Почему Google Переводчик и аналоги работают неидеально: как устроены их алгоритмы

Над автоматическими переводчиками начали работать ещё в середине XX века. После одного из успешных экспериментов в газетах писали, что скоро ручной перевод будет не нужен — переводчиков-людей заменят машины. С тех пор прошло 70 лет, но автоматический перевод всё ещё делает глупые и грубые ошибки. Что с ним не так?
Подписывайтесь на наш Телеграм
Почему раньше онлайн-переводчиками было невозможно пользоваться без смеха
Ещё 5-7 лет назад любой онлайн-переводчик выдавал наборы фраз, в которых с трудом можно было уловить смысл текста. Если вы переводили с иностранного языка на родной, то это можно было исправить. Но при переводе с родного языка на иностранный сразу было видно, что поработал Google Translate или другой переводчик. Виной всему была сама технология — статистический машинный перевод.
Чтобы лучше понимать, почему переводчики раньше были такими топорными, давайте коротко пройдёмся по основным технологиям, которые использовались для обработки текстов на разных языках. Работа над автоматизированными системами перевода начались ещё в середине XX века. Сначала в них использовали правила, которые составляли лингвисты. Их количество было огромным, а результат работы всё равно провальным. Переводчики не справлялись с многозначными словами и не понимали устойчивые выражения.
Разочарование от первых систем перевода было таким большим, что почти 30 лет никто не вкладывал в эту сферу большие деньги. Всё изменилось в начале 1990-х годов, когда одна из исследовательских групп компании IBM разработала новую переводную модель. Ключевая идея технологии — концепция канала с ошибками, которая рассматривает текст на языке A как зашифрованный текст на языке Б. Задача переводчика — расшифровать фрагмент.
Основой для модели IBM стали документы канадского правительства, написанные на английском и французском языках. Именно эта пара стала первой, над которой стали работать специалисты. Они собрали вероятности для всех сочетаний слов определённой длины на одном языке и вероятности для соответствия каждого из таких сочетаний сочетанию на другом языке. Фактически алгоритм пытается найти самую частотную фразу на языке А, которая имеет хоть какое-то отношение к фразе на языке Б.
Система статистического машинного перевода IBM стала прорывной. С появлением интернета у специалистов появился доступ к огромному количеству данных на разных языках. Исследователи сконцентрировались на сборе корпуса параллельных текстов — одинаковых документов, написанных на разных языках. Это протоколы международных организаций, научные материалы, публицистика. При их изучении устанавливалось соответствие предложений и слов. Например, при сравнении текстов на разных языках система понимает, что «cat» и «кошка» — вероятные переводы друг друга.
В статистической модели машинного перевода каждому слову и фразе соответствует числовой идентификатор, который определяет частоту использования в языке. При переводе предложение разбивается на независимые части. Для каждого элемента этого массива подбирается потенциальный перевод. Затем система собирает несколько вариантов предложения на другом языке и выбирает из них оптимальный с точки зрения сочетаемости слов.
Но машинный перевод всё равно работал неидеально. Главная проблема состояла в том, что слова и фразы переводились независимо. Переводчики не учитывали контекст и даже не согласовывали части предложения. Другая проблема — нехватка параллельных текстов. Из-за этого сложно установить соответствие. В качестве универсального связующего языка в статистическом машинном переводе используется английский.
Если параллельных текстов между двумя языками мало, то перевод выполняется в два этапа. Например, при переводе с русского на малайский порядок будет такой: сначала с русского на английский, затем с английского — на малайский.
Результат получается близким к натуральным, но даже в такой короткой цепочке могут возникнуть ошибки из-за многозначных слов.
Нейросети сделали перевод заметно лучше — иногда его сложно отличить от человеческого
Нейросети тоже анализируют массив параллельных текстов — в этом смысле ничего не изменилось. Но вместо простых идентификаторов при нейросетевом подходе используется векторное представление. Каждый вектор состоит из чисел, которые характеризуют слово по лексическим и семантическим признакам.
