Предиктивная аналитика на пальцах
Я занимаюсь Data Science и Machine Learning в компании Redmadrobot. Нас знают в основном как разработчика мобильных приложений, но практика DS и ML в роботах тоже развита.
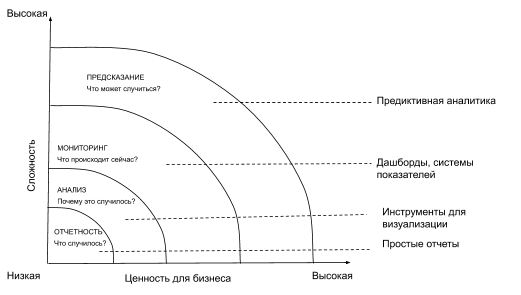
Например, мы делаем предиктивную аналитику: это такой класс методов Data Science, с помощью которого можно предсказать какие-то важные для клиента показатели в будущем. В этой статье я на пальцах объясню, как работает предиктивная аналитика и как именно она помогает, например, просчитать выручку и сэкономить деньги.
К нам приходит, скажем, владелец большой розничной сети с вполне конкретным запросом: хочу знать, где открыть новую точку и сколько выручки я с нее получу. Реально ли это? Вполне.
Сначала мы смотрим, какие данные уже есть у заказчика. Их еще называют внутренними данными.
Внутренние данные
У магазина обычно уже есть какие-то данные по существующим точкам: ассортимент, товарооборот, площадь торгового зала и так далее. Используя только эти данные, мы можем обучить модель и попытаться предсказать, например, выручку для каждой точки: для этого мы делим существующие данные в пропорции 70/30, обучаем модель на 70% данных, а на оставшихся 30% проверяем, насколько точно наша модель научилась предсказывать выручку для точки.
Проблема в том, что точность такой модели может быть невысокой: ей просто не хватает данных для обучения. Другими словами, если у нас есть только внутренние данные от магазинов, этого может быть недостаточно, чтобы с приличной точностью предсказать, сколько магазин будет выручать за месяц.
Что делать в этом случае? Обогащать данные, то есть дополнять то, что уже есть у клиента, внешними данными.
Внешние данные
Внешних данных бывает огромное множество.
Погода, курсы валют, график запуска ракет SpaceX — все это внешние данные по отношению к нашему клиенту.
Понятно, что не все внешние данные нам нужны, и не все из них мы можем достать. На этом этапе к нам подключается аналитик: он хорошо разбирается в типах и источниках внешних данных, и может дать экспертную оценку, какие из них будут релевантны. Перед разработкой модели проводится исследование, которое помогает понять, какие данные нам будут полезны, а какие нет.
В случае с магазином нам могут быть полезны, например, такие данные, как проходимость конкретной точки, какие конкуренты стоят рядом, сколько денег выручают торговые точки в этом районе.
На основе этих гипотез мы можем подтянуть внешние данные и обучить модель, уже используя их. Предсказательная сила в этом случае обычно улучшается. Мы можем обучать модель несколько раз, добавляя и убирая какие-то наборы данных, добиваясь все большей точности.
Как получить внешние данные?
Некоторые сервисы-агрегаторы данных отдают их свободно, иногда даже в удобном формате xml или json — как, например, сервис OpenStreetMap, где можно получить географические данные об объекте. Бывают публичные базы данных, например от Google — это уже собранные большие наборы данных по различным тематикам, которые можно найти в открытом доступе и свободно использовать для обучения своей модели.
Некоторые данные находятся в открытом доступе, но их неудобно использовать. Тогда приходится парсить сайты, то есть вытаскивать данные в автоматическом режиме (до тех пор, пока это законно, конечно — но в большинстве случаев это законно).
А некоторые данные приходится покупать или договариваться об их использовании — например, если работать с операторами фискальных данных, которые могут разрешить использовать некоторую информацию о чеках.
В каждом случае мы решаем, насколько нам нужны эти данные, насколько они повысят точность модели и насколько это важно для заказчика. Предположим, какой-то набор данных позволит нам сделать модель на 10% точнее. Насколько это хорошо для заказчика? Сколько денег он сэкономит или получит, если предсказания нашей модели будут на 10% точнее? Стоит ли это того, чтобы покупать этот набор данных? Чтобы понимать это, нам нужно действительно много знать про клиента — поэтому на этапе понимания задачи мы задаем много вопросов про его бизнес, источники прибыли и особенности работы.
