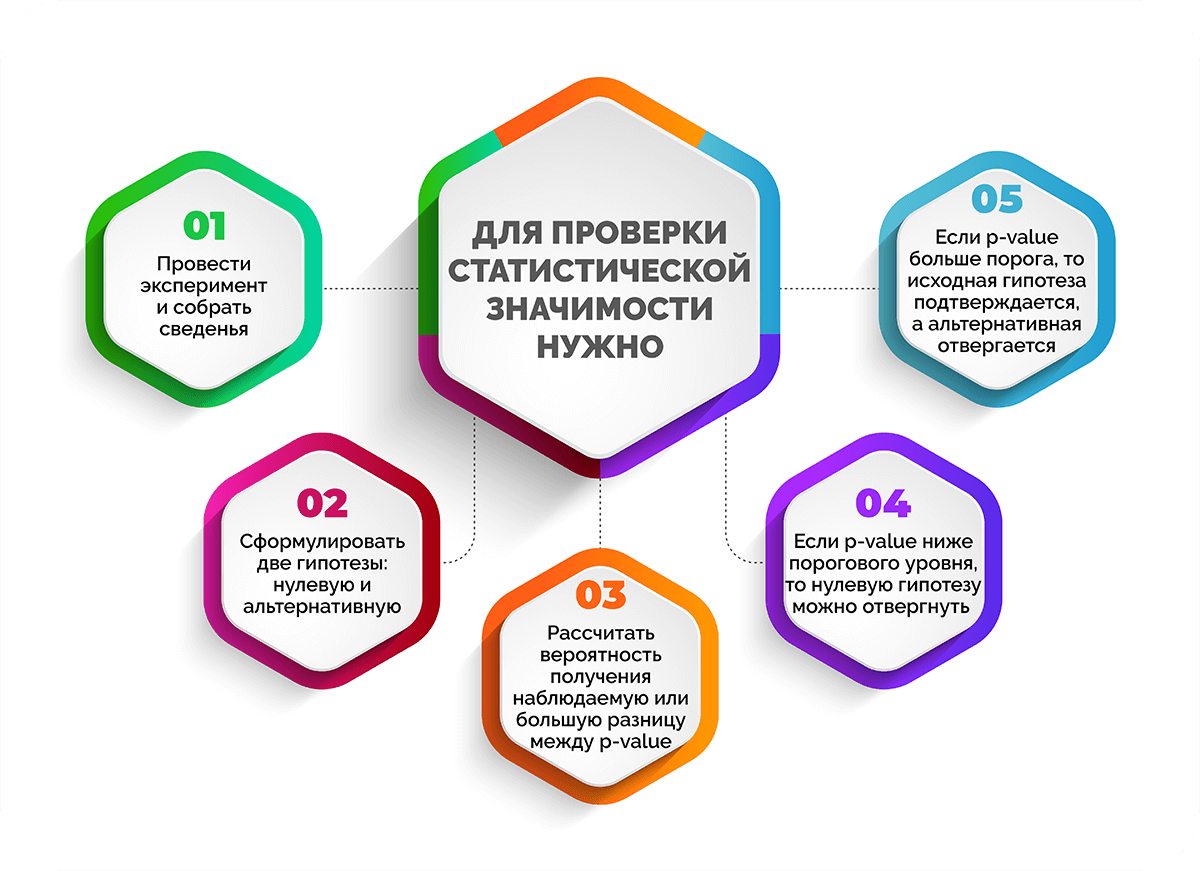
- Провести эксперимент и собрать сведенья, чтобы сделать разные предположения.
- Сформулировать две гипотезы: нулевую и альтернативную. Нулевая гипотеза утверждает, что между сравниваемыми фактами нет связи, альтернативная – что связь существует.
- Если стоит задача доказать, что все факты идентичны, нужно рассчитать вероятность получения наблюдаемую или большую разницу между предположениями (p-value).
- Если p-value ниже порогового уровня, то нулевую гипотезу можно отвергнуть и утверждать о значительной разнице между сравниваемыми группами.
- Если p-value больше порога, то из двух гипотез исходная подтверждается, а альтернативная отвергается.
Для расчета уровня значимости обычно используется калькулятор. Онлайн-сервис позволяет быстро выполнить расчет, не проводя сложных математических вычислений вручную.
Пример расчета
В конце A/B-теста двух страниц сайта были получены такие данные:
- Вариант 1: 1500 новых посещений, из них конверсия – 3 человека;
- Вариант 2: 1500 новых посетителей, из них конверсия – 12 человек.
В калькулятор (calculator) вносим эти числа, чтобы узнать, являются ли они значимыми. При этом выбираем уровень достоверности 95% и смотрим отчет.
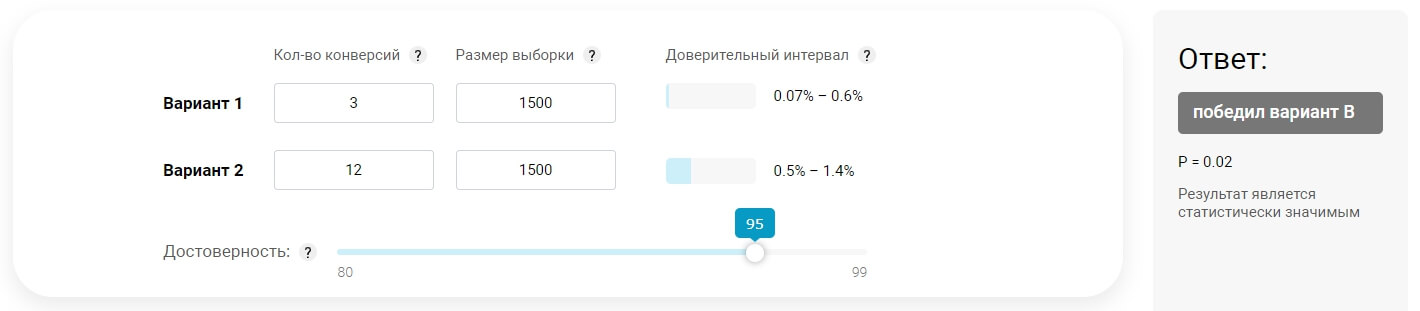
Из вердикта видно, что рост конверсии на странице 2 с вероятностью 95% доказывает влияние внесенных правок на показатель и не является случайностью. Подобные примеры можно приводить бесконечно.
Основные показатели
- CR (conversion rate) – коэффициент конверсии. Показывает предполагаемое число конверсий на каждого посетителя в процентах. Рассчитывается по формуле: CR = (Конверсия / Трафик) × 100%
- Uplift – повышение. Показывает относительный рост конверсии при сравнении двух экземпляров. Может принимать отрицательное значение, если эффективность исходной страницы выше, чем новой. Uplift = (CR Б / CR А) × 100%
- P-value – вероятность получения случайных цифр. Для расчета этого показателя чаще всего используется онлайн-калькулятор.
- Доля признака в генеральной совокупности, для которой определяется ошибка.
- Ошибка выборки или размер доверительного интервала (confidence interval) – отклонение результатов, которые были получены в ходе исследования. Бывает систематическая и статическая.