При статистическом машинном переводе исходное предложение разбивается на слова и фразы, после чего система ищет для них соответствие в другом языке. При нейросетевом переводе предложение переводится целиком. Оно превращается в векторное пространство, где у каждого слова есть вектор длиной в несколько сотен чисел. Нейросеть определяет взаимосвязь между словами, даже если они находятся в разных концах предложения. Поэтому перевод получается более натуральным.
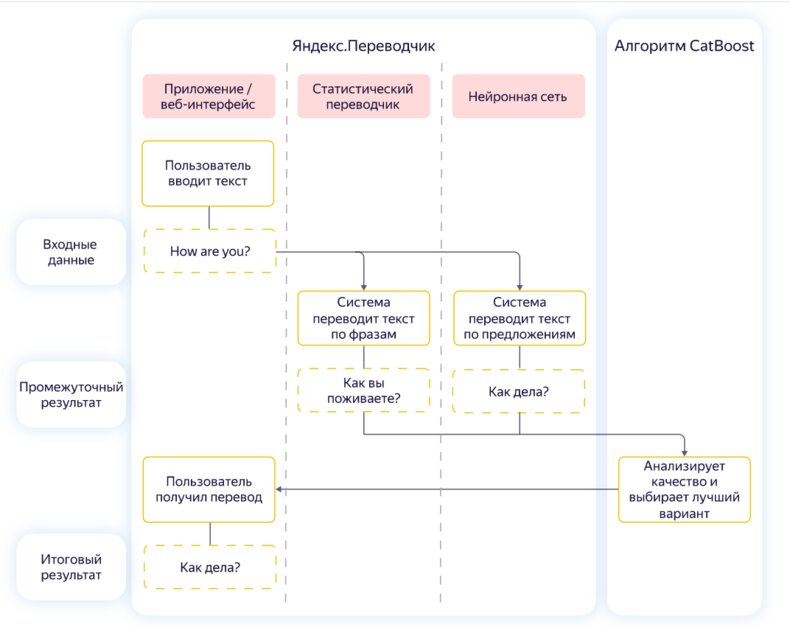
Так работает Яндекс.Переводчик
Несмотря на появление нейросетевого подхода, от статистического машинного анализа пока полностью не отказались. Например, в Яндекс.Переводчике используется гибридная модель перевода, которая включает статистический и нейросетевой подходы. После обработки текста двумя моделями в работу включается алгоритм, который выбирает лучший вариант.
Перевод стал лучше, но всё ещё очень много ошибок. Нейросети не справляются?
Количество ошибок в переводе зависит от многих факторов. Среди них — родство языков и объём данных, на которых была обучена нейросеть.
Например, алгоритмы Google Translate обучали на языковых парах «английский — испанский» и «английский — французский». Судя по результатам исследования, профессиональные переводчики оценили качество обработки текста в этих парах почти на уровне человеческого перевода.
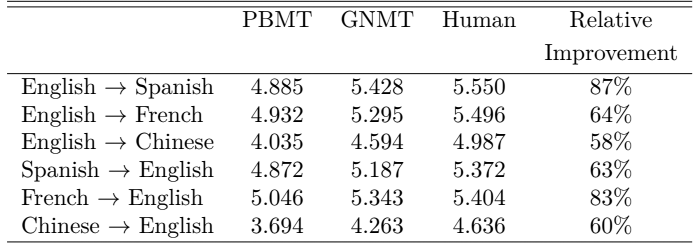
Первый столбец — статистичекий перевод, второй — нейросетевой, третий — человеческий Максимальная оценка — 6 баллов.
Чем ближе языки друг к другу по структуре, тем выше точность перевода. Но если взять языки из разных систем — например, русский и японский, то здесь универсальные переводчики начинают хромать.
При нейросетевом переводе тоже используется корпус параллельных текстов. Соответственно, сохраняется проблема с нехваткой данных. Если параллельных текстов не хватает для перевода, в ход идёт язык-посредник — английский. Из-за этого возникают неточности. Вы можете сами это легко проверить, если переведёте предложение последовательно на несколько языков.