Как проверить точность модели?
Как проверить (и доказать клиенту), что наша модель действительно имеет смысл? Что она предсказывает результат с нужной нам вероятностью?
Делим все данные, которые у нас есть, случайным образом в пропорции 80/20. С 80% мы будем работать и обучать на них модель, это наша тренировочная выборка. 20% пока отложим — они нам понадобятся позже, чтобы проверить на них модель и убедиться, что все работает. Это валидационная выборка.
Тренировочную выборку делим на обучающую и тестовую выборки (70/30). На 70% обучаем модель. На 30% проверяем. Когда точность нас устраивает — проверяем модель теперь уже окончательно, на валидационной выборке, то есть на тех данных, которые модель никогда не видела. Это позволяет нам убедиться, что модель действительно предсказывает с заданной точностью.
Как правило, точность модели на тестовой и валидационной выборке почти совпадает. Если они сильно отличаются — скорее всего, дело в данных: возможно, они были поделены на обучающую и валидационную выборки не случайным образом, либо данные неоднородны.
MVP и промышленное решение
Когда мы обсуждаем с клиентом задачу, мы среди прочего определяем с ним критерии успешности проекта. Как понять, что мы выполнили задачу? Какая точность должна быть у получившейся модели и почему именно такая?
Проект мы всегда начинаем с MVP — это относительно дешевая проверка наших гипотез, это модель, которая уже может приносить ценность. Пробуем обучать модель на имеющихся данных и находим некий baseline — минимальную точность модели (например, 75%). Эту точность мы будем все время стараться повышать — до тех пор, пока это рентабельно и имеет смысл.
Когда точность модели нас наконец устраивает, мы упаковываем получившуюся модель в веб-сервис или мобильное приложение с удобным интерфейсом. В нашем примере с открытием магазина и прогнозированием его выручки веб-сервис мог бы выглядеть как интерактивная карта, где разные районы подсвечивались бы разными цветами в зависимости от перспективности открытия магазина здесь, а для каждой выбранной точки отрисовывалась бы плашка с прогнозом выручки магазина, поставленного в этой точке.
Отличие MVP от промышленного решения в том, что модель MVP не может дообучаться. А точность любой модели со временем деградирует, и ее надо дообучать. Поэтому для промышленного решения мы реализуем один из двух вариантов поддержки: либо мы поддерживаем ее самостоятельно, постоянно дообучая модель (и увеличивая ее точность), либо реализуем цикл переобучения модели непосредственно внутри самого софта.
Поддержка со стороны живой команды, конечно, дороже. Но минус автоматического переобучения в том, что оно не может учесть внезапных изменений характера данных. Оно не учтет, например, что в результате каких-нибудь санкций магазин перестал продавать определенные типы товаров и его выручка снизилась. Тогда точность модели сильно упадет, и ее надо будет переобучать вручную, добавляя недостающие данные.
Предиктивная аналитика: что получаем на выходе
1. Веб-сервис или мобильное приложение с удобным интерфейсом, которое наглядно показывает клиенту ответ на его вопрос (например, где открывать магазин и сколько у него будет выручки).
2. Под капотом — модель, которая с заданной (и оговоренной) точностью выдает предсказания на основе имеющихся данных — внутренних данных клиента и внешних данных, которые мы приняли решение собирать и использовать в этой модели.
3. Поддержку модели, реализованную либо как постоянные доработки модели со стороны живой DS-команды, либо как встроенная функция периодического переобучения внутри самой программы. Модель поддержки выбирается в зависимости от характера данных и бизнес-задач, которую решает модель.
4. Наглядное подтверждение тому, что Data Science и Machine Learning — не просто модные технологии, а инструменты, которые помогают быстро и точно решать реальные задачи бизнеса.
Предиктивная аналитика в маркетинге: где применяется, какой эффект можно получить
Сегодня мы начинаем цикл статей о предиктивной аналитике – современном инструменте прогнозирования продаж и маркетинга. Например, COVID-19 вызвал волну прогнозов: уровень заражения, убытки на фондовом рынке, проблемы цепочки поставок и производства. У этого списка нет конца. Практически невозможно просматривать новости, не увидев еще одного предсказания о том, как мы переживем «новую реальность». Хорошая новость заключается в том, что в неопределенные времена прогнозы могут помочь нам принимать более правильные решения и планировать будущее. В бизнес-аналитике и маркетинге этот процесс называется «предиктивной аналитикой».
