Шина процесса и шина станции что это
КРАТКОЕ СОДЕРЖАНИЕ
Оцифровка величин тока и напряжения, поступающих от измерительных трансформаторов с технологией NCIT (нетрадиционные измерительные трансформаторы) или от обычных измерительных трансформаторов, преобразованных в цифровую форму так называемыми автономными объединяющими устройствами (SAMU), и простота доступа к этим данным, через цифровой стандартизированный интерфейс, со стороны любых электронных устройств, таких, как средства защиты, компьютерные системы, представляют собой главные преимущества этой технологии. Предполагается внедрение новых функциональных возможностей, например: интеллектуальный мониторинг, функции защиты на базе программных модулей, реализованных в рамках стандартных платформ аппаратных средств, и новые распределенные функции на компьютерах присоединения. Кроме того, интеллектуальный контроль всей системы NCIT предотвращает возможность возникновения существенных отказов мерами предупредительного техобслуживания, исключает несвоевременные ремонтные отключения и обеспечивает надежное функционирование подстанций посредством использования интеллектуального резервирования, например, такого, как протокол параллельного резервирования PRP (Parallel Redundancy Protocol).

Совместимость обычных измерительных трансформаторов и всех трансформаторов с технологиями NCIT, а также оборудования различных поставщиков может быть достигнута в результате использования стандартного протокола: «Шина процесса» (Process bus), т.е. МЭК 61850-9-2 со специальной рекомендацией МЭК 61850-9-2LE.
ВВЕДЕНИЕ
Международный стандарт МЭК 61850 для систем передачи данных открывает новую эру в области совершенствования подстанций. Он охватывает не только проектирование систем релейной защиты, контроля и управления подстанций, но и разработку вторичных цепей подстанций. Высокоскоростная связь между равноправными устройствами с использованием GOOSE-сообщений и дискретизированных аналоговых значений (Sampled Analogue Values) позволяет усовершенствовать распределенные приложения, базирующиеся на передаче значений тока и напряжения между устройствами, подключенными к сети технологического процесса и к локальной сети подстанции.
За несколько прошедших лет тенденции развития рынка в направлении реализации требований МЭК 61850 стали одинаково очевидными как для поставщиков, так и для заказчиков. Значительная доля этого интереса сконцентрирована на процессе миграции от решений реализации шин подстанций, продиктованных интересами изготовителей, в направлении систем автоматизации подстанций, которые характеризуются полной интеграцией интеллектуальных устройств IED, таких, как терминалы релейной защиты, в соответствии с требованиями принятого международного стандарта.
Этот подход был сосредоточен главным образом на «Шине подстанции» стандарта МЭК 61850-8-1 и реализовывался путем моделирования и развития по аналогии с традиционными подходами систем SCADA.
«Шина процесса» (Process bus), определенная стандартом МЭК 61850- 9-2, остается в существенной степени неисследованной до настоящего времени.
МЭК 61850-9-2 представляет собой часть стандарта, который внедряет в практику технологию нетрадиционных измерительных трансформаторов (NCIT), устраняя несовершенства и ограничения традиционных ТТ и ТН с их обмотками на стальных сердечниках.

«ШИНА ПРОЦЕССА» (PROCESS BUS)
«Шина процесса», определенная стандартом МЭК 61850-9-2, позволяет использовать цифровую связь между электронными трансформаторами тока/напряжения или объединяющими устройствами и устройствами присоединения, такими, как реле защиты, контроллерами или счетчиками присоединения. Это канал связи 4 на рисунке 1, заимствованном из стандарта МЭК 61850.

Фактически все технологии DIT используют электронные терминалы, поэтому они не позволяют применять традиционные аналоговые выходы измерительных трансформаторов по причине повышенной потребности в электропитании для усилителей.
В 1998 году возникла идея передачи «мгновенных значений измерений» (Sampled Values) по цифровым сетям передачи данных. Описание первой рекомендации было дано в стандарте МЭК 60044-8.
Компаниями Alstom и RTE был проведен успешный эксперимент по использованию оптического трансформатора тока на подстанции «Вилмулин» 400 кВ.
В 2002 году несколькими основными производителями был запущен проект «Совместимость» и произведен выбор протокола. Им стал протокол «Шина процесса» (Process bus). В документе под названием LE (Light Edition, облегченная редакция), входящем в состав Руководства, зафиксирован основной параметр протокола. Первая успешная демонстрация проведена на CIGRE в 2004 году.
В 2008 году рабочая группа TC38 начала разработку редакции нового стандарта МЭК 61869-9-2 для электронных измерительных трансформаторов. Предложенный цифровой интерфейс основывается на рекомендациях МЭК 61850-9-2 LE с дополнительными характеристиками. Этот документ будет издан в 2011 г.
Предложенная архитектура
Сохранение существующей архитектуры подстанции с резервированием сети Ethernet (PRP или HSR):
• защита (80 выборок/цикл) — основной канал 1;
• защита (80 выборок/цикл) — основной канал 2 (резерв);
• регистрация возмущений (256 выборок/цикл — полоса пропускания 10 кГц);
• учет (80 выборок/цикл) — коммерческий учет или учет тарифов;
• оценка качества электроэнергии (256 выборок/ цикл – анализ гармоник — 100 e).
Объединяющие устройства для мгновенных значений измерений:
• N-MU или P-MU для DIT (объединяющее устройство для подключения к первичным преобразователям, разделенным или в виде единого устройства, предназначенное для работы с датчиками различных типов);
• A-MU для CIT (объединяющее устройство для подключения к обычным измерительным трансформаторам с аналоговыми входами).
Объединяющее устройство для контроллеров выключателей:
• совместимость;
• CB-MU для выключателей и разъединителей (ввод/вывод, подача команды на отключение через GOOSE-сообщения);
• CB-MUM для выключателей (контроль и подача команды на отключение выключателя; резервирование).
Две независимые сети: 9–2 для передачи мгновенных значений измерений и 8–1 для GOOSE:
• «Шина процесса» (сеть Ethernet, в настоящее время 100 BaseFx) со стандартом МЭК 61850-9.2 LE для мгновенных значений измерений SV, которая в скором времени станет глобальным стандартным интерфейсом МЭК 61869-9-2, для измерений тока и напряжения;
• «Шина процесса» (сеть Ethernet, в настоящее время 100 BaseFx) со стандартом МЭК 61850-8.1 служба GOOSE-сообщений для положения выключателя-разъединителя (SW), положения и отключений автоматического выключателя.