Например, вот перевод одного из абзацев из этой статьи: русский — английский — монгольский — венгерский — русский. Было так:
«Количество ошибок в переводе зависит от многих факторов. Среди них — родство языков и объём данных, на которых была обучена нейросеть».
Вместо родства появились коммуникации
Перевод получился корявым. С другой стороны, это абсолютно бессмысленный эксперимент. Вряд ли в реальной жизни кому-то требуется такая цепочка. Но результаты проверки как раз показывают, что происходит с переводом, когда между языками не хватает параллельных текстов.
Как можно улучшить работу онлайн-переводчиков
По словам разработчиков из команды Яндекса по машинному переводу, один из перспективных путей улучшения качества переводчиков — усиление роли контекста. Он может включать предыдущее предложение, информацию о сущностях и лицах, упомянутых в тексте, сведения о том, из какого места на веб-странице взят фрагмент.
Любой специалист по переводу скажет, что чем больше контекста или справочной информации, тем проще обрабатывать текст. Это легко проверить. Когда вы учите язык и начинаете на нём читать книги или смотреть фильмы, то часть слов понимаете просто из контекста.
Как это работает на примере онлайн-переводчика? Самая очевидная ситуация — система при переводе обращает внимание на предыдущее предложение. Как минимум это позволяет решить проблему с местоимениями. Учитывая контекст предыдущего предложения, переводчик выбирает правильный род для подлежащего или дополнения.
Больше никаких проблем с местоимениями
Улучшить качество перевода помогает также добавление в обучающий массив аудио и видео. Сейчас разработчики собирают данные. Например, если в приложении Google Translate запустить режим «Преобразование речи в текст», то появится предупреждение о том, что сделанная вами аудиозапись будет отправлена на обработку в Google. Компания может хранить расшифровку аудио в течение определённого времени в целях улучшения «Переводчика».
Сложность обработки аудиозаписей в том, что в них часто нет контекста. Когда люди разговаривают друг с другом, даже через переводчика, они используют и другие способы коммуникации — например, жестикулируют. Однако добавление аудио всё равно приносит пользу — чем больше данных, тем точнее перевод.
Помогают сделать сервисы лучше и люди. Например, в Яндексе работает группа лингвистической экспертизы, в которую входят редакторы-эксперты и переводчики. Они передают тексты в выборку для машинного обучения.
Google предлагает пользователям стать участниками сообщества «Переводчика», чтобы улучшать качество переводов и добавлять новые языки. Участники сообщества проверяют переводы. Варианты с высокими оценками от специалистов показываются со специальным значком — вы наверняка его видели.
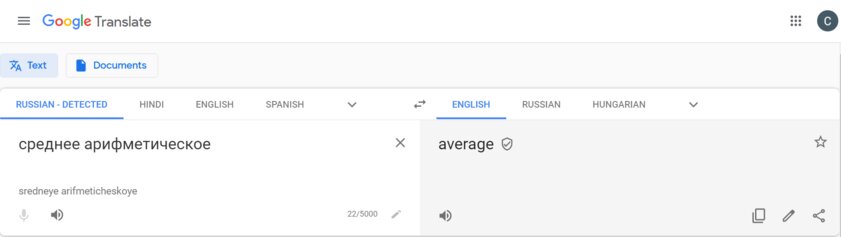
Перевод подтверждён сообществом Google Translate
Внести свою лепту в развитие «Google Переводчика» может каждый. Например, можно нажать на кнопку «Редактировать перевод» и предложить свой вариант. Он будет отправлен на рассмотрение участникам сообщества. Если они проголосуют за ваш вариант как за корректный, то он станет основным в переводчике.
Чтобы голосовать за варианты перевода и добавлять свои фразы, нажмите на кнопку «Сообщество» на главной странице Google Translate. Система предложит выбрать два языка. После этого вы сможете выбирать корректные варианты и делать онлайн-переводчик лучше.