Статистические критерии, которые рассчитываются с применением калькуляторов
Онлайн-калькуляторы позволяют рассчитывать множество статистических показателей, вот самые распространенные из них:
- выбор статистического метода;
- расчет относительных величин;
- оценка значимости отличий между средними величинами по t-критерию Стьюдента;
- оценка значимости изменений средних величин с помощью парного t-критерия Стьюдента;
- анализ динамического ряда;
- расчет демографических показателей;
- прямой метод стандартизации;
- определение относительного риска;
- вычисление отношения шансов;
- анализ четырехпольной таблицы;
- расчет показателей вариационного ряда;
- расчет критерия Манна-Уитни;
- корреляционно-регрессионный анализ;
- определение коэффициента корреляции Спирмена;
- анализ произвольных сопряженных таблиц с помощью критерия хи-квадрат (х 2 ).
Критерии оценки
Критерий Стьюдента . Разработан для оценки различий между средними величинами двух распределенных по нормальному закону выборок. Благодаря широте применения может использоваться и для сравнения средних у связных и несвязных выборок, в т. ч. различающихся по величине.
Критерий Стьюдента применяется при следующих условиях:
- выборочные совокупности распределяются по нормальному закону;
- измерение может проводиться в шкале отношений и интервалов.
Автоматический расчет t-критерия осуществляется с помощью калькулятора. Для этого нужно:
- Определить тип выборочной совокупности: зависимые (связанные) или независимые (несвязанные).
- Ввести данные для первой и второй выборок, после чего запустить расчет.
F-критерий Фишера . Применяется для проверки статистической значимости как отдельных коэффициентов уравнения регрессии, так и его целиком. Для расчета F-критерия в общем виде используется следующая формула:
F = S 2 факт / S 2 ост, где:
S 2 факт – факторная дисперсия;
S 2 ост – остаточная дисперсия.
Для полученного в ходе расчета значения F-критерия Фишера определяют статистическую значимость путем его сравнения с табличным (критическим) значением.
Как пользоваться калькулятором
Калькулятор статистической значимости позволяет выполнить вычисления в несколько шагов:
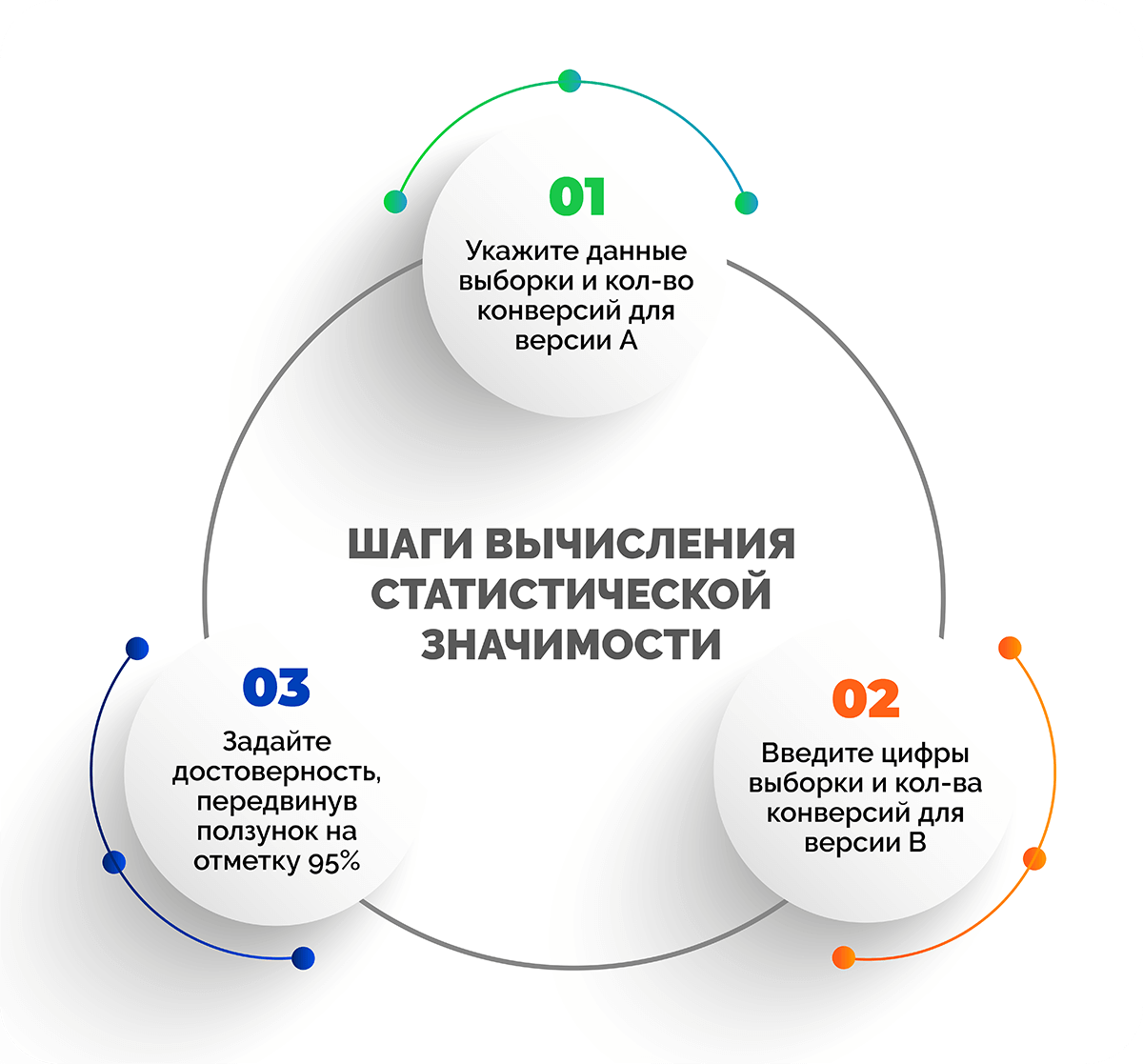
- Укажите данные выборки и количество конверсий для версии А.
- Введите цифры выборки и количества конверсий для версии В.
- Задайте достоверность, передвинув ползунок на отметку 95%.
В калькуляторе варианты А и В – это просто сравниваемые гипотезы. Например, при А/В-тестировании это могут быть данные по исходной и измененной веб-страницам.
Калькулятор автоматически определит результат по указанным данным и напишет, какой имеет более высокую достоверность.
Как интерпретировать результаты
Калькулятор способен выдавать три вариации ответов:
- «победил вариант А» – означает, что итоги А-теста говорят о повышении целевых показателей после тестирования;
- «победил вариант В» – это значит, что по итогам A/B-тестирования версия В показала улучшенные характеристики;
- «между вариантами нет разницы» – полученные сведенья не являются статистически значимыми.
Со статистической значимостью связаны следующие распространенные ошибки:
- Магия цифр – параметры являются доказательством того, что один вариант лучше другого.
На самом деле А/Б-тест не позволяет доказать это, а отражает лишь тот факт, что в одной из версий целевые показатели оказываются более высокими. - Вера в то, что одна версия превосходит другую.
В действительности цифры демонстрируют исключительно вероятность того, что данные, полученные при A/B-тестировании, не случайны. - Значимость мышления.
Речь не идет о том, что пользователи предпочитают одну страницу другой. Оценивается влияние внесенных изменений на то, как ведут себя пользователей.
Определение размера выборки
Выборка – это количество респондентов, которые приняли участие в исследовании. В случае с А/Б-тестированием – посетили обе веб-страницы. Принято считать, что чем больше выборка, тем точнее результат.
