У вас большие запросы!
Точнее, от вашего браузера их поступает слишком много, и сервер VK забил тревогу.
Эта страница была загружена по HTTP, вместо безопасного HTTPS, а значит телепортации обратно не будет.
Обратитесь в поддержку сервиса.
Вы отключили сохранение Cookies, а они нужны, чтобы решить проблему.
Почему-то страница не получила всех данных, а без них она не работает.
Обратитесь в поддержку сервиса.
Вы вернётесь на предыдущую страницу через 5 секунд.
Вернуться назад
Решение задачи в Excel
Создайте документ Excel в своей папке, сохраните его под именем «ЛР3.Проценты по вкладами».
Постройте ряд распределения для приведенных данных (т.е. простую группировку). Для этого проранжируйте банки по величине процентной ставки, используя инструмент Сортировка, и разбейте их на группы.
Число групп определите по формуле Стерджесса: m = 1 + 3.222 * lg N, где N – число изучаемых единиц. При вычислении воспользуйтесь формулой расчета десятичного логарифма (LOG10) из раздела Математические формулы. Помните, что в случае, если число групп имеет дробное значение, то оно всегда округляется до целого в большую сторону.
При вычислении величины интервала групп используйте формулы нахождения минимального (МИН) и максимального (МАКС) значений среди диапазона чисел из раздела Статистические формулы.
Полученная группировка данных изображена на рисунке 3.2.

Рис. 3.2. Группировка банков по величине процентной ставки по валютным вкладам
Постройте гистограмму для полученной группировки (рис. 3.3).

Рис. 3.3. Диаграмма распределения банков по величине процентной ставки по валютным вкладам
Из построенной группировки и диаграммы видно, что:
- размах процентных ставок составляет больше одной единицы от наименьшего значения (5,9%) до наибольшего (7,3%) – это соответственно левая и правая границы диаграммы;
- типичное значение процентной ставки по валютным вкладам для банков Москвы составляет от 6,9 до 7,1%.
При этом распределение данных носит несимметричный характер со смещением вправо. Вычислите показатели центральной тенденции ряда распределения, используя инструмент Анализ данных. Для этого на вкладке Данные выберите команду Анализ данных. Если пакет анализа отсутствует, то необходимо сначала загрузить его. Для этого:
- Нажмите кнопку Microsoft Office
 , а затем щелкните Параметры Excel.
, а затем щелкните Параметры Excel.
- Выберите команду Надстройки и в окне Управление выберите пункт Надстройки Excel.
- Нажмите кнопку Перейти.
- В окне Доступные надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
Совет. Если Пакет анализа отсутствует в списке поля Доступные надстройки, то для проведения поиска нажмите кнопку Обзор. В случае появления сообщения о том, что пакет статистического анализа не установлен на компьютере и предложения установить его, нажмите кнопку Да.
- После загрузки пакета анализа в группе Анализ на вкладке Данные становится доступной команда Анализ данных.
В открывшемся окне выберите Описательная статистика и щелкните OK (рис. 3.4).  Рис. 3.4. Диалоговое окно пакета Анализ данных Для ввода данных в поле Входной интервал выделите мышью исходные данные; для ввода данных в поле Выходной интервал щелкните по любой незаполненной ячейке таблицы. Установите флажок Итоговая статистика и щелкните OK (рис. 3.5).
Рис. 3.4. Диалоговое окно пакета Анализ данных Для ввода данных в поле Входной интервал выделите мышью исходные данные; для ввода данных в поле Выходной интервал щелкните по любой незаполненной ячейке таблицы. Установите флажок Итоговая статистика и щелкните OK (рис. 3.5).  Рис. 3.5. Диалоговое окно «Описательная статистика» На экране появятся следующие данные (рис. 3.6).