ПРЕИМУЩЕСТВА ИНТЕГРАЦИИ «ШИНЫ ПРОЦЕССА»
Оцифровка величин тока и напряжения
Мгновенные значения, полученные от нетрадиционных или традиционных измерительных трансформаторов, оцифрованные так называемыми автономными объединяющими устройствами (SAMU), обеспечивают связь в реальном масштабе времени, что, в свою очередь, позволяет осуществить простой доступ к этим данным со всех прочих устройств подстанции (средств релейной защиты, компьютерных систем, и др.) путем реализации технологии Ethernet. Это является одним из главных преимуществ!
Совместимость
Достигается совместимость технологий традиционных и нетрадиционных измерительных трансформаторов, а также согласованность оборудования всех поставщиков со стандартным протоколом. Это обеспечивает значительно большую гибкость при проведении реконструкций подстанций генерирующих предприятий. Этот пункт абсолютно обязателен и противопоставляется «частным» решениям.
Простота эксплуатации
• оптическая технология Ethernet 100 BaseFX позволяет радикально упростить кабельную систему;
• оптический кабель имеет естественную изоляцию ЭМИ, что способствует снижению затрат на проектирование, инжиниринг и повышает общую надежность системы;
• используемые технологиями DIT электронные компоненты обеспечивают повышение степени промышленной стандартизации путем уменьшения разнообразия моделей ТТ/ТН по причине осуществимости повторной калибровки с помощью электронных установок.
Ввод в эксплуатацию, испытания на объекте, простота конфигурирования архитектуры позволяют добиться снижения численности персонала.
Ожидаемые новые функциональные возможности
Ниже приводится неполный перечень функциональных возможностей:
• интеграция всех функций защиты, управления, измерений и контроля в пределах подстанции на основе программных модулей, легко переносимых на любые стандартные аппаратные платформы;
• обеспечение средств для высокоскоростных приложений подстанции (новые функции защиты, блокировки, телеотключения);
• обеспечение новых распределенных функций для контроллеров присоединения или упрощенных устройств защиты (например, контроль синхронизма, регистрация переходных процессов, анализ гармоник и т.д.);
• возможность упрощенной повторной калибровки ТТ/ТН при работе с различными номиналами точек измерений.

Повышение степени готовности-надежности
• постоянный интеллектуальный контроль в оперативном режиме параметров трансформаторов тока, напряжения и автоматических выключателей, повышающий надежность эксплуатации;
• предотвращение серьезных аварий путем предупредительного техобслуживания;
• исключение несвоевременных ремонтных отключений.
Все это вносит вклад в обеспечение безопасности подстанций в результате применения интеллектуального резервирования, например, протокола параллельного резервирования PRP (Parallel Redundancy Protocol) (дублированная сеть передачи данных) или качественно интегрированного резервирования высокой степени готовности HSR (High-availability Seamless Redundancy).
Все эти преимущества обеспечивают ценный вклад в повышение надежности и готовности современных высоковольтных сетей и являются одной из важнейших задач концепции Smart Grid.
События, шины и интеграция данных в непростом мире микросервисов