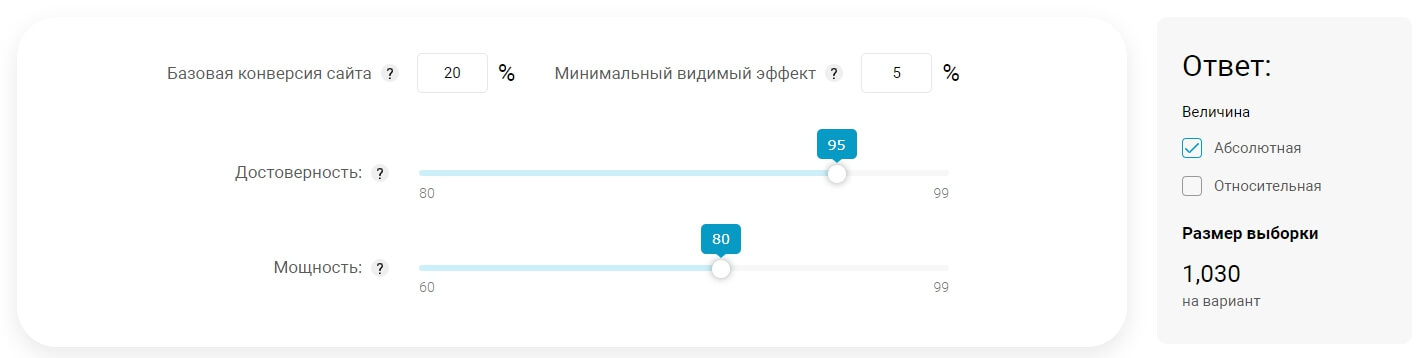
Для расчета размера выборочной совокупности удобно пользоваться онлайн-калькулятором. Чтобы быстро посчитать это значение:
- Укажите базовую конверсию сайта.
- Задайте минимальный видимый эффект (предполагаемый прирост конверсии).
- Передвиньте ползунок на нужный уровень достоверности (рекомендуемое значение – 95%).
- Задайте статистическую мощность теста.
- Выберите нужный способ изменения – абсолютная или относительная величина.
В качестве ответа калькулятор покажет расчетное число уникальных посетителей для каждой тестируемой версии.
Часто задаваемые вопросы
Это позволит определить, можно ли доверять цифрам, которые были получены в ходе проведения A/B-тестирования.
Он оценивается с помощью модели расчет, основанной на общей посещаемости сайта. Если на ресурс приходит меньше 10 тыс. посетителей в месяц, конверсия должна быть более 25%. Если ежемесячное число посетителей достигает 100 тыс. человек, конверсия должна превышать 9%. При трафике до 1 млн пользователей достаточно иметь конверсию в пределах от 2 до 9%.
Вот несколько советов по повышению статистической значимости A/B-тестов:
- получите более согласованные величины с минимальными отклонениями;
- увеличьте объем выборки и длительность тестирования;
- обеспечьте рост конверсии при сравнении веб-страниц.
Упрощенные калькуляторы применяются для облегчения и ускорения процесса вычисления. Мы предлагаем более расширенную версию для определения размера выборочной совокупности, которая нужна для получения статистически значимого итога эксперимента.
Нашли ошибку в тексте? Выделите нужный фрагмент и нажмите ctrl + enter
P-значение и статистические исследования в маркетинге

Маркетинг – та сфера, где больше всего любят работать с большими данными (англ. big data), однако излюбленный инструмент маркетологов – A/B-тестирование – предполагает использование малых данных (англ. small data). При этом какие бы цифры ни были получены по итогам теста, все сводится к анализу статистической выборки и определению статистической значимости результатов эксперимента. Неотъемлемой частью данного исследования является P-значение, о котором мы хотим рассказать в этой статье.
Что такое P-значение
P-value или p-значение – одна из ключевых величин, используемых в статистике при тестировании гипотез. Она показывает вероятность получения наблюдаемых результатов при условии, что нулевая гипотеза верна, или вероятность ошибки в случае отклонения нулевой гипотезы.
Этот термин первым упомянул в своих работах К. А. Браунли в 1960 году. Он описал p-уровень значимости как показатель, который находится в обратной зависимости от истинности результатов. Чем выше р-value, тем ниже степень доверия в выборке зависимости между переменными.
Другими словами, в статистике p-значение – это наименьшее значение уровня значимости, при котором полученная проверочная статистика ведет к отказу от основной (нулевой) гипотезы.
Значение p-уровня чаще всего соответствует статистической значимости, равной 0,05. Если значение р меньше 0,05, нулевую гипотезу отклоняют. При этом чем меньше это значение, тем лучше, т. к. растет предполагаемая значимость альтернативной гипотезы и «сила» отвержения нулевой.
Часто p-значение понимают неправильно. Например, если значение р = 0,05, можно сказать о том, что существует 5% вероятности, что результат получен случайно и не соответствует действительности.

Кратко о главном
- Р-значение показывает вероятность того, что наблюдаемая разница в результатах могла быть случайной.
- Значение p применяется как альтернатива выбранным уровням достоверности для тестирования идей или в дополнение к ним.
- Со снижением p-значения повышается статистическая значимость разницы, полученной в ходе исследования.
Статистическая значимость
Эксперимент начинается с формулирования нулевой гипотезы. Она показывает, что два исследуемых явления никаким образом не связаны друг с другом.
Эксперимент проводится с целью выявить или показать какое-либо влияние или тип взаимодействия рассматриваемых явлений. Если в итоге анализа подтверждается нулевая гипотеза, значит, тест провалился.

Чтобы правильно интерпретировать результаты, рассчитывают показатель статистической значимости.
Статистическая значимость – это критерий, с помощью которого можно определить, необходимо ли отвергнуть или принять ту или иную гипотезу.
Перед началом тестирования следует установить порог значимости (альфа). Если значение р меньше альфа, можно говорить о том, что наш результат является статистически значимым. Это говорит о том, что наблюдаемое явление действительно имело место, и нулевую гипотезу нужно отклонить.
Порог значимости альфа устанавливается обычно на уровне 0,05 или 0,01. Выбор значения определяется поставленной задачей.
Порог значимости равен 0,05, а p-значение – 0,02. Т. к. установленное значение альфа больше p-уровня, делаем вывод, что это статистически значимый результат.