Рис. 3.5. Диалоговое окно «Описательная статистика» На экране появятся следующие данные (рис. 3.6). 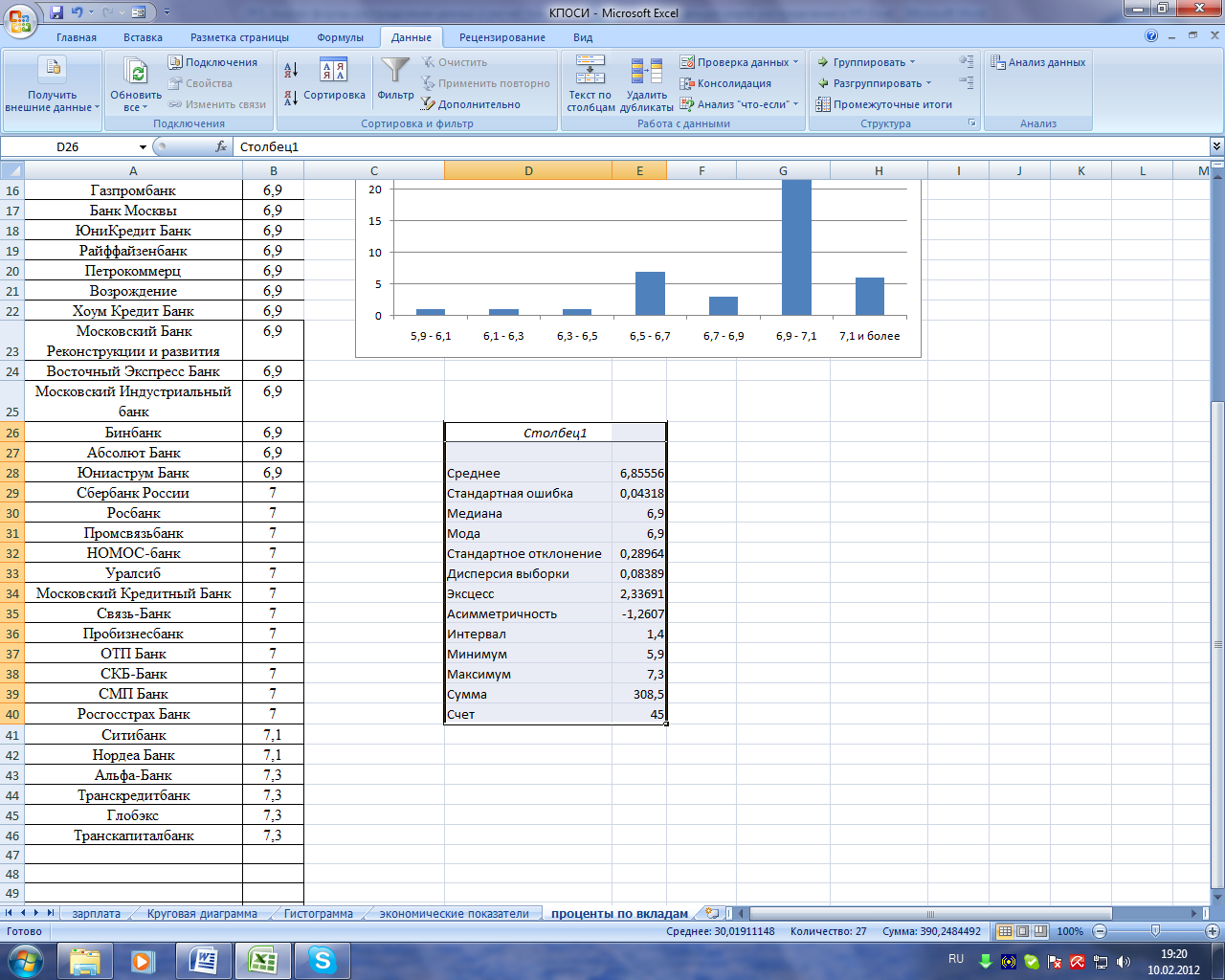 Рис. 3.6. Показатели центральной тенденции ряда распределения банков по величине процентной ставки Из полученного анализа видно, что: 1. в среднем ставка по валютным вкладам в Москве составляет 6,9% с отклонением ±0,3%; 2. размах вариации составляет 1,4 процентной единицы; 3. т.к. AS =
Рис. 3.6. Показатели центральной тенденции ряда распределения банков по величине процентной ставки Из полученного анализа видно, что: 1. в среднем ставка по валютным вкладам в Москве составляет 6,9% с отклонением ±0,3%; 2. размах вариации составляет 1,4 процентной единицы; 3. т.к. AS =  < 0, то в ряду имеет место правосторонняя асимметрия, на это указывает и отрицательное значение показателя Ассиметричность; 4. показатель эксцесса больше нуля, значит распределение островершинное и скачок считается значительным. Оцените однородность данных, рассчитав коэффициент вариации. Сделайте вывод. Сохраните полученные данные.