Определение предиктивной аналитики
Согласно SAS Institute, предиктивная аналитика — это использование данных, статистических алгоритмов и методов машинного обучения для определения вероятности будущих результатов на основе исторических данных. Цель состоит в том, чтобы не ограничиваться знанием статистики прошлого, а чтобы дать наилучшую оценку того, что произойдет в будущем. Предиктивная аналитика уже является одной из наиболее широко используемых технологий интеллектуальной автоматизации в мире. По данным Statista, более 80% крупных предприятий внедряют предиктивную аналитику.
Эффективный маркетинг всегда заключался в распознавании и предвидении потребностей клиентов. Прогнозный маркетинг включает в себя все инструменты, процессы и правила для применения предиктивной аналитики на основе искусственного интеллекта к стратегиям продаж и маркетинга. Он работает путем сбора и анализа данных о клиентах из растущего списка источников данных, включая CRM-системы, опросы, каналы социальных сетей и другие платформы взаимодействия с клиентами. Эти знания затем применяются ко всему маркетинговому процессу, охватывающему все этапы взаимодействия с клиентом и каждый канал коммуникации бренда, чтобы определить будущие риски и возможности. Компании, успешно внедрившие предиктивную аналитику вместе с технологией машинного обучения, понимают, что только сбор и хранение данных не даст никаких действенных идей для эффективных продаж и маркетинга.
Области применения предиктивной аналитики
Вот некоторые из областей, в которых машинное обучение и предиктивная аналитика окажут серьезное влияние:
— Бюджетирование — компании могут использовать предиктивную аналитику для более точного прогнозирования своих бюджетных потребностей, вместо того, чтобы строить предположения и полагаться на старые модели «что, если». В результате повысится качество финансового планирования и сотрудничества между отделами.
— Прогнозирование действий клиентов — как упоминалось выше, расширенная аналитика может помочь предприятиям получить действенную информацию о клиентах, предсказывая будущие действия потребителей. Компании могут использовать эту информацию для создания более качественных продуктов/услуг, специально предназначенных для своих клиентов. Точно так же компании могут применять этот принцип для увеличения коэффициента конверсии, а также для улучшения отдачи от клиентов, программы вознаграждений и многого другого.
— Снижение затрат. По мере того, как жизненный цикл клиента становится короче и усложняется, внедрение прогнозной аналитики и технологий машинного обучения поможет компаниям проводить более эффективные маркетинговые кампании, что приведет к сокращению расходов и увеличению доходов.
— Перспективное планирование. Бизнес-организации могут внедрять прогнозную аналитику, чтобы получить представление о будущем успехе своих новых продуктов и/или услуг. Это особенно полезно, когда доступных исторических данных недостаточно для прогнозирования или когда прошлое не указывает на будущее. Прогнозная аналитика помогает компаниям принимать обоснованные решения без учета прошлого опыта.
Предиктивная аналитика в маркетинге
В упрощенном виде предиктивная аналитика работает в маркетинге через регрессионный анализ. При регрессионном анализе аналитик берет две переменные и рассчитывает коэффициент регрессии, чтобы определить шансы того, что клиент купит продукт. Например, можно использовать уровень дохода и спрос на продукт для расчета коэффициента регрессии. Если между двумя переменными существует сильная связь, это указывает на то, что уровень дохода является важным фактором спроса на продукцию. Можно построить анализ на множестве переменных, учитывая совокупность факторов влияния на определенный признак (например, как возраст и доход влияют на размер среднего чека).
Однако наблюдение за основными факторами, влияющими на потребительский спрос, — это лишь верхушка айсберга. С помощью предиктивной аналитики можно отображать ретроспективные данные и прогнозировать будущие тенденции покупок. Независимо от того, занимаетесь ли вы маркетингом B2B или B2C, вы можете предвидеть, что потребители купят, еще до совершения покупки. Другими словами, вы можете легко идентифицировать ценных клиентов еще до того, как они совершат покупку у вас на сайте.