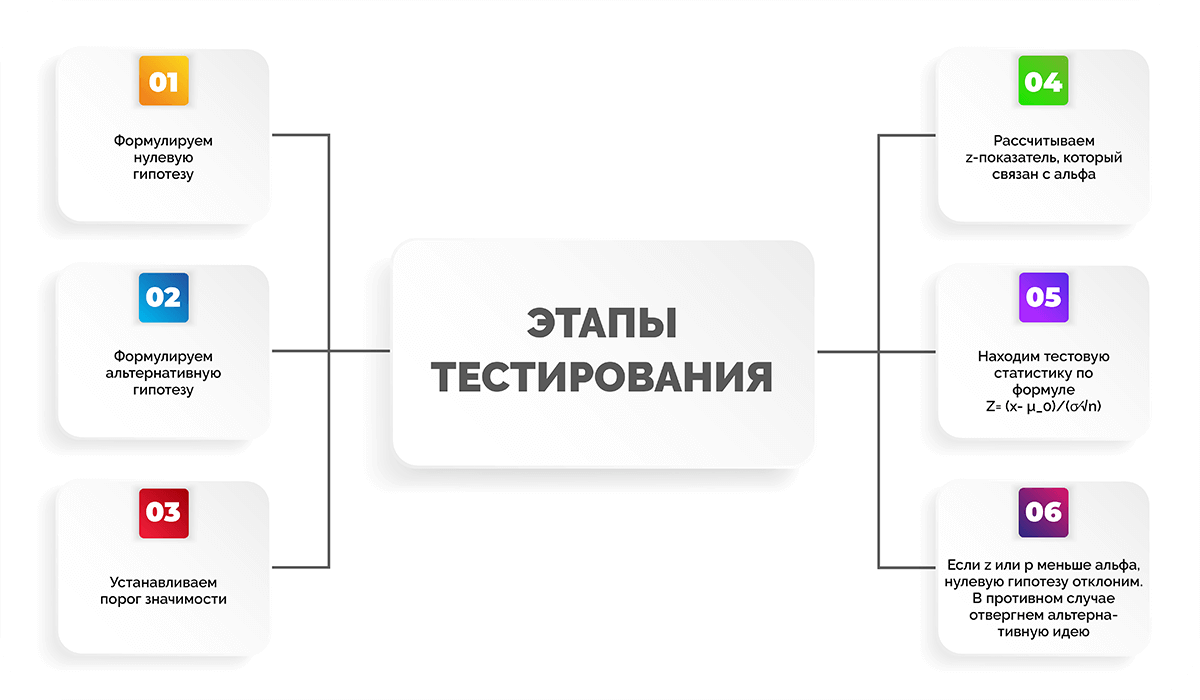
Все тестирование можно разделить на несколько этапов:

- Формулируем нулевую гипотезу.
- Формулируем альтернативную гипотезу.
- Устанавливаем порог значимости.
- Рассчитываем z-показатель, который связан с альфа.
- Находим тестовую статистику по формуле .
- Если z-показатель или p-значение меньше уровня альфа, нулевую гипотезу отклоним. В противном случае отвергнем альтернативную идею.
Если идет речь о явлениях, которые управляются случайными процессами, обычно это приводит к нормальному распределению значений. В этом случае нулевую гипотезу представляют в виде кривой Гаусса, которая отражает распределение ожидаемых наблюдений. Это распределение актуально в случае, если одна переменная в эксперименте не зависит от другой.
Порог вероятности
В основе статистической значимости лежит вероятность получения определенного результата при верности нулевой гипотезы. Чтобы разобрать смысл этого определения, предположим, что в процессе тестирования получили некое число х. Это может быть любая метрика, например, прибыль от продаж, величина конверсии, количество довольных покупателей и т. д.
Используя функцию плотности вероятности, которая связана с нулевой гипотезой, можно выяснить, удастся ли получить число х (или любое другое значение, которое маловероятнее, чем х) с вероятностью менее 5% (p +1,65
Проверка статистических гипотез
Проверка гипотезы – это статистическое исследование, которое проводится, чтобы подтвердить или опровергнуть какую-либо гипотезу (простую или сложную).
Можно предположить, что посадочная страница с красной кнопкой CTA даст больше конверсий, чем текущая версия лендинга с синей. Проверить это можно путем тестирования, в котором будут участвовать нулевая и альтернативная гипотезы.

Нулевая гипотеза – первоначальное условие, при котором нет никакой разницы между текущей и новой версиями лендинга в плане конверсии
Альтернативная гипотеза – подразумевает, что изменение цвета кнопки на странице является причиной роста конверсии.
В статистике применяется рандомизация и нормализация нулевой гипотезы.
Рандомизация нулевой гипотезы – пространственная модель данных, которую мы наблюдаем, является одним из многих вариантов пространственных организаций данных. При этом все другие варианты не будут заметно отличаться от наблюдаемых.
Нормализация нулевой гипотезы подразумевает, что наблюдаемые значения являются одним из многих случайных вариантов выборок. При этом ни пространственное расположение данных, ни их значения не установлены.
Благодаря значению p можно увидеть, насколько нулевая гипотеза правдоподобна с учетом данных выборки. Таким образом, если нулевая гипотеза подтвердится, p-значение будет свидетельствовать об отсутствии увеличения конверсии вследствие изменения цвета кнопки.
Подход p-value к проверке гипотез
Значение р может использоваться для выявления доказательства для отклонения нулевой (первоначальной) гипотезы в ходе эксперимента.
Мы уже упоминали выше о том, что уровень значимости обозначается до начала исследования, чтобы определить, насколько малое значение p нужно получить для опровержения нулевой гипотезы. Однако в разных случаях разные люди могут использовать разные уровни значимости, поэтому при интерпретации итогов двух разных тестирований другими людьми могут возникать трудности. Решить эту проблему помогает p-value.
Рассмотрим пример, в котором в компании провели исследование, в ходе него сравнили доходность двух активов. Тест и анализ проводили два специалиста, которые брали за основу одни и те же самые исходные данные, но использовали разные уровни значимости. Есть вероятность, что эти люди сделают противоположные выводы о различии активов. Предположим, что один специалист для отклонения нулевой гипотезы взял уровень достоверности 90%, а другой – 95%. При этом среднее значение p наблюдаемой разницы между результатами равнялось 0,08, что отвечает уровню достоверности 92%. В таком случае первый специалист выявит значимое различие между двумя доходами, а второй статистически значимой разницы не обнаружит.
Чтобы избежать подобной ситуации, можно сообщить значение p-value эксперимента и дать возможность независимым наблюдателям самостоятельно оценивать статистическую значимость итоговых данных. Данный подход к проверке утверждений стали называть «подход p-value».
Как рассчитать P-value
Чаще всего p-значения определяют с помощью таблиц p-value или специализированного статистического ПО. Также помогает в этом калькулятор на тематических сайтах. Подобные расчеты основываются на известном или предполагаемом распределении вероятностей определенной статистики. Определение среднего значения р зависит от отклонения между выбранным эталонным и тестовым значением. При этом учитывается нормальное распределение вероятностей статистики.
Что касается ручного математического расчета значения р, существуют разные способы, которые рассмотрим далее в статье.
Как рассчитать p-значение, используя тестовую статистику
Распределение тестовой статистики происходит с предполагаемым условием, что верна нулевая гипотеза. Чтобы выразить вероятность того, что статистика эксперимента будет такой же экстремальной, как значение x для выборки, используется кумулятивная функция распределения.
Левосторонний эксперимент:
P-value = cdf (x)Правосторонний эксперимент:
P-value = 1 – cdf (x)Двусторонний эксперимент:
P-value = 2 × мин >Ручной расчет значения p затрудняют распространенные распределения вероятностей, которыми характеризуется проверка гипотез. Для расчета примерных показателей cdf удобнее использовать статистическую таблицу или ПК.