< 0, то в ряду имеет место правосторонняя асимметрия, на это указывает и отрицательное значение показателя Ассиметричность; 4. показатель эксцесса больше нуля, значит распределение островершинное и скачок считается значительным. Оцените однородность данных, рассчитав коэффициент вариации. Сделайте вывод. Сохраните полученные данные.
Основные статистики в excel.
События, характеризующие данные, могут носить случайный характер и появляться с разной вероятностью.
Вероятность события p есть отношение числа благоприятных исходов m к числу всех возможных исходов n этого события: p=m/n. Например, вероятность появления туза в наугад выбранной карте из колоды в 52 карты равна 4/52=0.0769, так как m=4, а n=52.
Если известно соответствие между появлениями (величинами) x1, x2, …, xn случайного события (переменной) X и соответствующими вероятностями их реализации p1, p2, …, pn, то говорят, что известен закон распределения случайной величины F(x). Большинство встречающихся на практике распределений вероятностей реализовано в Excel.
Распределения вероятностей имеют числовые характеристики.
Функции Excel для вычисления числовых характеристик распределения вероятностей. Они входят в группу Статистические. При вычислении функций в качестве случайных величин используйте следующие значения:

Математическое ожидание случайной величины (среднее арифметическое), характеризующее центр распределения вероятностей, вычисляется функцией СРЗНАЧ. СРЗНАЧ(A1:A7) = 9.
Дисперсия, характеризует разброс случайной величины относительно центра распределения вероятностей и вычисляется функцией ДИСПР. ДИСПР(A1:A7) = 4.857.
Среднеквадратичное отклонение есть квадратный корень из дисперсии, характеризует разброс случайной величины в единицах случайной величины и вычисляется функцией СТАНДОТКЛОНП. СТАНДОТКЛОНП(A1:A7) = 2.203893.
Квантиль случайной величины с законом распределения F(x) есть значение случайной величины x при заданной вероятности p., т.е. есть решение уравнения F(x)=p. Медиана есть квантиль с вероятностью p=0.5.
Excel, вместо квантилей содержит функции вычисления х для определенных уровней р: квартили (кварта – четверть), децили (дециль – десятая часть), персентили (персент – процент). Различают нижний квартиль с вероятностью p=0.25 и верхний квартиль с вероятностью p=0.75. Децили это квантили с вероятностью 0.1, 0.2, …, 0.9.
Функцию КВАРТИЛЬ используют, чтобы разбить данные на группы. В качестве второго аргумента указывают уровень (четверть), для которого нужно вернуть решение: 0 – минимальное значение распределения, 1 – первый, нижний квартиль, 2 – медиана, 3 – третий, верхний квартиль, 4 – максимальное значение. Например, КВАРТИЛЬ(A1:A7;3) = 10, т.е. 75% всех значений меньше 10, КВАРТИЛЬ(A1:A7;2) = 9.
Функция ПЕРСЕНТИЛЬ вычисляет квантиль указанного уровня вероятности и используется для определения порога приемлемости значений. В качестве второго аргумента указывают уровень 0.1, 0.2, …, 0.9. ПЕРСЕНТИЛЬ(A1:A7;0,9) = 11.8, т.е. 90% всех значений меньше 11.8.