Инвестируя в предиктивную аналитику, вы можете более эффективно выполнять несколько функций. Одна из них — сегментация клиентов, которая включает в себя разделение клиентов на разные сегменты для более точных маркетинговых кампаний.
Также возможно исключить неэффективные процессы и уменьшить отток. Вы можете лучше понять клиентов и разработать маркетинговые кампании, которые не позволят им уйти. Также появляется возможность автоматизировать маркетинговые процессы, чтобы сократить расходы и сэкономить время.
Модели предиктивной аналитики в маркетинге
Предиктивная аналитика определяет новые маркетинговые возможности с помощью трех различных моделей:
— Модель склонности: платформы аналитики могут использовать исторические данные, чтобы увидеть вероятность того, что конкретный покупатель завершит покупку. Мало того — можно определить вероятность того, что клиент совершит другие действия, такие как подписка, отказ от подписки, оплата услуг более высокого уровня в продуктовой линейке и многое другое.
— Совместная фильтрация: предиктивная аналитика может предугадывать тип продуктов и услуг, которые клиент, скорее всего, купит, на основе истории покупок. Таким образом, предоставляется хорошая возможность для допродажи и перекрестных продаж. Цифровые гиганты, такие как Amazon и Netflix, используют совместную фильтрацию для продажи дополнительных продуктов и услуг.
— Кластерная модель: с помощью этой модели вы можете разделить клиентскую базу на разные нишевые сегменты на основе любой переменной, такой как возраст, уровень дохода, демографические данные и средний объем заказа. Существует несколько различных кластерных моделей, включая кластеризацию на основе бренда, кластеризацию на основе продукта и кластеризацию по поведению.
Ключевые выводы
Предиктивная аналитика — перспективный инструмент, который изменит маркетинг, поскольку он способен брать исторические данные и использовать их для прогнозирования будущего. Будь то цифровой или традиционный маркетинг, аналитика может обеспечить более глубокое понимание, позволяя вам более точно формировать потребительские профили клиентов, превентивно выявлять ценных клиентов и применять точные маркетинговые методы, которые обеспечат более высокую рентабельность инвестиций в маркетинговые усилия.
Более детально мы рассмотрим предиктивную аналитику в следующих публикациях.
Обращаем ваше внимание, что данными технологиями мы владеем. Будет интерес — обращайтесь, обсудим, чем можем быть полезны для вас.
Прогнозирование осуществляется с помощью пакета SPSS.
Предикативная аналитика: как предсказать эпидемию и успех в бизнесе

Предикативная (или предиктивная, прогнозная) аналитика — это прогнозирование, основанное на исторических данных. С помощью статистических инструментов можно выявить закономерности в изменениях показателей в предыдущих периодах и предсказать, как они будут вести себя в будущем. Например, проанализировав котировки акций, можно просчитать обвал или изменение цен. Банки используют предикативную аналитику, когда оценивают заемщика, анализируя финансовые показатели и рассчитывая вероятность того, что клиент не сможет выплатить кредит.
Крупные компании создают целые отделы, занимающиеся предикативной аналитикой. Они преследуют разные цели — от оптимизации затрат на рекламу до повышения эффективности производства. Считается, что из всех видов бизнес-аналитики именно предикативная аналитика приносит наибольшую выгоду компаниям.
Как строится процесс
Скорость распространения коронавируса в мире
Случаев за сутки
Источник: JHU
Данные по миру i
Большие данные появляются постоянно — их генерируют компании, устройства и мы сами, когда пользуемся смартфонами и компьютерами, делаем покупки и путешествуем. Кроме того, они легко собираются и оцифровываются: например, если раньше мы покупали продукты на рынках и расплачивались наличными, то теперь чаще оплачиваем товары банковскими картами или делаем заказы в интернет-магазине.

- генерируемые в интернете — посещаемость сайтов, данные о покупках в интернет-магазинах, «лайки»;
- корпоративная информация — транзакции, отчеты о звонках в компанию, количестве покупателей;
- показания приборов — сведения из различных датчиков, телеметрические данные;
- экономические показатели.
Если перечисленные источники уже можно назвать «классическими», то в последние годы компании научились обрабатывать менее очевидные данные: зарплаты игроков американского футбола, содержание фильмов и географические координаты ударов молнии.