Добрый день, я Валентин Гогичашвили. Все слайды я сделал латиницей, надеюсь не будет проблем. Я из Zalando.
Что такое Zalando? Наверное, вы знаете Lamoda, Zalando был папой Lamoda своё время. Чтобы понять, что такое Zalando, нужно представить Lamoda и увеличить в несколько раз.
Zalando – это магазин шмоток, мы начали продавать обувь, очень хорошую между прочим. Начали расширяться всё больше и больше. Снаружи сайт выглядит очень просто. За 6 лет что я работаю в Zalando и за 8 лет существования — эта компания была одной из самых быстрорастущих в Европе в какое-то время. Шесть лет назад, когда я пришел в Zalando, она росла где-то 100%.
Когда я начинал 6 лет назад, это был маленький стартап, я пришёл довольно поздно, там уже было 40 человек. Мы начинали в Берлине, за эти 6 лет мы расширили Zalando Technology на много городов, включая Хельсинки и Дублин. В Дублине сидят data-science’ы, в Хельсинки сидят mobile developer’ы.
Zalando Technology растёт. На данный момент мы нанимаем в районе 50 человек в месяц, это страшное дело. Почему? Потому что мы хотим построить самую крутую fashion-платформу в мире. Очень амбициозно, посмотрим, что получится.
Хочу немножко вернуться в историю и показать вам старый мир, в котором вы, скорее всего, в какой-то момент вашей карьеры определенно были.
Zalando начинался как маленький сервис у которого было 3 уровня: web applicaton, backend и база данных. Мы использовали Magento. К тому моменту, когда меня позвали в Zalando, мы были самыми большими пользователями Magento в мире. У нас были огромные головные боли с MySQL.
Мы начали проект REBOOT. Я и пришел на этот проект 6 лет назад.
Что мы сделали?
Мы переписали все на Java, потому что мы знали Java. Мы поставили везде PostgreSQL, потому что я знал PostgreSQL. Ну и Python – это дело техники. Практически любой нормальный человек меня поддержит, что Python для tooling’a — это единственное правильное решение (люди из мира Perl, не убивайте меня). Python это хорошая шутка для написания tooling.
У нас начала развиваться такая схема:
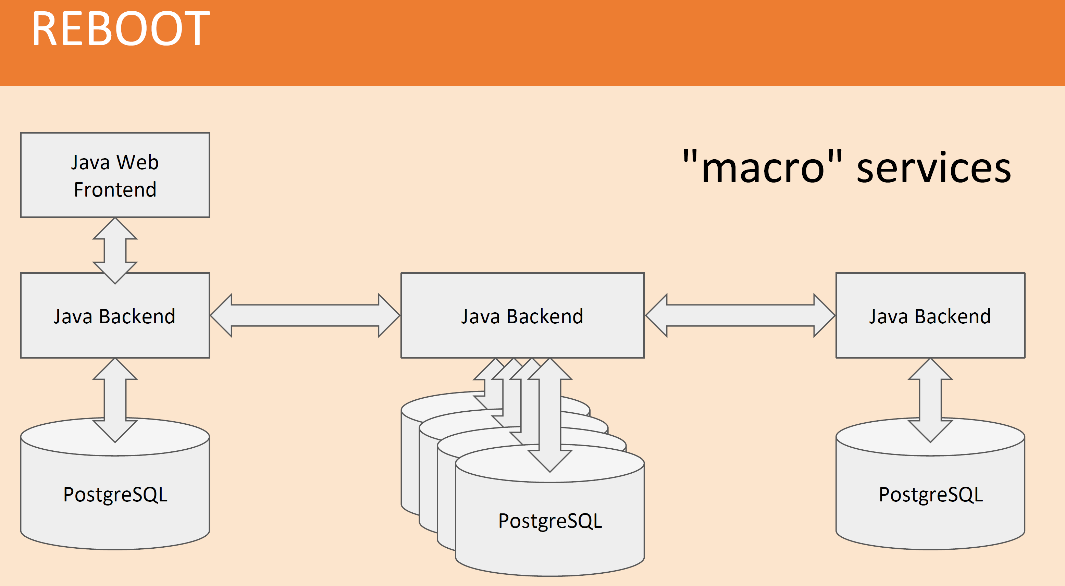
У нас была система macro services. Java Backend, PostgreSQL storage c PostgreSQL шардингом. Я два года назад на этой же конференции рассказывал о том, как мы делаем PostgreSQL-шардинги, как мы управляем схемами, как мы выкатываем версии без downtime, было очень интересно.
Как я сказал, Java мы все знали. SOAP использовался для объединения macro-сервисов друг с другом. PostgreSQL давал нам возможность иметь очень чистые данные. У нас была схема, чистые данные, транзакции и хранимые процедуры, котором мы научили всех java-developer’ов или тех, кто еще остались из PHP-мира, которых мы научили Java и хранимым процедурам.
Один хинт: если вы находитесь в режиме меньше 15 миллионов пользователей в месяц, то вы можете использовать систему Java SProc Wrapper для автоматического шардирования PostgreSQL из Java. Очень интересная штука, которая PostgreSQL в RSP-систему, по существу.
Всё было хорошо, мы написали и переписали всё. Мы сперва купили систему управления нашими складами, а потом всё переписали. Потому что мы должны были двигаться намного быстрее чем те люди, у которых мы купили систему могли это сделать.
Всё прекрасно работало пока не началась проблема с кадрами. Наш прекрасный мир начал рушиться на глазах. Система стандартизации, ее уровень, который мы ввели на уровне Java, SOAP начал крошиться. Люди начали жаловаться и уходить или просто не приходить.
Мы им говорили: вы должны писать на Java, если вы уйдете, что мы будем делать? Если вы напишите что-то на Haskell или на Clojure и уйдете что мы будем делать? А они нам отвечали fuck you.
Мы решили подойти к делу серьезно. Мы решили перестроить не только архитектуру, но и всю организацию. Мы начали процесс перестройки организации, которая не видела немецкая индустрия, в которой мы сказали, что мы разрушаем полностью всё, что у нас было. Это была организация в которой было в районе 900 человек, мы разрушаем иерархическую структуру в том виде в которой она была. Мы объявляем Radical Agility.
Что это значит?
Мы объявляем, что у нас есть команды, которые автономны, которые двигаются вперед осмысленно. Конечно же мы хотим, чтобы люди, которые занимались делом, они делали это дело с мастерством.
Автономные команды.
Они могут выбрать своё собственное технологический стэк. Если команда решила, что они будет писать на Haskell или Clojure, то пусть так и будет. Но за это надо платить. Команды должны поддерживать сервисы, которые они написали сами, просыпаться ночью сами. Включая выбор персистент стэка. Мы вам научили PostgreSQL, если вы хотите выбрать MongoDB, а нет стоп, MongoDB у нас заблокирован. У нас есть радар технологий в котором мы проводим помесячные опросы и технологии, которые считаем опасными, ставим на красный сектор. Это означает, что команда могут выбирать эти технологии, но они пенять полностью на себя, если что-то пойдет не так.
Мы сказали, что команды будут изолированы своими AWS-аккаунтами. До этого мы были в своих собственных дата центрах, выбрав AWS, мы пошли на сделку с дьяволом. Мы сказали, мы знаем, что это будет стоить дороже, но мы будем двигаться быстрее. У нас не будет ситуаций как до этого, в собственных дата центрах: для того, чтобы заказать один жесткий диск, требовалось 6 недель. Это было невыносимо и невозможно. Мы не могли двигаться вперед.
Очень многие люди считают, что автономия — это анархия. Автономия — это не анархия. С автономией приходит очень много ответственности, особенно для Zalando, которая publicly traded company. Мы на бирже и как в любую publicly traded company к нам приходят аудиторы и они проверяют, как работают наши системы. Мы должны были создать какую-то структуру, которая позволит нашим developer’ам работать с AWS, но всё же оставаться способными отвечать на вопросы аудиторов уровня: «Почему у вас это IP-адрес в публичном доступе без идентификаций?»
Получилась вот такая система:

Мы хотели сделать её максимально простой, она действительно простая. Но все ругаются, когда видят её.
Если вы уходите в AWS, напоминание вам, с этой быстротой и с открытостью, и если вы выбираете идею с микросервисами или публичными сервисами, то за это может быть придётся платить. В том числе если вы хотите сделать систему, которая безопасна, которая отвечает на вопросы, которые могут задавать наши аудиторы.
Конечно же мы сказали, что для того чтобы поддерживать разнородный стэк технологий мы поднимаем уровень стандартизации с Java и PostgreSQL на более высокий уровень. Мы поднимаем уровень стандартизации на уровень REST APIs.
Что это значит? Я отмечал это на предыдущем докладе о том, что нам нужна система описания API. Описание системы того как микросервисы общаются друг с другом. Нам нужен порядок. На каком-то уровне нам нужно стандартизироваться. Мы объявили о том, что у нас будет система API first. И что каждый сервис перед тем как его начнут писать, команда должна прийти в API гильдию и уговорить их принять API в состав утвержденных API. Мы написали REST API guidelines, очень интересные. На них даже ссылались в некоторых ресурсах. API first библиотеки, которые позволяют использовать Swagger (OpenAPI) в качестве руторов для сервера. Например, connection — это рутор для flask’a в Python, а play-swagger — это рутор для play-системы в Scala. Для Clojure есть такой же рутор, это очень удобно. Вы пишите сперва Swagger файл, описываете то, чего вы хотите добиться от своего микросервиса, а потом просто указываете, какие функции в вашей системе должны исполнять те или иные операции в API.
Но проблема с микросервисами. Я хочу несколько раз повторить эту фразу. Микросервисы — это ответ на организационные проблемы, это не технический ответ. Я не буду советовать микросервисы никому, кто маленький. Я не буду советовать микросервисы тем, у кого нет проблем с разношерстной технологической базой, кому не нужно писать один сервис на Scala, другой сервис на Python или Haskell. Количество проблем с микросервисами довольно высокое. Этот барьер. Для того, чтобы его преодолеть, нужно довольно много боли испытать перед этим, как сделали это мы.
Одна из самых больших проблем с миркосервисами: микросервисы по своей дефиниции закрывают доступ к системе персистирования данных. Базы спрятаны внутри микросервиса.
Таким образом классический extract transform load process не работает.
Давайте сделаем один шаг назад и вспомним, как работаем в классическом мире. Что у нас есть? У нас есть классический мир, у нас есть developer’ы, junior developer’ы, senior developer’ы, DBA и Business Intelligence.
Как это работает?
В простом случае у нас бизнес логика, база, ETL процесс достаёт прямо из базы наши данные и засовывает в Date Warehouse (DWH).
В большем масштабе у нас есть много сервисов, много баз и один процесс, который пишется, скорее всего, ручками. Вытаскиваются данные из этих баз и кладутся в специальную базу для бизнес-аналитиков. Она очень хорошо структурирована, бизнес аналитики понимают, что они делают.
Конечно это всё — не без проблем. Это всё очень трудно автоматизировать. В мире микросервисов у нас всё не так.
Когда мы объявили о микросервисах, когда мы объявили о Radical Agility, когда мы объявили об этих всех прекрасных нововведениях для developer’ов, бизнес-аналитики были очень недовольны.
Как собирать данные из огромного количества микросервисах?
Речь идет не о десятках, а о сотнях или даже тысячах. Потом приходит Валентин на коне и говорит: мы всё будет писать в поток, в queue. Потом архитекторы говорят: почему queue? Кто-то будет использовать Kafka, кто-то будет использовать Rabbit, как мы будет это всё интегрировать? Наши security-officer’ы сказали: никогда в жизни, мы не позволим. Наши бизнес-аналитики сказали: если там не будет схемы, мы повесимся и не сможем понять, что течёт, это же будет просто сточная канава, а не система транспорта данных.
Мы сели и начали совещаться и решать, что же делать. Наши основные цели: простота использования нашей системы, хотим, чтобы у нас не было single point of failure, не было такого монстра, который если он упадёт, то всё упадёт. Должна быть безопасная система, и эта система должна удовлетворять потребностям бизнес-аналитики, система должна удовлетворять наших data-science’ов. Она должна в хорошем случае дать возможность другим сервисам использовать эти данные, которые текут через шину.
Очень просто. Event Bus.
Из Event Bus мы сможем вытаскивать Business Intelligence или в какие-то Data heavy services. DDDM это любимое понятие в последнее время. Это data driven decisions making system. Любой менеджер будет в восторге от такого слова. Machine learning and DDDM.
Что мы придумали?
Nakadi. Вы наверно поняли, что у меня фамилия довольно грузинская. Nakadi по-грузински значит поток. Например, горный поток.
Мы начали делать такой поток. Основные принципы, которые мы туда вложили, немножко повторюсь.
Мы сказали, что у нас будет стандартный HTTP API. По возможности — restful. Мы сделаем централизованную или по возможности не очень централизованную event type registry. Мы введём разные классы event types. Например, на данный момент у нас поддерживается два класса. Это data capture и business events. То есть если у нас меняются сущности, то мы можем event capture записывать с всей необходимой метаинформацией. Если у нас просто информация о том, что в бизнес-процессе что-то произошло, то это обычно намного более простой случай, и мы можем писать более простой event. Но всё равно бизнес-аналитики требуют, чтобы у нас была организована структура, которую можно будет автоматически парсить.
Имея огромный опыт работы с PostgreSQL и со схемами, мы знаем, что без поддержки версионирования схем ничего не будет работать. То есть если мы скатимся до уровня, где программисты должны будут описывать order created, затем order created 1,2,3, мы будем, по существу, делать систему похожую на Microsoft Windows, и это будет очень трудно, особенно для того чтобы понимать, как развиваться сущность, как версионируется сущность. Очень важно, чтобы этот интерфейс позволял стримить данные, чтобы можно было реагировать как можно быстрее на приход сообщений и оповещать всех желающих о приходе сообщения.
Мы не хотели изобретать велосипед. Наша цель — сделать максимально минимальную систему, которая будет использовать существующие системы. Поэтому на данный момент мы взяли Kafk’у, как underline систему и PostgreSQL для хранения метаданных и схемы.
Nakadi Cluster — это то, что у нас есть. Существует в виде open source проекта. В данный момент он валидирует схему, которую регистрировали до этого. Он умеет записывать дополнительную информацию в метаполя для event’a. Например, время прихода или если клиент не создал уникальные id для event’a, то и уникальные id туда можно запихнуть.
Также мы посчитали, что нужно взять на себя управление offset’ами. Те, кто знает, как работает Kafka. Кто-нибудь знает? Хорошо, но не большинство. Kafka – классическая pub/sub-система, в которой продюсер записывает данные последовательно, а клиент не хранит, как в классических message-системах.
Для клиента не создаются отельные копии message, единственное, что нужно клиенту, — это offset. То есть сдвиг в этом бесконечном потоке. Можете представить, что Kafka — это такой бесконечный поток данных, в котором пронумерована каждая сточка. Если ваш клиент хочет забрать данные, он говорит: читай с позиции X. Kafka даст ему эти данные из позиции X. Таким образом гарантируется упорядоченность данных, таким образом гарантируется что на сервере не надо хранить очень много информации, как обычно делается в классических message-системах, которые позволяют комитить часть прочитанных event’ов. В данной ситуации у нас есть проблема в том нельзя закомитить кусок прочитанного блока. Сейчас пошёл offtext, про Kafk’y не хотел говорить, извините.
High level interface делает чтение из kafk’и очень простым для клиентов. Клиенты не должны обмениваться информацией, кто из какого раздела читает, какие offset’ы они хранят. Просто приходит клиент и получает то, что нужно из системы. Мы решили по пути минимального сопротивления. Zookeeper уже есть для Kafk’и, какой бы ужасный Zookeeper не был, он у нас уже есть, нас уже нужно его manage’ить и мы используем его для хранения offset’ов и дополнительной информации. PostgreSQL — для метаданных и хранения схем.
Сейчас я хочу рассказать в каком направлении мы движемся.
Мы движемся очень быстро. Поэтому, когда я вернусь в Берлин, какие-то части будут уже сделаны.
На данный момент у нас есть Nakadi Cluster, у нас есть Nakadi UI, который мы начали писать на Elm, чтобы заинтересовать других людей. Elm крутой, люблю его.
Следующим шагом мы хотим иметь возможность управлять несколькими кластерами. Мы уже видели косяки, когда приходит новый продюсер и начинает писать 10 тысяч event’ов в секунду, не предупредив ни о чем.
Наш кластер не успевает масштабироваться. Мы хотим, чтобы у нас были разные кластеры по разным типам данных. Стандартизацию интерфейса мы делали специально так, чтобы не было никакой завязки на Kafk’y.
Мы можем переключиться с Kafk’и на Redis. А с Redis’a на Kinesis. По существу, идея такая, что в зависимости от необходимости сервиса и свойств event’ов, которые они пишут, если кому-то не интересен ordering, упорядоченность, то можно использовать систему, которая не поддерживает ordering и более эффективна, чем Kafka. На данный момент у нас есть возможность абстрагировать это, используя наш интерфейс.
Nakadi Scheme Manager нужно вытаскивать из кластера, потому что он должен быть зашерен. Следующий шаг — такая идея, чтобы у нас схемы детектировались. То есть поднимается микросервис, публицирует свой swagger-файл, публицирует список event’ов в том же формате, что и swagger. Автоматически crawker забирает это всё и избавляет developer’ов от необходимости дополнительно перед deployment’ом inject’ить схему в message bus.
Ну и конечно, topology manager, чтобы можно было каким-то образом рутить продюсером и консюмеров на разные кластеры. Тут рассказывали, что Kafka работает как слон. Нет, не как слон, а как паровоз. В нашей ситуации этот паровоз всё время ломается. Не знаю, кто производил этот паровоз, но для того, чтобы управлять Kafk’ой в AWS, оказалось, что это не так просто.
Мы написали систему Bubuku, очень хорошее название, очень русское.
Что делает Bubuku?
У меня был большой слайд, на котором было указано что делает Bubuku, но он получился очень большим. Всё можно посмотреть по ссылке.
В прицепе Bubuku имеет цели делать то, что не делают другие с Kafk’ой. Основные идеи что это автоматически reportition, автоматический scaling и возможность пережить попадания молнией, crazy monkeys которые убивают инстансы.
Кстати, у нас систему тестирует Chaos Monkey, и очень даже неплохо всё это работает. Всем рекомендую, если вы пишите микросервисы, всегда думайте, как эта система переживает Chaos Monkey. Это — Netflix-система, которая рандомно убивает ноды или отключает сеть, портит вам систему
Какую бы вы систему ни построили, если вы её не тестируете, то она не будет работать, если что-то поломается.
Заключая свой поверхностный рассказ, хочу сказать: то, о чем я рассказывал, сейчас мы разрабатываем в open source. Почему open source? Мы даже написали, почему Zalando делает open source.
Когда люди пишут в open source, они пишут не для компании, а для себя отчасти. Поэтому мы видим, что качество продуктов лучше, мы видим, что изолируемость продуктов от инфраструктуры лучше. Никто не записывает внутрь zalando.de и не правят ключи, не комитят в Git.
У нас есть принципы о том, как open source’ить. Есть ли у вас вопросы в компании должны ли мы open source’ить или нет? Есть принцип open source first. Перед тем как начать проект, мы думаем, стоит ли его open source’ить. Для того что понять и ответить на этот вопрос, нужно ответить на вопросы:
- Кому это надо?
- Нужно ли это нам?
- Хотим ли мы с этим заниматься, как open source проектом?
- Можем ли мы то что мы будем держать в этом publice tree?
- Если ваш проект содержит domain knowledge, то что делает компанию вашей компанией, это нельзя open source’ить, конечно.