Excel содержит инструмент Ранг и персентиль, который на основе набора данных формирует выходную таблицу, содержащую порядковый и процентный ранги для каждого значения в наборе данных. См. справку по F1. Ниже приведен пример установки надстройки Пактет анализа

Распределения вероятностей, реализованные в Excel.
Каждый закон распределения описывает процессы разной вероятностной природы и характеризуется специфическими параметрами:
- равномерное распределение – n случайных чисел выпадает с одной и той же вероятностью p=1/n; характеризуется нижней и верхней границей; примером является появление чисел 1, 2, …, 6 при бросании игральной кости (p=1/6);
- биномиальное распределение моделирует взаимосвязь числа успешных испытаний m и вероятностей успеха каждого испытания p при общем количестве испытаний n — функции БИНОМРАСП и КРИТБИНОМ;
- нормальное (гауссово) распределение описывает процессы, в которых на результат воздействует большое число независимых случайных факторов, среди которых нет сильно выделяющихся – функции НОРМРАСП, НОРМСТРАСП, НОРМОБР, НОРМСТОБР и НОРМАЛИЗАЦИЯ;
- распределение Пуассона, предсказывает число случайных событий на определенном отрезке времени или на определенном пространстве, позволяет аппроксимировать биномиальное распределение – функция ПУАССОН;
- экспоненциальное (показательное) распределение, моделирует временные задержки между событиями, описывает процессы в задачах массового обслуживания и в задачах с «временем жизни» — ЭКСПРАСП;
- распределение хи-квадрат, связано с нормальным, возвращает одностороннюю вероятность распределения и используется для сравнения предполагаемых и наблюдаемых значений – функция ХИ2РАСП;
- распределение Стьюдента, связано с нормальным, возвращает вероятность для t-распределения Стьюдента и используется для проверки гипотез при малом объеме выборки – функция СТЬЮДРАСП;
- F-распределение (Фишера), связано с нормальным и может быть использовано в F-тесте, который сравнивает степени разброса двух множеств данных – fраспобр;
- гамма-распределение используется для изучения случайных величин, имеющих асимметричное распределение, в теории очередей – функция ГАММАРАСП;
- а также другие распределения – функции БЕТАРАСП, ВЕЙБУЛЛ, ОТРБИНОМРАСП, ГИПЕРГЕОМЕТ, ЛОГНОРМРАСП и др.
Биномиальное распределение характеризуется числом успешных испытаний m, вероятностью успеха каждого испытания p и общим количеством испытаний n. Классическим примером использования биномиального распределения является выборочный контроль качества больших партий товара, изделий в торговле, на производстве, когда сплошная проверка невозможна. Из партии выбирают n образцов и регистрируют число бракованных m. Бракованными могут быть 1, 2, … , n образцов, но вероятности реального числа бракованных будут различными. Если контрольная вероятность брака ниже допустимой вероятности, то можно гарантировать достаточное качество всей партии. В Excel функция БИНОМРАСП вычисляет вероятность отдельного значения распределения по заданным m,n и р, а функция КРИТБИНОМ – случайное число по заданной вероятности. Обычно функция КРИТБИНОМ используется для определения наибольшего допустимого числа брака. В качестве примера построим график плотности вероятности биномиального распределения для n=10 (1, 2, …, 10) и p=0.2. Введите исходные данные, как показано на рисунке:  Далее в ячейку В4 введите статистическую функцию БИНОМРАСП и заполните ее параметры как показано на рисунке:
Далее в ячейку В4 введите статистическую функцию БИНОМРАСП и заполните ее параметры как показано на рисунке:  Здесь параметр Число_s есть число успешных испытаний m, Испытания – число независимых испытаний n, Вероятность_s – вероятность успеха каждого испытания p. Параметр Интегральный равен 0, если требуется получить плотность распределения (вероятность для значения m), и равен 1, если требуется получить вероятность с накоплением (вероятность того, что число успешных испытаний не меньше значения аргумента Число_s). Формулу из В4 размножьте в ячейки В5:В13. Ниже показан результат:
Здесь параметр Число_s есть число успешных испытаний m, Испытания – число независимых испытаний n, Вероятность_s – вероятность успеха каждого испытания p. Параметр Интегральный равен 0, если требуется получить плотность распределения (вероятность для значения m), и равен 1, если требуется получить вероятность с накоплением (вероятность того, что число успешных испытаний не меньше значения аргумента Число_s). Формулу из В4 размножьте в ячейки В5:В13. Ниже показан результат:  В колонке В вычислены вероятности успешных испытаний m=1, 2, …, 10. Теперь по диапазону В4:В13 постройте график или гистограмму биномиальной функции плотности распределения – результат на рисунке. Поэкспериментируйте, изменяя значение вероятности в ячейке В1: 0.3, 0.4, 0.8, проследите за изменениями формы графика.