Построение прогноза состоит из нескольких этапов:
- Определение цели анализа. От этого будет зависеть, какие именно данные нужно будет собрать.
- Сбор данных из разных источников. Чтобы сделать более точный прогноз, важна их чистота и однообразие. В процессе могут быть введены некорректные значения или произойти сбои программного обеспечения, поэтому задача аналитиков — преобразовать их в подходящий вид.
- Анализ с использованием статистических инструментов. Для этой цели есть готовые решения, но некоторые компании предпочитают создавать софт под собственные нужды.
- Моделирование. На этом этапе часто используется машинное обучение и другие методы с применением искусственного интеллекта. Аналитики выявляют зависимости и факторы, влияющие на поведение показателей, и строят модель с прогнозом.
- Применение на практике. Это финальный этап, когда становится понятно, насколько точным оказался прогноз. В процессе применения модель обучается на новых данных и корректирует прогноз.
Предикативная аналитика не может быть точной на 100%. Иначе, например, биржа не имела бы смысл — каждый мог бы предсказать, как поведут себя те или иные акции. В реальности на каждый бизнес-показатель влияет множество факторов, но точность предикативной модели можно повышать, работая над качеством данных и обучая ее.
Примеры применения предикативной аналитики
Компании анализируют историю покупок и текущую активность клиента. Если по итогам анализа покупатель попадает в сегмент тех, кто потенциально может перейти к конкурентам, то ему могут предложить скидку, бонусы или подарок.

- Управление кадрами
HR-специалисты используют предикативную аналитику, чтобы заранее выявить, кто из работников уволится, кто из кандидатов на вакансию преуспеет, сколько позиций нужно открыть в следующем году, сколько сотрудников воспользуются разными опциями медицинской страховки и т.д. Google использует ее, чтобы сохранить кадры — если аналитика предсказывает, что ценный работник скоро уйдет из компании, ему предлагают повышение или другую должность.
Анализируя данные об использовании оборудования, можно определить, когда оно будет нуждаться в профилактическом ремонте. Так, в феврале Mail.ru Group объявила, что создаст для «Сухого» цифровую платформу предикативной аналитики. Данные о работе промышленного оборудования и параметрах выполнения операций позволят прогнозировать исправность станков и осуществлять их своевременное обслуживание.
В этой сфере прогнозная аналитика используется особенно широко. Например, с ее помощью выявляются мошеннические транзакции. Банки смотрят на данные прошлых лет о нормальном поведении: расходах, обычном времени и географии транзакций. В случае аномалий организация получает уведомление и может запросить у клиента дополнительное подтверждение операции.

Прогнозная аналитика особенно эффективна в интернет-маркетинге, где легко собрать информацию и быстро внести изменения. Она помогает снизить расходы на рекламу, показать объявление, подходящее конкретному пользователю, квалифицировать посетителя сайта как будущего платящего клиента, улучшить клиентский опыт и т.д.
Специалисты сервиса BlueDot в декабре 2019 года определили, что вспышка заболевания будет именно в провинции Хубэй, опубликовав первую научную публикацию, в которой были предсказания о глобальном распространении вируса.

Бывают неожиданные области применения предикативной аналитики с искусственным интеллектом. О них рассказал технический директор Redmadrobot Data Lab Алексей Соколов:
- Спорт. Компания ICEBERG анализирует хоккейные матчи, собирает статистику по игрокам, их владению шайбой и прогнозирует ряд показателей для клубов. Также в Японии был разработан алгоритм, предсказывающий на основе позы игрока место падения шарика для пинг-понга. По словам создателей, точность алгоритма составляет 75%.
- Медицина. Помимо стандартных диагностических задач, предиктивная аналитика используется для разработки лекарств (с ее помощью можно моделировать белки для лечения определенных заболеваний), построения индивидуальных планов лечения и даже для качественной чистки зубов.
- Азартные игры. Долгое время игра в покер считалась недоступной для машины. Сейчас алгоритмы научились блефовать, предсказывать поведение соперников и играть сильнее лучших игроков мира.
«Системы, построенные на машинном обучении, стремительно развиваются. Основная «пища» для алгоритмов такого рода — это данные и вычислительные мощности, и их становится все больше. Через пять лет машинные алгоритмы будут пронизывать все вокруг точно также, как электричество, — добавляет Алексей Соколов. — Скорее всего, государства научатся корректно регулировать интеллектуальные технологии, беспилотные автомобили станут нормой, а в медицине произойдут прорывы, которые позволяют людям жить дольше».