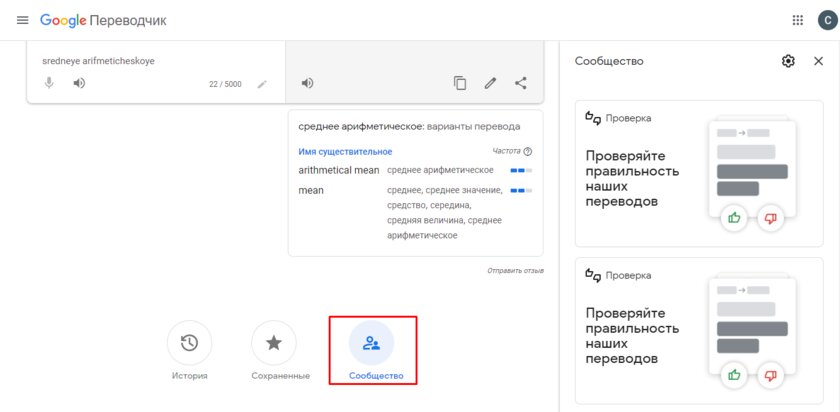
Вступить в сообщество Google Translate может любой пользователь
Сейчас работа Google Translate, Яндекс.Переводчика и других подобных сервисов всё ещё кажется неидеальной. Но если оглянуться назад, то они стали переводить тексты намного точнее. По крайней мере, их возможностей уже сейчас достаточно для того, чтобы свободно общаться с носителями разных языков.
Топ-5 самых распространенных ошибок переводчиков
Переводчики, даже специалисты с богатым опытом, периодически совершают ошибки, не говоря уже о тех, кто освоил азы письменности и разговорной речи сравнительно недавно. О некоторых наиболее комичных ляпах при переводах фильмов, устной речи и даже технической документации ходят легенды. В этой статье мы приведем пять основных ошибок, которые являются самыми распространенными для начинающих переводчиков.

Хороший перевод зависит от внимания к мелочам
Что такое хороший перевод?
Перед тем как перейти к рассмотрению классических ошибок, нужно разобраться, а что представляет собой хороший перевод? Умение переводить тексты с одного языка на другой предполагает не только знание значений иностранных слов, но также понимание того, как строятся грамматические конструкции. Во многих языках используются фразеологизмы – устойчивые речевые обороты, которые нельзя переводить буквально, так как они имеют уникальное значение.
Любой иностранный язык основан на культурных традициях народа, и некоторые конструкции достаточно сложно адаптировать и выразить на другом языке. Поэтому хороший перевод – это правильное восприятие исходного текста, его грамотная адаптация к особенностям иного языка. Итак, перейдем к распространенным ошибкам.
1. Дословный перевод
Часто неопытные переводчики начинают переводить предложение последовательно, слово за словом, не учитывая, что на другом языке первое слово исходного предложения может оказаться последним в предложении перевода, в результате чего меняется его смысл. Особенно это касается устной речи, когда переводчик вынужден переводить как можно быстрее, чтобы успеть за тем, кто говорит. Более опытные коллеги предпочитают дождаться, пока выступающий или собеседник закончит полностью ходя бы одну фразу (или переводят только после того, как дочитают предложение до конца).
Например, фраза ”God is the only one who knows all truth“ переводится как «Полная истина известна только Богу», в то время как последовательный перевод (неправильный) будет звучать так: «Бог является единственным, кто знает всю правду».

Переводчик должен знать наиболее употребляемые лексические конструкции
2. Дословный перевод фразеологизмов
Во многих языках есть конструкции, призванные обогатить речь, сделать ее более выразительной. В русском языке тоже есть немало оборотов, которые кажутся иностранцам нелогичными или нелепыми. Отсутствие опыта заставляет переводчиков, которые недостаточно долго общались в языковой среде, переводить такие выражения дословно. В результате вместо внятного перевода текста часто получаются довольно забавные словосочетания, которые в лучшем случае явно не отражают смысл сказанного (написанного), а в худшем – искажают его.
Например, часто употребляемое выражение ”Watch out!“ означает вовсе не «Посмотри снаружи!», а «Берегись!». Подобным образом переводит тексты и Google Translate, чем немало веселит пользователей и вводит в ступор и уныние тех, кому срочно нужно перевести предложение.