Пошаговый алгоритм расчета p-значения
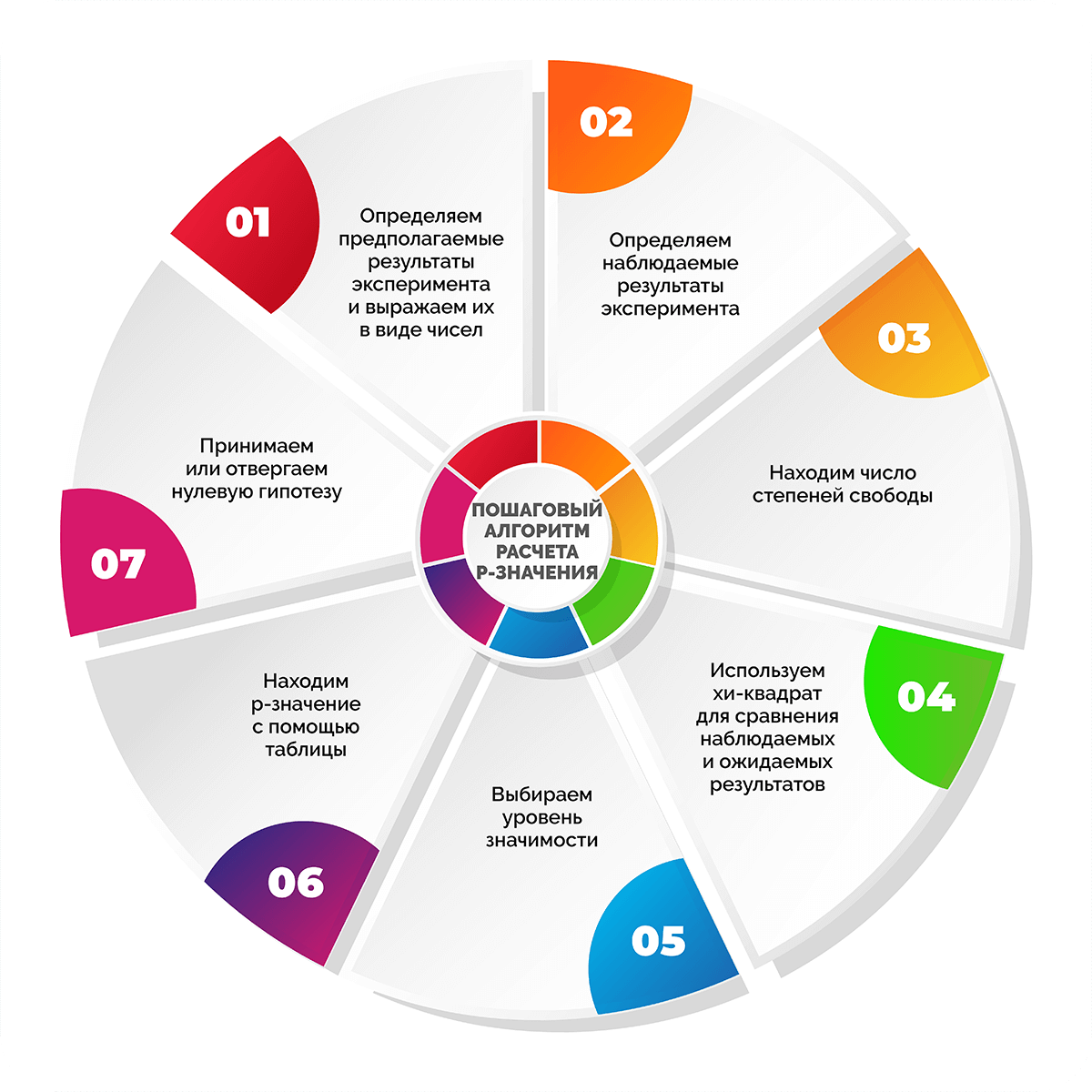
Шаг 1. Определяем предполагаемые результаты эксперимента и выражаем их в виде чисел
Как правило, на начало исследования уже есть видение того, какие числа можно считать приемлемыми. Выводы могут быть основаны на опыте проведения предыдущих экспериментов, наборах достоверных данных или общих сведеньях из научной литературы и других источников.
Опыт работы с лендингами показывает, что посадочные страницы с CTA-кнопкой на первом экране приводят примерно вдвое больше покупателей, чем версии без таких кнопок. Необходимо определить, действительно ли наличие кнопки влияет на посетителей сайта. Для этого будем анализировать конверсии в покупку. Если взять условные 300 конверсий, то предполагается, что 200 из них произойдут благодаря лендингам с CTA-кнопкой, а 100 – сайтам без кнопки при условии, что пользователи требовательны к наличию кнопок.
Шаг 2. Определяем наблюдаемые результаты эксперимента
Теперь нужно провести тест и получить реальные, т. е. наблюдаемые значения, которые таже будут выражаться в числовом формате. Если в экспериментальных условиях реальные цифры не совпадут с ожидаемыми, то будет два варианта – или это обусловлено действиями в ходе эксперимента, или получилось случайно. В данном случае цель определения p-value – понять, действительно ли наблюдаемые значения отличаются от ожидаемых настолько, что нулевая гипотеза не будет опровергнута.
Предположим, что мы выбрали 300 случайных конверсий с наших сайтов, на которых либо была кнопка на первом экране, либо ее не было. Определили, что 220 конверсий произошли благодаря лендингам с кнопкой и 80 – без нее. Результаты отличаются от ожидаемых, которые составляли 200 и 100 соответственно. Теперь предстоит узнать, действительно ли к изменению в значениях привел наш тест (добавление кнопки на первый экран) или это случайное отклонение. Определить это поможет p-значение.
Шаг 3. Находим число степеней свободы
Число степеней свободы показывает, насколько может измениться эксперимент. При этом степень изменяемости зависит от количества исследуемых категорий.
Число степеней свободы = n – 1, где n – количество анализируемых переменных или категорий.
В нашем эксперименте 2 условия и, соответственно, две категории результатов: для лендингов без кнопки на первом экране и для лендингов с ней.
Число степеней свободы = 2 – 1 = 1.
Если бы в эксперименте мы сравнивали посадочные станицы с CTA-кнопкой, без кнопки и с pop-up окном, то получили бы 2 степени свободы и т. д.
Шаг 4. Используем хи-квадрат для сравнения наблюдаемых и ожидаемых результатов
Хи-квадрат (х 2 ) – числовое отражение разницы между наблюдаемыми (фактическими) и ожидаемыми значениями тестирования.

о – наблюдаемое значение;
е – ожидаемое значение.
Подставляем наши цифры в уравнение и учитываем, что нужно подсчитать дважды – для двух видов лендинга.
х 2 = ((220 – 200) 2 /200) + ((80 – 100)2/100) = ((20) 2 /200)) + ((-20) 2 /100) = (400/200) + (400/100) = 2 + 4 = 6.
Шаг 5. Выбираем уровень значимости
Уровень значимости отражает степень уверенности в полученных результатах. Если статистическая значимость низкая, это говорит о низкой вероятности случайного получения экспериментальных результатов.
Для большинства тестов достаточно статистической значимости, равной 0,05 или 5%. При этом будет вероятность 95%, что исследователь получил значимый результат вследствие проведенных мероприятий, а не случайно.
В нашем случае примем статистическую значимость, равную 0,05.
Шаг 6. Находим p-значение с помощью таблицы
Для облегчения расчетов статисты применяют специализированные таблицы. Они довольно простые и позволяют легко найти значение р, зная число степеней свободы и хи-значение. Слева по вертикали располагаются значения числа степеней свободы. Вверху по горизонтали находятся p-значения. По данным таблицы сначала находят нужное число степеней свободы, затем в соответствующем ему ряду выбирают первое значение, которое превышает расчетное значение хи-квадрата. Число в верхней горизонтальной строке будет соответствовать p-значению. При этом нужное значение р находится в диапазоне чисел между найденным и следующим за ним слева.