Подписывайтесь и читайте нас в Яндекс.Дзене — технологии, инновации, эко-номика, образование и шеринг в одном канале.
Что реально происходит в предиктивной аналитике на производствах?
Примерно 18 лет я занимаюсь автоматизацией производств и, в частности, прогностическими системами. Авария в турбине обходится в среднем в десятки миллионов рублей и, как правило, затрагивает далеко не только турбину. Отрыв рабочих лопаток турбины может нанести прямого урона на миллиарды, а потом ещё остановить генерацию на срок поставки комплектующих.

Пример такой турбины для понимания масштаба. Источник.
Сейчас это решается регламентным ремонтом и обслуживанием: «раз в год останавливаем и разбираем», «раз в месяц меняем подшипник», «раз в неделю льём сюда масло». Может, некоторые операции излишни, а может, некоторые слишком редки. Но это лучше, чем ничего.
Второй уровень — это обвесить турбину датчиками и следить за их показаниями. Так можно остановить её за несколько часов или дней до предполагаемой аварии — это лучше, чем устранять последствия, но всё равно нужно же успеть к этому моменту заказать элементы под замену. И неожиданная остановка локомотива, например, вполне может означать перепланирование всего графика перевозок.
Третий уровень — это взять исторические данные, взять потоковые данные с датчиков и построить модель их изменения. Это даст точность в недели. Это уже предиктивная аналитика, которую могут позволить себе далеко не все.
К этому можно добавить ещё физическую модель взаимодействий на устройстве.
Как устроена современная предиктивная и предписательная аналитика
- Получить исторические данные с оборудования. Минимум за три месяца, лучше — за полгода–год. Там должен быть поток данных со всех датчиков, поток данных по производственным параметрам и так далее — в общем, не 40 Кб дискретных значений за полгода, а реально гигабайты. Эти данные можно скормить какой-либо матмодели (раньше использовались разные совокупности эвристик, сейчас обучают нейросети на прогнозы), чтобы понять ожидаемое будущее состояние системы на основании прошлого опыта.
- После обучения нейронки дать в модель на вход также текущие данные в реальном времени, чтобы она строила уже реальный прогноз. Затем при каждом регламенте реально оценивать износ элементов и состояние оборудования, чтобы понимать, правильно ли работает модель. Как правило, модель способна далеко не на всё: она может предсказывать случаи, которые уже были на этом оборудовании, достаточно точно, но редко когда удаётся предвидеть новый случай, которого не было в истории.
- К оборудованию строится физическая модель. Точнее, матмодель физических и химических процессов внутри узла. Например, если речь про подшипник, к «слепому» анализу исторических данных добавляется моделирование физических процессов, происходящих с ним. Эти модели в совокупности с предиктивной аналитикой из пункта 2 очень сильно повышают точность прогноза, с одной стороны, — и очень сильно повышают трудоёмкость разработки, с другой.
Более того, два экземпляра одной и той же железки требуют разных физических моделей и работают совершенно по-разному. Первая причина в том, что они физически отличаются: каждый подшипник и каждая другая деталь имеют свои характеристики, укладывающиеся в вилку допусков и достаточно случайно меняющиеся в процессе эксплуатации. Замена элемента приводит к другому поведению системы. Добавьте к этому текущие ремонты, часто меняющие физическую модель, добавьте человеческий фактор по замене комплектующих на глаз точно такие же, только отличающиеся последней цифрой в номере, добавьте возможность некорректного импортозамещения — и вы получите два визуально похожих элемента оборудования, но с данными, неприменимыми друг к другу.
Поэтому нейронка учится именно на данных каждого конкретного элемента оборудования и уточняется физической моделью для данного типа (серии) устройств.
А вторая проблема в эксплуатации. Например, я знаю, что прогностические модели электровозов для российских железных дорог имеют два класса: для южных регионов и северных. То есть один и тот же электровоз будет обсчитываться совершенно в разных физических моделях в зависимости от региона эксплуатации. Знаю, звучит странно, но это реальность производств. Кстати, поэтому в поток данных нужно также добавлять все внешние условия, условия среды, производственных материалов и так далее.