3. Незнание полного списка значений иностранного слова
Некоторые языки включают слова, которые имеют несколько лексических значений, причем иногда список значений может быть довольно обширным. Неосторожный выбор значения без привязки к контексту может сильно исказить смысл изложенного. Хотя в ряде случаев, если применять обычную логику, контекст сам подсказывает, какое значение слова необходимо брать.
Например, выражение ”She is bold today“ было переведено как «Она сегодня лысая». Очень сомнительно, чтобы автор описывал внешность женщины, которая настолько резко изменила стиль своей прически. Логично предположить, что речь шла о каком-либо смелом поступке, который совершила героиня. ”To be bold“ означает «быть смелым», «проявить смелость». В этом случае перевод должен звучать так: «Она сегодня смелая».
Кстати, о многозначности слов… Фильм «Летят журавли» (”Les grues volent“) был показан на фестивале в Каннах и получил приз «Золотая пальмовая ветвь». Однако для того, чтобы показать фильм, пришлось срочно подобрать альтернативное название. Картине присвоили название «Когда прилетают аисты» (”Quand passent les cigognes“). Дело в том, что буквальный перевод прежнего названия по причине многозначности каждого из слов мог бы восприниматься как фраза «Проститутки воруют».
4. Созвучие иностранного слова с русским не всегда означает то же самое
Есть много слов, которые пришли в русский язык из иностранных языков (интернационализмы). Иногда переводчики, желая сократить время, просто заменяют созвучные слова знакомыми значениями, не учитывая тот факт, что иногда это же слово на другом языке может переводиться совершенно по-другому. В результате смысл всего текста искажается, причем не всегда новый (неправильный) смысл идет вразрез с логикой.
Например, слово ”sympathy“ переводится как «сочувствие», а вовсе не как «симпатия», а когда используется слово ”conductor“, то речь идет не о кондукторе общественного транспорта, а о дирижере.

Устный перевод требует опыта восприятия речи на слух
5. Путаница существительных с именами собственными
Часто казусы возникают из-за того, что переводчик не может определить, является слово обычным существительным (иной частью речи) или же именем собственным (фамилией, названием населенного пункта, заведения, пр.). Особенно сложно это понять, когда слово стоит первым в предложении и, соответственно, пишется с большой буквы. Имена собственные не переводятся, однако многие из них имеют такое же написание, как и обычные существительные.
Например, название Field Museum of Natural History in Chicago означает не «Полевой музей натуральной истории», а «Музей естественной истории (имени) Фильда». Здесь слово ”field“ не должно быть переведено как «поле» («полевой»), а должна применяться транслитерация, поскольку это имя собственное. В подобных случаях не стоит действовать наугад, нужно сверять перевод в справочниках и энциклопедиях.
Заключение
Качество работы переводчика прямо пропорционально его опыту, который приходит в результате продолжительной практики. Хороший переводчик может не только адаптировать текст под особенности языка, на который осуществляется перевод, но также менять сам стиль и формат произведения, подстраиваясь под потребности современного мира. В качестве примера можно привести работы профессиональных переводчиков в области делового языка (проект «Идея»). Бестселлеры мировой литературы по бизнесу были переведены и озвучены, превратившись в сокращенный пересказ, содержащий квинтэссенцию смыслов и идей. Таким образом, благодаря работе переводчиков обычные люди получили новые знания без необходимости перечитывать каждое произведение полностью, а просто слушая запись.
Материал подготовлен Аудио-Реклама.ru
Использование всего текста или его фрагментов, разрешается только со ссылкой на эту страницу.
Названы ошибки онлайн-переводчиков
МОСКВА, 24 июн — ПРАЙМ. Онлайн-переводчики чаще всего допускают ошибки при переводе фраз на нескольких языках и слов, имеющих несколько значений, в результате чего получаются такие курьезы, как «демократическая гимнастика» и «одиннадцать таблеток» вместо «одного раза», говорится в исследовании, которое для РИА Новости подготовила команда технических экспертов браузера Vivaldi.