Если вы пойдете на zalando.github.io, там огромное количество проектов на PostgreSQL, очень много библиотек как для бэкенда, так и для фронтенда, очень рекомендую.
У меня кончилось время.
Шины и протоколы в промышленной автоматике: как всё это работает
Наверняка многие и вас знают или даже видели, каким образом управляются большие автоматизированные объекты, например, атомная станция или завод со множеством технологических линий: основное действо часто происходит в большой комнате, с кучей экранов, лампочек и пультов. Это комплекс управления обычно называется ГЩУ — главный щит управления для контроля за производственным объектом.
Наверняка вам было интересно, как всё это работает с точки зрения аппаратной и программной части, и какие там используются протоколы передачи данных. В этой статье мы разберемся, как различные данные попадают на ГЩУ, как подаются команды на оборудование, и что вообще нужно, чтобы управлять компрессорной станцией, установкой производства пропана, линией сборки автомобиля или даже канализационно-насосной установкой.
Нижний уровень или полевая шина — то, с чего всё начинается
Этот неясный для непосвященных набор слов используется, когда нужно описать средства общения устройств управления с подведомственным оборудованием, например, модулями ввода-вывода или измерительными устройствами.
Под устройствами управления мы подразумеваем ПЛК, т.е. программируемые логические контроллеры (англ. PLC), или ПКА, т.е. программируемые контроллеры автоматизации (англ. PAC). Между ПЛК и ПКА есть некоторые различия, однако, в рамках данной статьи они не существенны, поэтому для упрощения будем использовать общий термин «контроллер».
В русскоязычном сообществе асушников канал общения между контроллером и другими устройствами обычно называют «полевой шиной», потому что он отвечают за передачу данных, которые приходят с «поля».
«Поле» — это глубокий профессиональный термин, обозначающий тот факт, что некое оборудование (например, датчики или исполнительные механизмы), с которым взаимодействует контроллер, находятся где-то далеко-далеко, на улице, в полях, под покровом ночи. И неважно, что датчик может быть расположен в полуметре от контроллера и измерять, допустим, температуру в шкафу автоматики, все равно считается, что он находится «в поле». Чаще всего сигналы с датчиков, приходящие в модули ввода-вывода все-таки преодолевают расстояния от десятков до сотен метров (а иногда и больше), собирая информацию с удаленных площадок или оборудования. Собственно, поэтому шина обмена, по которой контроллер получает значения с этих самых датчиков, называется обычно полевой шиной или реже шиной нижнего уровня или промышленной шиной.
Тут следует отметить, что в Европе и США полевым уровнем считаются только сами устройства, расположенные «в поле», но не среда передачи данных. В российских реалиях термин «полевая шина» или «шина нижнего уровня», пожалуй, слегка размыт и обозначает способ передачи данных от модулей ввода-вывода к контроллеру и наоборот.

Общая схема автоматизации промышленного объекта
Итак, электрический сигнал от датчика проходит некое расстояние по кабельным линиям (чаще по обычному медному кабелю с некоторым количеством жил), к которым подсоединяются несколько датчиков. Затем сигнал попадает в модуль обработки (модуль ввода-вывода), там он преобразуется в понятный контроллеру цифровой язык. Далее этот сигнал по полевой шине попадает непосредственно в контроллер, где и обрабатывается уже окончательно. На основе таких сигналов и строится логика работы самого контроллера. Существует и обратный путь: от контроллера команда управления по полевой шине попадает в модуль вывода, где преобразуется из цифрового вида в аналоговый и поступает по кабельным линиям к исполнительным механизмам и различным устройствам (на схеме выше не указаны).
Верхний уровень: от гирлянды до целой рабочей станции
Верхним уровнем называют все то, к чему может прикасаться обычный смертный оператор, который управляет технологическим процессом. В простейшем случае верхний уровень представляет собой набор лампочек и кнопочек. Лампочки сигнализируют оператору о неких происходящих событиях в системе, кнопочки служат для подачи команд контроллеру. Такую систему часто называют «гирлянда» или «ёлка», потому что выглядит очень похоже (как можно убедиться по фотографии в начале статьи).
Если оператору повезло больше, то в качестве верхнего уровня ему достанется панель оператора — некий плоскопанельный компьютер, который тем или иным образом получает данные для отображения от контроллера и выводит их на экран. Такая панель обычно монтируется на сам шкаф автоматики, поэтому взаимодействовать с ней приходится, как правило, стоя, что вызывает неудобства, плюс качество и размер изображения — если это малоформатная панелm — оставляет желать лучшего.