В колонке В вычислены вероятности успешных испытаний m=1, 2, …, 10. Теперь по диапазону В4:В13 постройте график или гистограмму биномиальной функции плотности распределения – результат на рисунке. Поэкспериментируйте, изменяя значение вероятности в ячейке В1: 0.3, 0.4, 0.8, проследите за изменениями формы графика.  Для иллюстрации функции КРИТБИНОМ используем предыдущий пример – необходимо найти число m, для которого вероятность интегрального распределения больше или равна 0.75. Вызовите функцию КРИТБИНОМ и заполните параметры. Вы должны получить значение 3. Это означает, что при вероятности интегрального распределения >= 0.75 будет не менее трех (m>=3) успешных испытаний.
Для иллюстрации функции КРИТБИНОМ используем предыдущий пример – необходимо найти число m, для которого вероятность интегрального распределения больше или равна 0.75. Вызовите функцию КРИТБИНОМ и заполните параметры. Вы должны получить значение 3. Это означает, что при вероятности интегрального распределения >= 0.75 будет не менее трех (m>=3) успешных испытаний. 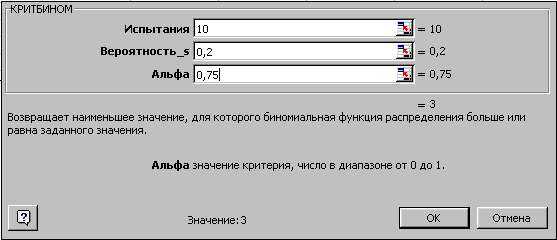 Нормальное распределение характеризуется средним арифметическим (математическим ожиданием) m и стандартным (среднеквадратичным) отклонением r. Дисперсия равна r2 . Краткое обозначение распределения N(m,r2). График нормального распределения симметричен относительно центра распределения (точки m), чем меньше r, тем больше вероятность появления случайной величины. В пределы [m—r,m+r] нормально распределенная случайная величина попадает с вероятностью 0,683 в пределы [m-2r,m+2r] — с вероятностью 0,955 и т.д.
Нормальное распределение характеризуется средним арифметическим (математическим ожиданием) m и стандартным (среднеквадратичным) отклонением r. Дисперсия равна r2 . Краткое обозначение распределения N(m,r2). График нормального распределения симметричен относительно центра распределения (точки m), чем меньше r, тем больше вероятность появления случайной величины. В пределы [m—r,m+r] нормально распределенная случайная величина попадает с вероятностью 0,683 в пределы [m-2r,m+2r] — с вероятностью 0,955 и т.д.  При m=0 и r=1 нормальное распределение называется стандартным или нормированным – N(0,1). Нормальное распределение имеет очень широкий круг приложений. В качестве примера построим график плотности вероятностей нормального распределения при m=15 и r=1,5 в диапазоне [m-3r,m+3r] c шагом 0,5. Результат показан на рисунке.