Как сообщили специалисты, онлайн-переводчики допускают ошибки любого рода: и грамматические, и смысловые, и логические, но «особенно часто встречаются ошибки при переводе специфических слов или имеющих несколько значений». «Там, где человек будет опираться на контекст, машина возьмет наиболее часто применяющийся (по анализу обращений пользователей) вариант», — отмечают авторы исследования.
В качестве примера эксперты приводят ошибку онлайн-переводчика Google Translate, который в июле 2017 года перевел фразу британского кабинета министров «отправление демократических процедур» на немецкий как «demokratische Übung», что дословно означает «демократическая гимнастика».
Также часто компьютерные программы делают ошибки, когда «в итоговом тексте появляются слова на двух языках». Так, согласно проведенному в 2010 году в Нью-Йорке исследованию, при обратном переводе инструкций и этикеток медпрепаратов, в которых оставались слова испанского и английского языков, компьютер мог перевести английское «once» («один раз») как испанское, которое означает «одиннадцать». В результате пациент пил 11 таблеток вместо одной ежедневно, говорится в исследовании. Для медицины подобные неточности опасны.
Ошибки и неточности также возникают, когда онлайн-переводчик опирается на избыточное количество постоянно обновляющихся данных и «своевольничает». Так произошло, например, когда Google Translate в декабре прошлого года перевел фразу Thank you, Mr President («Спасибо, господин президент» – англ.) как «Спасибо, Владимир Владимирович». Позднее эту неточность исправили.
Как отмечают авторы исследования, когда компьютер не знает, как правильнее перевести слово, и производит транслитерацию или когда слово написано с опечатками, в текстах появляются непонятные слова, которые выглядят «как неумело сформированные англицизмы». Например, из-за того, что нейросеть не смогла корректно перевести глагол «blot out» («закрывать что-либо»), появилась фраза: «Она блотировала нападающую, отняла мяч и перехватила инициативу».
Специалисты считают, что помимо ошибок перевода у многих современных онлайн-переводчиков есть «проблемы с сохранением конфиденциальности пользовательских данных о выполненных запросах». Об этом говорит, например, то, что после того, как человек вбивает фразу «где я могу купить билеты в Палермо» в онлайн-переводчик, он начинает везде видеть рекламу авиабилетов до Палермо. В таком случае, как отмечается в исследовании, «сервис продает данные рекламодателям, чтобы те смогли настроить таргет и получить больше клиентов».
Почему Google Translate даёт неправильный перевод в ряде случаев?
Столкнулся со странным поведением Google Translate.
Мне надо собрать небольшой словарь английских слов с переводом. Использую для этого Selenium. Случайно заметил пару слов, перевод которых Google иногда отдаёт неправильно. Причём чёткой закономерности отследить не удалось. Пробовал в качестве драйвера и Chrome и Firefox. Пробовал руками открывать в разных браузерах: Brave, Chrome, IceDragon, Edge — может отдать правильный вариант, может неправильный, причём обновление страницы (без кеша) вариант не меняет. Через Selenium всегда отдаёт неправильный перевод. Пробовал через личный прокси за бугром (без Selenium, руками, браузер на аглицком) — отдаёт неправильный перевод, что опровергает мои мысли будто Google определяет Selenium и подсовывает заведомо ложный вариант.
Причём, в Google Translate два больших окошка. Слева слово источник, справа избранный перевод. Под этими окошками есть ещё «Определения», «Примеры», «Варианты перевода». Всё, что кроме избранного перевода в правом окошке, выдаётся всегда одинаково и без искажений.
Пример: слово «runoff»
Правильный перевод (один из достоверных): «сток»
Неправильный перевод: «посуда»
Формируется вот такой URL:
https://translate.google.com/?sl=en&tl=ru&text=runoff&op=translateЭто могут быть злонамерянные козни или просто какие-то глюки самого Google Translate или их серверной инфраструктуры?
- Вопрос задан более двух лет назад
- 1078 просмотров
12 комментариев
Простой 12 комментариев