Ну и, наконец, аттракцион невиданной щедрости — рабочая станция (а то и несколько дублирующих), представляющая собой обычный персональный компьютер.
Для наглядного отображения информации на рабочих станциях и плоскопанельных компьютерах используют специализированное программное обеспечение — SCADA-системы. На человеческий язык SCADA переводится как система диспетчерского управления и сбора данных. Она включает в себя множество компонентов, таких как человеко-машинный интерфейс, визуализирующий технологические процессы, систему управления этими процессами, систему архивирования параметров и ведение журнала событий, систему управления тревогами и т.д. Всё это дает оператору полноценную картину происходящих на производстве процессов, а также возможность ими управлять и оперативно реагировать на отклонения от технологического процесса.
Оборудование верхнего уровня обязано взаимодействовать неким образом с контроллером (иначе зачем оно нужно?). Для такого взаимодействия используются протоколы верхнего уровня и некая технология передачи, например, Ethernet или UART. В случае с «ёлкой» таких изощрений, конечно, не нужно, лампочки зажигаются с использованием обычных физических линий, никаких мудреных интерфейсов и протоколов там нет.
В общем-то, этот верхний уровень менее интересен, нежели полевая шина, поскольку этого верхнего уровня может вообще не быть (из серии нечего там смотреть оператору, контроллер сам разберется, что и как нужно делать).
«Древние» протоколы передачи данных: Modbus и HART
Мало кто знает, но на седьмой день создания мира Бог не отдыхал, а создавал Modbus. Наравне с HART-протоколом, Modbus, пожалуй, самый старый промышленный протокол передачи данных, он появился аж в 1979 году.
В качестве среды для передачи изначально использовался последовательный интерфейс, затем Modbus реализовали поверх TCP/IP. Это синхронный протокол по схеме «мастер-слейв» (главный-подчиненный), в котором используется принцип «запрос-ответ». Протокол довольно тяжеловесный и медленный, скорость обмена зависит от характеристик приемника и передатчика, но обычно счет идет чуть ли не на сотни миллисекунд, особенно в реализации через последовательный интерфейс.
Более того, регистр передачи данных Modbus является 16-битным, что сразу же накладывает ограничения на передачу типов real и double. Они передаются либо по частям, либо с потерей точности. Хотя Modbus до сих пор повсеместно используется в случаях, когда не нужна высокая скорость обмена и потеря передаваемых данных не критична. Многие производители различных устройств любят расширять протокол Modbus своим исключительным и очень оригинальным образом, добавляя нестандартные функции. Поэтому данный протокол имеет множество мутаций и отклонений от нормы, но все же до сих пор успешно живет в современном мире.
Протокол HART тоже существует с восьмидесятых годов, это промышленный протокол обмена поверх двухпроводной линии токовой петли, в которую напрямую включаются датчики 4-20 мА и другие приборы с поддержкой протокола HART.
Для коммутации линий HART используются специальные устройства, так называемые HART-модемы. Также существуют преобразователи, которые на выходе предоставляют пользователю уже, допустим, протокол Modbus.
Примечателен HART, пожалуй, тем, что помимо аналоговых сигналов датчиков 4-20 мА в цепи передается и цифровой сигнал самого протокола, это позволяет соединить цифровую и аналоговую часть в одной кабельной линии. Современные HART-модемы могут подключаться в USB-порт контроллера, соединяться по Bluetooth, либо же старинным способом через последовательный порт. Десяток лет назад по аналогии с Wi-Fi появился и беспроводной стандарт WirelessHART, работающий в диапазоне ISM.
Второе поколение протоколов или не совсем промышленные шины ISA, PCI(e) и VME
На смену протоколам Modbus и HART пришли не совсем промышленные шины, такие как ISA (MicroPC, PC/104) или PCI/PCIe (CompactPCI, CompactPCI Serial, StacPC), а также VME.
Настала эра вычислителей, имеющих в своем распоряжении универсальную шину передачи данных, куда можно подключать различные платы (модули) для обработки некоего унифицированного сигнала. Как правило, в этом случае процессорный модуль (вычислитель) вставляется в так называемый каркас, который обеспечивает взаимодействие по шине с другими устройствами. Каркас, или, как его любят называть трушные автоматизаторы, «крейт», дополняется необходимыми платами ввода-вывода: аналоговыми, дискретными, интерфейсными и т.д., либо все это слепливается в виде бутерброда без каркаса — одна плата над другой. После чего это многообразие на шине (ISA, PCI, etc.) обменивается данными с процессорным модулем, который таким образом получает информацию с датчиков и реализовывает некую логику.

Контроллер и модули ввода-вывода в каркасе PXI на шине PCI. Источник: National Instruments Corporation
Все бы ничего с этими шинами ISA, PCI(e) и VME, особенно для тех времен: и скорость обмена не огорчает, и расположены компоненты системы в едином каркасе, компактно и удобно, горячей замены плат ввода-вывода может и не быть, но пока еще и не очень хочется.
Но есть ложка дегтя, и не одна. Распределенную систему довольно сложно построить в такой конфигурации, шина обмена локальная, нужно что-то придумывать для обмена данными с другими подчиненными или равноправными узлами, тот же Modbus поверх TCP/IP или какой другой протокол, в общем, удобств маловато. Ну и вторая не очень приятная штука: платы ввода-вывода обычно ждут на вход какой-то унифицированный сигнал, и гальванической развязки с полевым оборудованием у них нет, поэтому нужно городить огород из различных модулей преобразования и промежуточной схемотехники, что сильно усложняет элементную базу.