При m=0 и r=1 нормальное распределение называется стандартным или нормированным – N(0,1). Нормальное распределение имеет очень широкий круг приложений. В качестве примера построим график плотности вероятностей нормального распределения при m=15 и r=1,5 в диапазоне [m-3r,m+3r] c шагом 0,5. Результат показан на рисунке.  Выполните следующие действия:
Выполните следующие действия:
- в ячейку А4 введите формулу =B1-3*B2, в ячейку А5 формулу =A4+B$3 и размножьте ее по ячейку А22;
- в ячейку В4 введите функцию НОРМРАСП из группы Статистические – параметры заполните как на рисунке;
- размножьте формулу из ячейки В4 по ячейку В22 и по диапазону В4:В22 постройте график; на 2-ом шаге мастера диаграмм в закладке Ряд введите подписи к оси х из диапазона А4:А22.

Методические указания по Excel
Для построения теоретической линии и уравнения регрессии подведем курсор мышки к данным графика (фактическим точкам жира), при нажатии на правую клавишу появляется контекстное меню, выберем Добавить линию тренда (рис. 7.7) Рис. 7.7. Контекстное меню для работы с данными. После выбора Добавить линию тренда появляется всплывающее окно с параметрами линии тренда. Так как мы предполагаем, что наша зависимость носит прямолинейный характер, для аппроксимации и сглаживания эмпирической линии выберем Линейная. Выберем автоматическое сглаживание, галочкой укажем показать уравнение на диаграмме и поместить R^2 (рис.7.8). Рис. 7.8. Формат линии тренда. 41
После выбора параметров линии тренда на листе 8 в автоматическом режиме получаем график зависимости между содержанием жира и массой зерна с наименованием осей У. Х и расшифровкой легенды графика (рис. 7,9). На графике голубыми кубиками отмечено фактическое содержание жира, красными ромбиками предсказанное или теоретическое содержание жира. На графике показано уравнение регрессии: Y= 0,34X – 2.68. Как из таблицы на рис.7.5, так и из этого уравнения видно, что коэффициент регрессии составляет 0,34%. Данный коэффициент свидетельствует, что увеличении массы зерна на 1 г, содержание жира увеличивается на 0,34%. Рис. 7.9. График зависимости между содержанием жира и массой зерна. 8. Дисперсионный анализ данных однофакторного вегетационного и полевого опытов с полной рандомизацией вариантов» Работа 10 . Однофакторный дисперсионный анализ Пример. Влияние азотных удобрений на урожайность овса, г/сосуд
| Варианты опыта | Повторность | ||||
| 1 | 2 | 3 | 4 | ||
| 1. | Без удобрения (st) | 15,8 | 15,5 | 16,1 | 15,0 |
| 2. | Аммиачная селитра | 29,3 | 30,4 | 28,1 | 31,6 |
| 3. | Сульфат аммония | 25,8 | 26,8 | 25,9 | 24,7 |
| 4. | Мочевина | 25,7 | 24,0 | 23,8 | 25,7 |
1. В активный лист программы Excel введем исходные данные вышеприведенного примера, расположив таблицу в следующем виде (рис.8.1): 42
Рис. 8.1. Исходные данные 2. Из Пакета анализа выберем инструмент Однофакторный дисперсионный анализ Рис. 8.2. Диалоговое окно Однофакторный дисперсионный анализ . 3. В появившемся окне укажем входной интервал А3:E6. Входной интервал должен включать только диапазон, состоящий из перечня вариантов и цифровых данных по этим вариантам (рис.8.2). 4. Группирование по строкам (рис.8.2). 5. Укажем метки в первом столбце (рис.8.2). Это необходимо для того, чтобы в выходных таблицах автоматически печатались наименования вариантов. 6. Альфа – выбор уровня значимости 0,05 или 0,01 7. Выбираем выходной интервал для размещения результатов дисперсионного анализа: на данном листе или новом листе и нажимаем ОК (рис. 8.2.) 8. Получаем таблицу дисперсионного анализа «Однофакторный дисперсионный анализ» (рис.8. 3.) 43