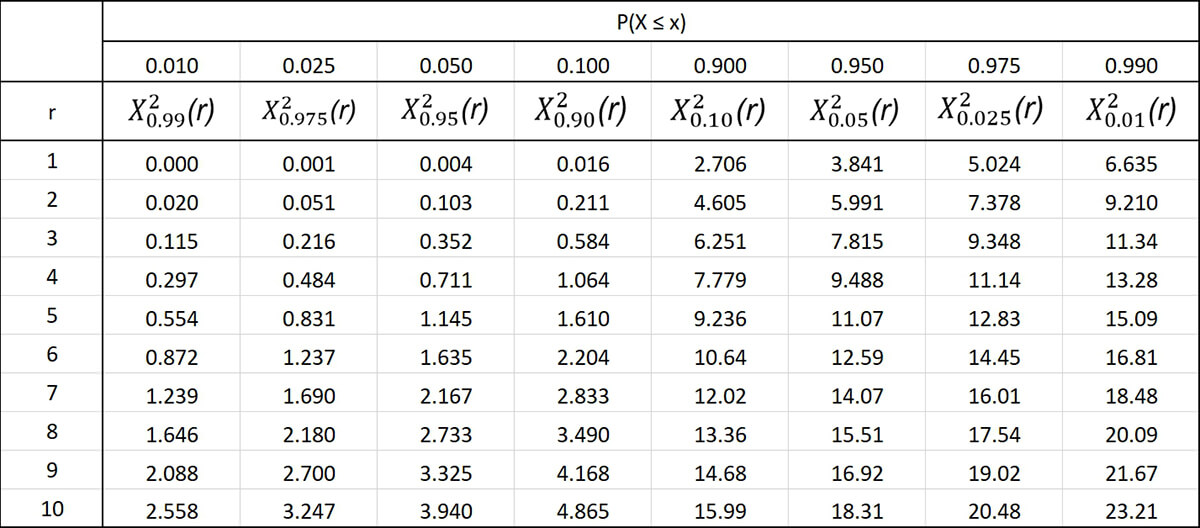
В нашем примере всего одна степень свободы, а хи-квадрат равен 6. Поэтому в таблице выбираем первую строку и движемся по ней слева направо до тех пор, пока не увидим первое значение больше 6 – это число 6,635. Оно соответствует p-значению 0,01, а значит, наше p-значение находится в диапазоне между 0,01 и 0,025.
Шаг 7. Принимаем или отвергаем нулевую гипотезу
Если найденное приблизительное значение p меньше уровня значимости, можно заключить, что вероятна связь между экспериментальными переменными и полученными результатами. В противном случае нельзя утверждать с уверенностью, связаны ли результаты с манипуляцией переменными или стали случайностью.
В нашем эксперименте диапазон значений р 0,01-0,025 определенно меньше установленной статистической значимости 0,05, что позволяет отклонить нулевую гипотезу. А значит, можно сделать вывод, что посадочные страницы с CTA-кнопкой на 1-м экране конвертируют лучше, чем аналогичные версии без такой кнопки. Вероятность того, что рост конверсий на лендингах с кнопкой является случайностью, составляет не больше 1-2,5%.
Как интерпретировать P-значение
P-уровень тесно связан с уровнем статистической значимости. Последний таже определяет исход эксперимента.
- Если p-значение меньше уровня значимости, то нулевую гипотезу можно смело отклонить и считать истинной альтернативную гипотезу.
- Если p-значение больше уровня значимости, это означает, что в ходе эксперимента выявили недостаточно оснований для отклонения нулевой гипотезы.
Отвержение нулевой гипотезы говорит о том, что в процессе исследования была обнаружена закономерная связь между тестируемыми переменными.
- вероятность того, что в ходе исследования наблюдения были случайными. То есть, если p = 0,05, есть 5% вероятности того, что наблюдаемое явление случайно и 95% вероятности того, что результат является следствием созданных условий;
- вероятность того, что будет сделан неверный вывод о взаимосвязи переменных. Если р = 0,05, то на каждые 100 экспериментов, где наблюдалась взаимосвязь, 95 их них действительно была, а 5 – нет.
Что нужно помнить о P-значениях
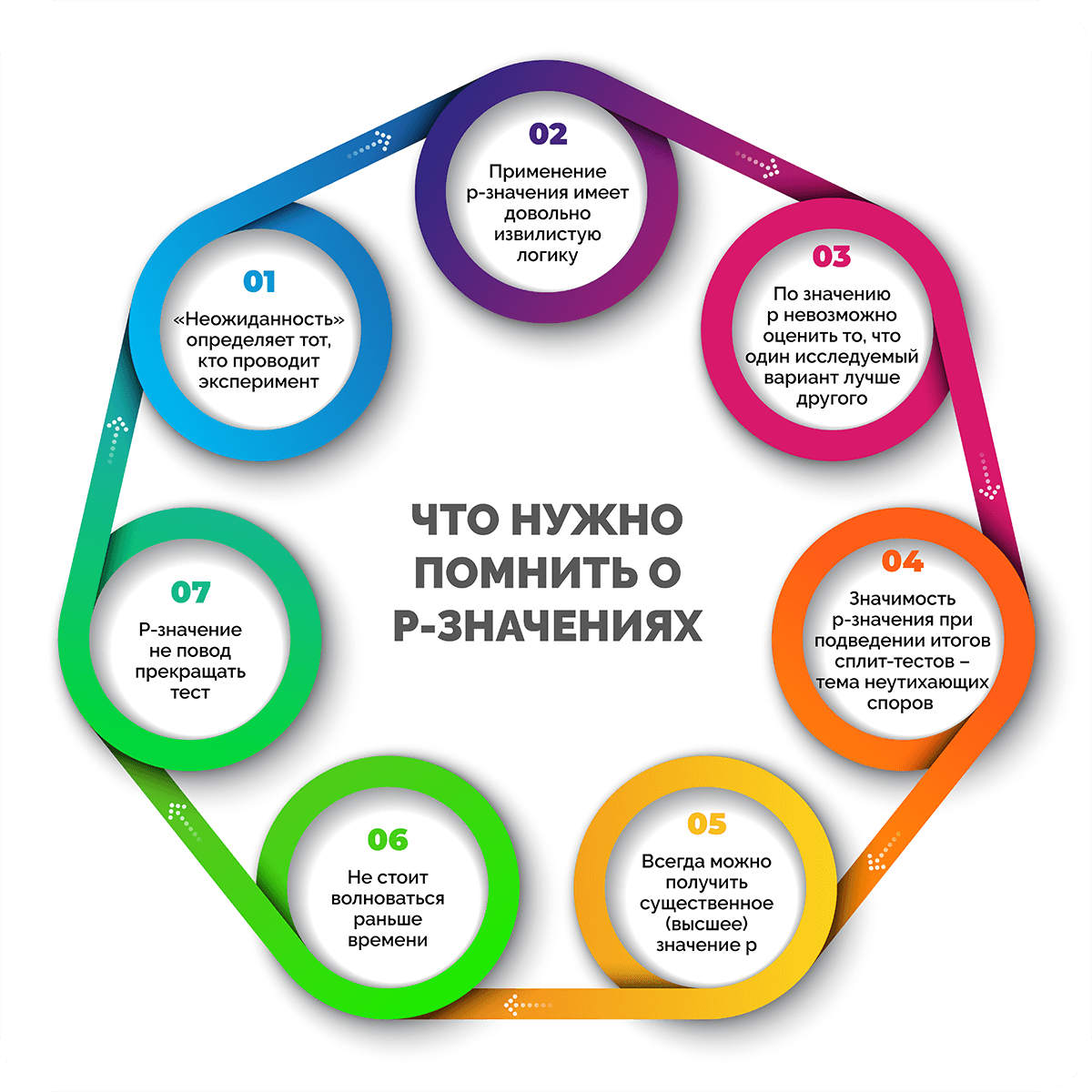
- «Неожиданность» определяет тот, кто проводит эксперимент. Подводит итоги теста по факту тот, кто его проводит. Чем выше значение р, тем чаще вы будете получать неожиданные результаты.