Что получается
Если у вас есть крайне дорогое оборудования типа турбины за миллиард, можно писать к ней собственную модель и делать НИОКРы. Если получится уменьшить вероятность поломок, это окупится.
Если у вас есть серийное дорогое оборудование, обычно к нему либо уже есть типовая физическая модель, либо она достаточно быстро дорабатывается из класса таких физических моделей. Дальше нужно снять исторические данные, обучить нейронку и получить достаточно хороший результат.
Если у вас есть единичное оборудование со средней ценой или много серийного дешёвого оборудования, как правило, такие внедрения не окупаются без готовых физических моделей производителя под железо. У Siemens и Schneider Electric на многие изделия модели есть, например, но они их не дают, а используют у себя для анализа поступающей телеметрии и предсказания ремонтов.
На практике сейчас поменялось то, что появилась возможность существенно дешевле учить нейросети на исторических данных, и это из области искусства постепенно переходит в обыденность. По факту же каждого руководителя производства интересует три простых вещи:
- сколько стоит внедрение;
- какой экономический эффект оно даст;
- какие гарантии может дать вендор.
Внедрение при НИОКРе очень дорогое. Экономический эффект в том, что будет меньше поломок и простоев, но его можно доказать лет так за 5–6 на практике.
Статистику никто не показывает, она очень закрытая у каждого производства.
В итоге остаются области, где уже есть экономический смысл внедрять готовые решения (с небольшой доработкой под конкретное оборудование) — и именно это мы делаем. Сейчас это тяговые электродвигатели, масляные насосы, генераторы, компрессоры и ДВС (там, как правило, треть проекта — адаптация под устройство, но она окупается) и ещё ряд электроагрегатов.
Насколько достоверны прогнозы?
Очень сильно зависит от того, что за модели были, кто внедрял (с каким опытом) и какие данные собирались. Любая аналитика строится на данных. Нет данных — нет аналитики. Я часто вижу, когда компания наверху внедряет какую-то информационную систему, которая должна агрегировать данные, а затем она спускается на места, и вместо интеграции с производственными системами все эти данные начинают вбиваться руками раз в смену. Так прогностика, конечно же, не работает.
Прогнозы часто обогащаются базами знаний экспертов (условно, это техкарты и перенос принципов отказов с одной модели сложного оборудования в другую похожую).
Дальше, надо понимать, что мы говорим про прогнозную аналитику, предсказывают вероятные результаты на основе выявленных тенденций и статистических моделей, полученных с помощью исторических данных и с использованием данных от оборудования, получаемых в реальном масштабе времени. Заказчики ждут предписывающей аналитики, которая позволяет получить оптимальное решение на основе прогнозной аналитики с использованием данных в реальном масштабе времени. То есть мы говорим «что будет», а заказчики ждут «что делать». На деле это требует интеграции с ещё большим количеством систем.
Вся суета вокруг прогноза состояния — попытка уйти от ремонтов по расписанию к ремонтам по требованию. Чем сложнее система, тем более сложная модель — больше влияющих факторов, менее достоверное предсказание. Опять же, каждый раз при внедрении нужно вернуться на 3 месяца назад и включить мониторинг, если этого не было сделано. Может быть и так: «Ну вы пока собирайте данные, через 3 месяца придём».
Стоит ли ожидать достоверных прогнозов от современных систем прогностики (предиктивной аналитики) в ближайшее время? Да. Всё идёт вперёд. Развивается математика. Оцифровка знания экспертов — большая задача, которой занимаются большие компании. Уже есть базы знаний, которые позволяют для каждого типа оборудования иметь бесценный источник знаний, не привлекая людей в каждом конкретном случае.
На текущий момент уровень развития матаппарата и вычислительной техники достаточен для простых систем вроде двигателя, насоса, компрессора. Но пока эти системы плохо работают с более сложными системами. Но это вопрос времени.
Так что, если у вас тяговые электродвигатели или масляные насосы, мы можем помочь с достаточно предсказуемым эффектом. С остальным вернёмся через пару лет. Надеюсь.
- автоматизация
- аналитика
- прогнозы
- оборудование
- производство
- предиктивная аналитика
- Блог компании Холдинг Т1
- Машинное обучение
- Управление проектами
- Инженерные системы