Рис. 8.3. Таблица дисперсионного анализа 9. В первой итоговой таблице Excel под Группами подразумевается «Варианты», Счет – это повторность каждого варианта (n =4). 10. Во второй таблице термины и формулы подразумевают: Между группами – «Варианты», Внутри групп – «Остаток», SS – сумма квадратов отклонений ( СКО или С y ), df – степени свободы, MS – средний квадрат отклонений или дисперсия – S 2 . 11. F ф = 135,08; F 05 = 3,49 Так как F ф > F 05 , H 0 ≠0, нулевая гипотеза отвергается – в опыте в целом есть существенные различия, поэтому необходимо рассчитать НСР. В Пакете анализа программы Excel, а также в большинстве других статистических пакетов не предусмотрена оценка существенности средних по НСР – четвертый этап дисперсионного анализа, поэтому ошибку разности ( S d ) можно рассчитать для нашего примера следующим образом:
| 2 S | 2 | 2 1,0725 | 0,73 | ||||
| S | e | HCP | =t | 05 | ∙*S | d | = 2,18∙ 0,73 = 1,59 г/ сосуд |
| d | |||||||
| n | 4 | 05 |
t 05 = 2,18 при df (cce) = 12 степенях свободы для остатка К сожалению, необходимо отметить, что в Пакете данных программы Excel невозможно провести дисперсионный анализ как однофакторного полевого опыта, заложенного методом организованных повторений (Работа 11), так и многофакторного полевого опыта с организованными повторениями и расщепленными делянками (Работа 12). Инструменты в Пакете анализа «Двухфакторный дисперсионный анализ с повторениями и без повторений» предназначены для обработки данных двухфакторного вегетационного опыта (опыта с независимыми выборками). 44
9. Дисперсионный анализ данных двухфакторного вегетационного и полевого опытов с полной рандомизацией вариантов. Двухфакторный дисперсионный анализ с повторениями. Пример. В полевом опыте, проведенном методом полной рандомизации (независимые выборки) изучается два фактора: фактор А – полив в 2-х градациях (а 0 – без полива, а 2 – полив), фактор В – дозы минеральных удобрений (в 1 – NPK в 2 – 2NPK в 3 – 3NPK). Опыт проведен в 4- х кратной повторности (n=4). Урожай зерна ячменя в двухфакторном опыте 2х3, ц/га
| Орошение, А | Удобрения, В | ||
| NPK | 2NPK | 3NPK | |
| 24,1 | 28,4 | 28,7 | |
| Без полива | 25,8 | 29,7 | 30,4 |
| 23,0 | 30,1 | 32,0 | |
| 27,0 | 27,4 | 27,0 | |
| 30,7 | 46,7 | 59,4 | |
| Полив | 34,4 | 45,4 | 50,7 |
| 34,0 | 47,1 | 64,5 | |
| 31,0 | 46,3 | 60,1 | |
1. В активный лист программы Excel введем исходные данные вышеприведенного примера, расположив таблицу в следующем виде (рис.9.1): Рис. 9. 1 Исходные данные 2. Из Пакета анализа выберем инструмент Двухфакторный дисперсионный анализ с повторениями 45
3. В появившемся окне укажем входной интервал А1:D9. Входной интервал должен включать только диапазон, состоящий из перечня вариантов и цифровых данных по этим вариантам (рис.9. 2). 4. В окне Число строк для выборки – укажем 4 (это повторность опыта) (рис.9.2). 5. Альфа – выбор уровня значимости 0,05 или 0,01 7. Выбираем выходной интервал для размещения результатов дисперсионного анализа: выбираем на новом листе и нажимаем ОК (рис. 9.2.) 8. Получаем таблицу дисперсионного анализа «Двухфакторный дисперсионный анализ с повторениями» (рис. 9.3.) 46
Рис.9. 3. Таблица дисперсионного анализа 9. В первой итоговой таблице Excel представлены суммы и средние значения по факторам А и В, которые удобнее представить в виде обобщенной таблицы средних по изучаемым вариантам. Счет – это повторность каждого варианта (n =4). 10. Во второй таблице термины и формулы подразумевают: Выборка – «Фактор А», Столбцы – «Фактор В», Взаимодействие – «Взаимодействие АВ», Внутри – «Остаток». SS – сумма квадратов отклонений ( СКО или С y ), df – степени свободы, MS – средний квадрат отклонений или дисперсия – S 2 . 11. С помощью двухфакторного дисперсионного анализа по критерию Фишера оценивается отдельно существенность изучаемых факторов и их взаимодействия. В нашем примере для фактора А F ф = 249,78; F 05 = 4,41 , для фактора В F ф = 60,66; F 05 = 3,55, для взаимодействия АВ F ф = 29,85; F 05 = 3,55. Так как F ф > F 05 , H 0 ≠0, нулевая гипотеза отвергается – действие и взаимодействие полива и удобрений значимо на 5% ном уровне значимости. Для оценки существенности разности средних необходимо рассчитать НСР.