- Применение p-значения имеет довольно извилистую логику. Чтобы оценить аргументы в пользу отклонения нулевой гипотезы, необходимо изначально считать, что она верна. Именно это является причиной путаницы.
- По значению p невозможно оценить вероятность того, что один исследуемый вариант лучше другого. Также по этому показателю нельзя понять, какая вероятность того, что предпочтение одного варианта другому ошибочно. На самом деле, p-значение показывает лишь вероятность того, что при верности нулевой гипотезы удастся вычислить результат, отличный от нуля.
- Значимость p-значения при подведении итогов сплит-тестов – тема неутихающих споров в научном сообществе. Большинство маркетологов остаются приверженцами классической проверки на статистическую значимость и отстаивают ее как «золотой стандарт». При этом специалисты по статистике приводят аргументы в пользу других методов проверки, что провоцирует жаркие дебаты.
- Всегда можно получить существенное (высшее) значение p. Есть типичная ошибка, которая зависит с одной стороны от объема выборки, с другой – от изменений генеральной совокупности данных. Если во втором случае повлиять на изменения никак нельзя, то собирать и накапливать данные ничто не мешает. Но есть ли польза от такого количества сведений? Сам факт того, что у полученного параметра высокое p-значение, практического значения не имеет.
- Не стоит волноваться раньше времени. В первую очередь нужно собрать данные, которые помогут сформировать рабочую идею. Всегда трудно делать выбор между вариантами, которые почти не отличаются друг от друга. Если выделить предпочтительный вариант проблематично из-за похожих результатов, можно просто выбрать один из них и не беспокоиться о том, правильный ли это выбор.
- P-значение не повод прекращать тест. Для получения достоверных результатов, которые позволят интерпретировать p-значение, необходимо вычислить размер выборки, затем провести эксперимент. В процессе тестирования предстоит выбрать время, когда пора его закончить. При этом оно не должно быть связано с достижением статистической значимости или высокого показателя p-значения. Главное – получить реальные результаты в конце теста, например, обеспечить рост прибыли, оптимизировать конверсию и т. д.
Примеры интерпретации P-значений
На нескольких примерах рассмотрим, как правильно интерпретировать p-значения при проверке разных идей.
По мнению интернет-провайдера, 90% пользователей довольны качеством предоставляемых услуг. Чтобы это проверить, была собрана простая выборка, куда вошли 500 случайных абонентов. 85% дали утвердительный ответ на вопрос об удовлетворенности услугами провайдера. По данным выборки удалось вычислить p-значение, равное 0,018.
Если выдвинуть гипотезу о том, что 90% пользователей действительно довольны обслуживанием провайдера, получим реальную наблюдаемую разницу или более экстремальную разницу, которая составит 1,8% потребителей услуг вследствие ошибки случайной выборки.
Ресторан вводит услугу доставки еды и утверждает, что время доставки составляет около 30 минут или меньше. Однако есть мнение, что реальный срок доставки превышает заявленное время. Для проверки этих вариантов были отобраны случайные заказы еды с доставкой и проведены расчеты. По результатам выяснили, что среднее время доставки составляет 40 минут (больше на 10 минут, чем заявляет ресторан), а p-значение равно 0,03.
Результаты показывают, что в случае, когда нулевая гипотеза верна, т. е. доставка еды занимает 30 минут или меньше, есть вероятность 3%, что среднее время доставки будет как минимум на 10 минут больше из-за эффекта случайности.
Отдел маркетинга разрабатывает новый скрипт продаж для менеджеров. Предполагается, что с его помощью компания будет продавать минимум на 30% больше, чем со старым скриптом. Чтобы это проверить, собирается простая случайная выборка из 100 контактов с клиентами по новому скрипту и 100 – по старому. В результате эксперимента новый скрипт привел 60 покупателей, а старый – 45. Вычислили среднее значение p, равное 0,011.
Если взять за основу мнение, что новый скрипт приводит столько же клиентов, сколько и старый, или меньше, будет получена крайняя разница в 1,1% тестирований вследствие случайной ошибки выборки.
Часто задаваемые вопросы
P-значение – вероятность того, что исследуемая статистика удовлетворит конкретным условиям. Поскольку вероятности отрицательными не бывают, отрицательного значения p тоже быть не может.
Если p-значение высокое, это свидетельствует о том, что статистика эксперимента для другой выборки будет иметь столь же экстремальное значение, как и в тестируемой выборке. При высоком p-значении отвергнуть нулевую гипотезу нельзя.
Если получено низкое p-значение, это значит, что вероятность получить такое же критическое значение, как и наблюдаемое в текущей выборке, в тестовой статистике для другой выборки окажется очень низкой. При низком p-значении нулевую гипотезу отвергают и принимают альтернативную.
Некоторые считают, что p-значения показывают вероятность совершить ошибку при отклонении истинной нулевой гипотезы (ошибка первого типа) – это заблуждение. P-значения не свидетельствуют о частоте вероятных ошибок по двум причинам:
- При расчете p-значения в основе утверждение, что верна нулевая гипотеза, а разница в итоговых данных обусловлена случайностью. То есть величина p-значения не отражает вероятность того, что ноль будет ложным или истинным, т. к. с учетом изначального предположения он полностью верен.
- Несмотря на то, что при низком p-значении при условии истинности нулевого значения выборочные данные маловероятны, p-значение все еще не может четко показать, какой из вариантов имеет большую вероятность стать истиной: когда нуль действительно является ложным или когда нуль является верным, но выборка нечеткая.
Заключение
Несмотря на то, что при интерпретации результатов исследований часто допускают ошибки, неправильно используя статистическую значимость, она продолжает оставаться важным методом в экспериментах. P-значение или p-value является одной из обязательных составляющих при оценке результатов тестирования. Именно этот показатель дает возможность понять, с какой вероятностью полученные итоги удовлетворяют определенным значениям.
Как посчитать величину P или значение вероятности
wikiHow работает по принципу вики, а это значит, что многие наши статьи написаны несколькими авторами. При создании этой статьи над ее редактированием и улучшением работали, в том числе анонимно, 16 человек(а).
Количество просмотров этой статьи: 122 057.
В этой статье:
P-значение — это статистическая величина, которая помогает ученым определить, корректны ли их гипотезы. P-значения используются для определения того, подпадают ли результаты эксперимента в диапазон значений, нормальный для наблюдаемой величины. Обычно если P-значение для набора данных меньше, чем заранее определенное число (например 0,05), то ученые должны отклонить «нулевую гипотезу» своего эксперимента. Другими словами, они сделают вывод, что переменные в их эксперименте не оказывают достаточного эффекта на результаты. В настоящее время p-значения обычно можно найти в справочнике, если сначала посчитать значение хи-квадрат.