Промежуточные модули преобразования сигнала с гальванической развязкой. Источник: DataForth Corporation
«А что с протоколом обмена по промышленной шине?» — спросите вы. А ничего. Нет его в такой реализации. По кабельным линиям сигнал попадает с датчиков на преобразователи сигналов, преобразователи выдают напряжение на дискретную или аналоговую плату ввода-вывода, а данные с платы уже читаются через порты ввода/вывода, средствами ОС. И никаких специализированных протоколов.
Как работают современные промышленные шины и протоколы
А что теперь? К сегодняшнему дню классическая идеология построения автоматизированных систем немного поменялась. Роль сыграли множество факторов, начиная с того, что автоматизировать тоже должно быть удобно, и заканчивая тенденцией на распределенные автоматизированные системы с удаленными друг от друга узлами.
Пожалуй, можно сказать, что основных концепций построения систем автоматизации на сегодняшний день две: локализованные и распределенные автоматизированные системы.
В случае с локализованными системами, где сбор данных и управление централизовано в одном конкретном месте, востребована концепция некоего набора модулей ввода-вывода, соединенных между собой общей быстрой шиной, включая контроллер со своим протоколом обмена. При этом, как правило, модули ввода-вывода включают в себя и преобразователь сигнала и гальваническую развязку (хотя, разумеется, не всегда). То есть конечному потребителю достаточно понять, какие типы датчиков и механизмов будут присутствовать в автоматизированной системе, сосчитать количество требуемых модулей ввода-вывода для разных типов сигналов и соединить их в одну общую линейку с контроллером. В этом случае, как правило, каждый производитель использует свой любимый протокол обмена между модулями ввода-вывода и контроллером, и вариантов тут может быть масса.
В случае распределенных систем справедливо все, что сказано в отношении локализованных систем, кроме этого, важно, чтобы отдельные компоненты, например, набор модулей ввода-вывода плюс устройство сбора и передачи информации — не очень умный контроллер, который стоит где-нибудь в будке в поле, рядом с краном, который перекрывает нефть, — могли взаимодействовать с такими же узлами и с главным контроллером на большом расстоянии с эффективной скоростью обмена.
Как разработчики выбирают протокол для своего проекта? Все современные протоколы обмена обеспечивают довольно высокое быстродействие, поэтому зачастую выбор того или иного производителя обусловлен не скоростью обмена по этой самой промышленной шине. Не так важна и реализация самого протокола, потому что, с точки зрения разработчика системы, это все равно будет черный ящик, который обеспечивает некую внутреннюю структуру обмена и не рассчитан на вмешательство извне. Чаще всего обращают внимание на практические характеристики: производительность вычислителя, удобство применения концепции производителя к поставленной задаче, наличие нужных типов модулей ввода-вывода, возможность горячей замены модулей без разрыва шины и т.д.
Популярные поставщики оборудования предлагают собственные реализации промышленных протоколов: например, всем известная компания Siemens разрабатывает свою серию протоколов Profinet и Profibus, компании B&R — протокол Powerlink, Rockwell Automation — протокол EtherNet/IP. Отечественное решение в этом списке примеров: версия протокола FBUS от российской компании Fastwel.
Есть и более универсальные решения, которые не привязаны к конкретному производителю, такие как EtherCAT и CAN. Мы подробно разберем эти протоколы в продолжении статьи и разберемся, какие из них лучше подходят для конкретных применений: автомобильной и аэрокосмической промышленности, производства электроники, систем позиционирования и робототехники. Оставайтесь на связи!
- IT-инфраструктура
- Промышленное программирование
- Производство и разработка электроники
- Инженерные системы
Цифровая подстанция: Применение. Шины процесса

Оцифровка величин тока и напряжения, поступающих от измерительных трансформаторов с технологией NCIT (нетрадиционные измерительные трансформаторы) или от обычных измерительных трансформаторов, преобразованных в цифровую форму так называемыми автономными объединяющими устройствами (SAMU), и простота доступа к этим данным, через цифровой стандартизированный интерфейс, со стороны любых электронных устройств, таких, как средства защиты, компьютерные системы, представляют собой главные преимущества этой технологии. Предполагается внедрение новых функциональных возможностей, например: интеллектуальный мониторинг, функции защиты на базе программных модулей, реализованных в рамках стандартных платформ аппаратных средств, и новые распределенные функции на компьютерах присоединения. Кроме того, интеллектуальный контроль всей системы NCIT предотвращает возможность возникновения существенных отказов мерами предупредительного техобслуживания, исключает несвоевременные ремонтные отключения и обеспечивает надежное функционирование подстанций посредством использования интеллектуального резервирования, например, такого, как протокол параллельного резервирования PRP (Parallel Redundancy Protocol).

Совместимость обычных измерительных трансформаторов и всех трансформаторов с технологиями NCIT, а также оборудования различных поставщиков может быть достигнута в результате использования стандартного протокола: «Шина процесса» (Process bus), т.е. МЭК 61850-9-2 со специальной рекомендацией МЭК 61850-9-2LE.
ВВЕДЕНИЕ
Международный стандарт МЭК 61850 для систем передачи данных открывает новую эру в области совершенствования подстанций. Он охватывает не только проектирование систем релейной защиты, контроля и управления подстанций, но и разработку вторичных цепей подстанций. Высокоскоростная связь между равноправными устройствами с использованием GOOSE-сообщений и дискретизированных аналоговых значений (Sampled Analogue Values) позволяет усовершенствовать распределенные приложения, базирующиеся на передаче значений тока и напряжения между устройствами, подключенными к сети технологического процесса и к локальной сети подстанции.
За несколько прошедших лет тенденции развития рынка в направлении реализации требований МЭК 61850 стали одинаково очевидными как для поставщиков, так и для заказчиков. Значительная доля этого интереса сконцентрирована на процессе миграции от решений реализации шин подстанций, продиктованных интересами изготовителей, в направлении систем автоматизации подстанций, которые характеризуются полной интеграцией интеллектуальных устройств IED, таких, как терминалы релейной защиты, в соответствии с требованиями принятого международного стандарта.
Этот подход был сосредоточен главным образом на «Шине подстанции» стандарта МЭК 61850-8-1 и реализовывался путем моделирования и развития по аналогии с традиционными подходами систем SCADA.
«Шина процесса» (Process bus), определенная стандартом МЭК 61850- 9-2, остается в существенной степени неисследованной до настоящего времени.
МЭК 61850-9-2 представляет собой часть стандарта, который внедряет в практику технологию нетрадиционных измерительных трансформаторов (NCIT), устраняя несовершенства и ограничения традиционных ТТ и ТН с их обмотками на стальных сердечниках.

«ШИНА ПРОЦЕССА» (PROCESS BUS)
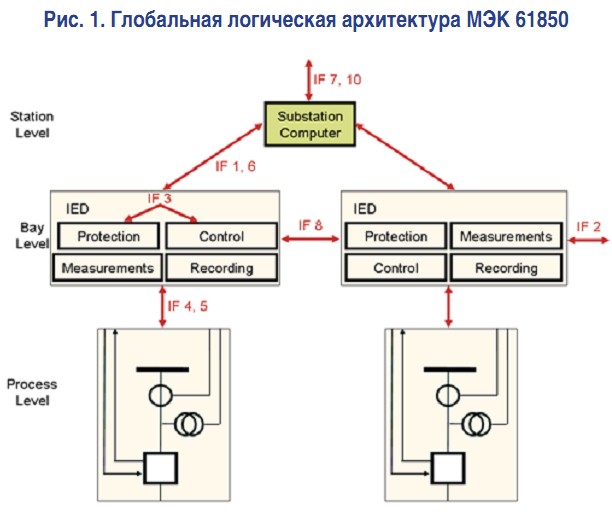
«Шина процесса», определенная стандартом МЭК 61850-9-2, позволяет использовать цифровую связь между электронными трансформаторами тока/напряжения или объединяющими устройствами и устройствами присоединения, такими, как реле защиты, контроллерами или счетчиками присоединения. Это канал связи 4 на рисунке 1, заимствованном из стандарта МЭК 61850.
Фактически все технологии DIT используют электронные терминалы, поэтому они не позволяют применять традиционные аналоговые выходы измерительных трансформаторов по причине повышенной потребности в электропитании для усилителей.
В 1998 году возникла идея передачи «мгновенных значений измерений» (Sampled Values) по цифровым сетям передачи данных. Описание первой рекомендации было дано в стандарте МЭК 60044-8.
Компаниями Alstom и RTE был проведен успешный эксперимент по использованию оптического трансформатора тока на подстанции «Вилмулин» 400 кВ.
В 2002 году несколькими основными производителями был запущен проект «Совместимость» и произведен выбор протокола. Им стал протокол «Шина процесса» (Process bus). В документе под названием LE (Light Edition, облегченная редакция), входящем в состав Руководства, зафиксирован основной параметр протокола. Первая успешная демонстрация проведена на CIGRE в 2004 году.
В 2008 году рабочая группа TC38 начала разработку редакции нового стандарта МЭК 61869-9-2 для электронных измерительных трансформаторов. Предложенный цифровой интерфейс основывается на рекомендациях МЭК 61850-9-2 LE с дополнительными характеристиками. Этот документ будет издан в 2011 г.
Предложенная архитектура
Сохранение существующей архитектуры подстанции с резервированием сети Ethernet (PRP или HSR):
• защита (80 выборок/цикл) — основной канал 1;
• защита (80 выборок/цикл) — основной канал 2 (резерв);
• регистрация возмущений (256 выборок/цикл — полоса пропускания 10 кГц);
• учет (80 выборок/цикл) — коммерческий учет или учет тарифов;
• оценка качества электроэнергии (256 выборок/ цикл – анализ гармоник — 100 e).
Объединяющие устройства для мгновенных значений измерений:
• N-MU или P-MU для DIT (объединяющее устройство для подключения к первичным преобразователям, разделенным или в виде единого устройства, предназначенное для работы с датчиками различных типов);
• A-MU для CIT (объединяющее устройство для подключения к обычным измерительным трансформаторам с аналоговыми входами).
Объединяющее устройство для контроллеров выключателей:
• совместимость;
• CB-MU для выключателей и разъединителей (ввод/вывод, подача команды на отключение через GOOSE-сообщения);
• CB-MUM для выключателей (контроль и подача команды на отключение выключателя; резервирование).
Две независимые сети: 9–2 для передачи мгновенных значений измерений и 8–1 для GOOSE:
• «Шина процесса» (сеть Ethernet, в настоящее время 100 BaseFx) со стандартом МЭК 61850-9.2 LE для мгновенных значений измерений SV, которая в скором времени станет глобальным стандартным интерфейсом МЭК 61869-9-2, для измерений тока и напряжения;
• «Шина процесса» (сеть Ethernet, в настоящее время 100 BaseFx) со стандартом МЭК 61850-8.1 служба GOOSE-сообщений для положения выключателя-разъединителя (SW), положения и отключений автоматического выключателя.

ПРЕИМУЩЕСТВА ИНТЕГРАЦИИ «ШИНЫ ПРОЦЕССА»
Оцифровка величин тока и напряжения
Мгновенные значения, полученные от нетрадиционных или традиционных измерительных трансформаторов, оцифрованные так называемыми автономными объединяющими устройствами (SAMU), обеспечивают связь в реальном масштабе времени, что, в свою очередь, позволяет осуществить простой доступ к этим данным со всех прочих устройств подстанции (средств релейной защиты, компьютерных систем, и др.) путем реализации технологии Ethernet. Это является одним из главных преимуществ!
Совместимость
Достигается совместимость технологий традиционных и нетрадиционных измерительных трансформаторов, а также согласованность оборудования всех поставщиков со стандартным протоколом. Это обеспечивает значительно большую гибкость при проведении реконструкций подстанций генерирующих предприятий. Этот пункт абсолютно обязателен и противопоставляется «частным» решениям.
Простота эксплуатации
• оптическая технология Ethernet 100 BaseFX позволяет радикально упростить кабельную систему;
• оптический кабель имеет естественную изоляцию ЭМИ, что способствует снижению затрат на проектирование, инжиниринг и повышает общую надежность системы;
• используемые технологиями DIT электронные компоненты обеспечивают повышение степени промышленной стандартизации путем уменьшения разнообразия моделей ТТ/ТН по причине осуществимости повторной калибровки с помощью электронных установок.
Ввод в эксплуатацию, испытания на объекте, простота конфигурирования архитектуры позволяют добиться снижения численности персонала.
Ожидаемые новые функциональные возможности
Ниже приводится неполный перечень функциональных возможностей:
• интеграция всех функций защиты, управления, измерений и контроля в пределах подстанции на основе программных модулей, легко переносимых на любые стандартные аппаратные платформы;
• обеспечение средств для высокоскоростных приложений подстанции (новые функции защиты, блокировки, телеотключения);
• обеспечение новых распределенных функций для контроллеров присоединения или упрощенных устройств защиты (например, контроль синхронизма, регистрация переходных процессов, анализ гармоник и т.д.);
• возможность упрощенной повторной калибровки ТТ/ТН при работе с различными номиналами точек измерений.

Повышение степени готовности-надежности
• постоянный интеллектуальный контроль в оперативном режиме параметров трансформаторов тока, напряжения и автоматических выключателей, повышающий надежность эксплуатации;
• предотвращение серьезных аварий путем предупредительного техобслуживания;
• исключение несвоевременных ремонтных отключений.
Все это вносит вклад в обеспечение безопасности подстанций в результате применения интеллектуального резервирования, например, протокола параллельного резервирования PRP (Parallel Redundancy Protocol) (дублированная сеть передачи данных) или качественно интегрированного резервирования высокой степени готовности HSR (High-availability Seamless Redundancy).
Все эти преимущества обеспечивают ценный вклад в повышение надежности и готовности современных высоковольтных сетей и являются одной из важнейших задач концепции Smart Grid.
Нашли ошибку? Выделите и нажмите Ctrl + Enter