- Пример: допустим, более ранние исследования показали, что в вашей стране владельцы красных машин чаще получают штрафы за превышение скорости, чем владельцы синих. Например, средние результаты показывают предпочтение 2:1 красных машин перед синими. Наша задача — определить, относится ли полиция точно так же предвзято к цвету машин в вашем городе. Для этого мы будем анализировать штрафы, выданные за превышение скорости. Если мы возьмем случайный набор из 150 штрафов за превышение скорости, выданных либо владельцам красных, либо синих автомобилей, мы ожидаем, что 100 штрафов будет выписано владельцам красных автомобилей, а 50 — владельцам синих, если полиция в нашем городе так же предвзято относится к цвету машин, как это наблюдается по всей стране.

- Пример: допустим, в нашем городе мы случайно выбрали 150 штрафов за превышение скорости, которые были выданы либо владельцам красных, либо владельцам синих автомобилей. Мы определили, что 90 штрафов были выписаны владельцам красных автомобилей, и 60 — владельцам синих. Это отличается от ожидаемых результатов, которые равны 100 и 50, соответственно. Действительно ли наш эксперимент (в данном случае изменение источника данных с государственного уровня на городской) привел к данному изменению в результатах, или наша городская полиция относится к автомобилистам предвзято точно так же, как и в среднем по стране, а мы видим просто случайное отклонение? P-значение поможет нам это определить.

- Пример: в нашем эксперименте две категории результатов: одна категория для владельцев красных машин и другая — для владельцев синих машин. Поэтому в нашем эксперименте у нас 2-1 = 1 степень свободы. Если бы мы сравнивали красные, синие и зеленые машины, у нас было бы 2 степени свободы и так далее.

- Заметьте, что данное уравнение включает оператор суммирования Σ (сигма). Другими словами, вам необходимо подсчитать ((|o-e|-.05) 2 /e) для каждого возможного результата и сложить полученные числа, чтобы получить значение критерия хи-квадрат. В нашем примере у нас два возможных результата — либо машина, получившая штраф красная, либо синяя. Поэтому мы должны посчитать ((o-e) 2 /e) дважды — один раз для красных машин и один раз для синих машин.
- Пример: давайте подставим наши ожидаемые и наблюдаемые значения в уравнение x 2 = Σ((o-e) 2 /e). Помните, что из-за оператора суммирования нам необходимо посчитать ((o-e) 2 /e) дважды — один раз для красных автомобилей и один раз — для синих. Мы выполним эту работу следующим образом:
- x 2 = ((90-100) 2 /100) + (60-50) 2 /50)
- x 2 = ((-10) 2 /100) + (10) 2 /50)
- x 2 = (100/100) + (100/50) = 1 + 2 = 3 .

- По соглашению, ученые обычно устанавливают уровень значимости своих экспериментов равным 0,05, или 5 %. [2] X Источник информации Это означает, что экспериментальные результаты, которые соответствуют такому критерию значимости, только с вероятностью 5 % могли получиться чисто случайно. Другими словами, существует 95 % вероятность, что результаты были вызваны тем, как ученый манипулировал экспериментальными переменными, а не случайно. Для большинства экспериментов 95 % уверенности наличия связи между двумя переменными достаточно, чтобы считать, что они «действительно» связаны друг с другом.
- Пример: для нашего примера с красными и синими машинами, давайте последуем соглашению между учеными и установим уровень значимости в 0.05.

- Таблицы с распределением хи-квадрат можно получить из множества источников — их можно просто найти онлайн, либо посмотреть в научных книгах или книгах по статистике. Если у вас нет под рукой таких книг, используйте картинку выше или какую-нибудь таблицу онлайн, которую можно просматривать бесплатно, например на сайте medcalc.org. Она расположена здесь.
- Пример: наше значение критерия хи-квадрат было равно 3. Поэтому давайте используем таблицу распределения хи-квадрат на изображении выше, чтобы найти приблизительное p-значение. Так как мы знаем, что в нашем эксперименте всего 1 степень свободы, выберем самую первую строку. Идем слева направо по данной строке, пока не встретим значение, большее 3, нашего значения критерия хи-квадрат. Первое, которое мы находим, это 3,84. Смотрим вверх нашего столбца и видим, что соответствующее p-значение равно 0,05. Это означает, что наше p-значение между 0,05 и 0,1 (следующее p-значение в таблице по возрастанию).

- Пример: наше p-значение находится между 0,05 и 0,1. Это явно не меньше, чем 0,05, поэтому, к сожалению, мы не можем отклонить нашу нулевую гипотезу. Это означает, что мы не достигли минимум 95 % вероятности того, чтобы сказать, что полиция в нашем городе выдает штрафы владельцам красных и синих автомобилей с такой вероятностью, которая достаточно сильно отличается от средней по стране.
- Другими словами, существует 5–10 % шанс, что наблюдаемые нами результаты — это не последствия смены места (анализа города, а не всей страны), а просто случайность. Так как заявленная нами точность не должна превышать 5 %, мы не можем сказать с уверенностью, что полиция нашего города менее предвзято относится к владельцам красных автомобилей — существует небольшая (но статистически значимая) вероятность, что это не так.
Как посчитать статистическую значимость на пальцах
Бывает, нужно понять значима ли разница в аб эксперименте, но посчитать ее на специальном калькуляторе несподручно. Я разобрался и нашел способ считать статзначимость в прямом смысле на пальцах.
Подписывайтесь на канал, чтобы не пропустить клевые лайфхаки и истории про пет-проекты.
Итак, есть данные эксперимента по дням или по часам для контрольной и экспериментальной групп.
Ключевой вопрос: экспериментальная группа действительно идет выше, или это случайность?
Чтобы понять это, делаем следующее:
- Выкидываем дни, когда данные в эксперименте и контроле совпали. Остается 12 дней, потому что на четвертый день количество продаж совпало.
- Считаем сколько дней экспериментальная группа отклонялась в нетипичную сторону. В нашем случае было 2 дня — восьмой и девятый — когда эксперимент показал себя хуже контроля. В остальные дни он шел лучше.
- Из количества дней эксперимента вычитаем 6 и делим на 3 с округлением вниз. Столько нетипичных отклонений можно допустить, но все равно достоверно считать, что разница значима. В нашем случае (12-6)/3 = 2. То есть для 12 дней эксперимента результат значим, если отклонений два или меньше. В этом эксперименте у нас только два отклонения — это значит, что эксперимент идет значимо выше контроля.
Приятная особенность этого критерия — его можно применять к любым метрикам: и к конверсиям, и к уникам, и к просто абсолютным величинам, например деньгам. Вместо дней можно брать часы или недели.
Если критерий говорит, что результат значим — этому можно доверять. Если говорит, что не значим, но субъективно кажется, что должен быть значим, то воспользуйтесь другими более мощными критериями.
У критерия есть ограничение: если эксперимент длился 5 дней или меньше, то критерий всегда скажет, что результат не значим. Но стоит ли оценивать эксперименты по пяти дням — большой вопрос.
Как это работает
Я использовал симметричный критерий знаков — он универсальный и прост в расчете. Для него есть таблица значений: при каком количестве данных сколько можно допустить нетипичных отклонений. Я приблизил эту таблицу формулой (n-6)/3. На графике видно, что формула достаточно точно повторяет данные из таблицы. Формула иногда разрешает чуть меньшее количество отклонений — это значит, что мы получили чуть более осторожный критерий.