| 2 S 2 | 2 7,8332 | 1,98 | t | S | 2,10 1,98 4,15 | ||
| S | d | e | HCP | d | ц/га. | ||
| n | 4 | 05 | 05 | ||||
t 05 = 2,10 при df (cce) = 18 степенях свободы для остатка 47
| S A | 2 S 2 | 2 7,8332 | 1,14 | HCP A | t | S A 2,10 1,14 2,39 ц/га. | ||||||||||||||
| e | ||||||||||||||||||||
| d | n | b | 4 3 | 05 | 05 | d | ||||||||||||||
| 2 S 2 | ||||||||||||||||||||
| S B | 2 7,8332 | 1,40 | HCP B | t | S A 2,10 1,39 2,93 ц/га. | |||||||||||||||
| e | ||||||||||||||||||||
| d | n | a | 4 2 | 05 | 05 | d | ||||||||||||||
| Итоговая таблица | ||||||||||||||||||||
| Фактор А – | Фактор В – удобрения | В среднем по | ||||||||||||||||||
| полив | NPK | 2NPK | 3NPK | фактору А | ||||||||||||||||
| Без полива | 25,0 | 28,9 | 29,5 | 27,8 | ||||||||||||||||
| Полив | 32,5 | 46,4 | 58,7 | 45,9 | ||||||||||||||||
| В среднем по | 28,8 | 37,6 | 44,1 | |||||||||||||||||
| фактору В | ||||||||||||||||||||
| HCP 4,15 ; HCP A 2,39 | ; HCP B | 2,93 | ||||||||||||||||||
| 05 | 05 | 05 | ||||||||||||||||||
| С помощью HCP 4,15 | оцениваются различия между частными средними (с | |||||||||||||||||||
| 05 | ||||||||||||||||||||
поливом и без полива при разных дозах удобрений: 28,9 – 25, 0; 58,7 – 29,5; 46,4 – 32,5 и т.д.).
| HCP A | 2,39 оценивает только главный эффект фактора А ( 45,9 – 27,8), а | |
| 05 | ||
| HCP B | 2,93 различия главного эффекта фактора В ( 44,1 – 28,8; 37,6 – 28,8; 44,1 – | |
| 05 | ||
| 37,6). | ||
Рекомендуемая литература 1. Microsoft Excel – Викиучебник. http://ru.wikibooks.org/wiki/Microsoft_Excel 2. Макарова Н.В., Трофимец В.Я. Статистика в Excel: Учеб. пособие.– М.: Финансы и статистика, 2002. – 368 с.: ил. 3. Мурашкин С.В., Николаева З.В. Методы учётов и статистическая обработка экспериментальных данных при использовании программы Microsoft Еxcel на примере исследований сосущих вредителей яблони. — Великие Луки: Редакционно-издательский отдел ФГОУ ВПО «Великолукская ГСХА», 2006, 120 с. 4. Обработка экспериментальных данных в MS Excel : методические указания к выполнению лабораторных работ для студентов дневной формы обучения / сост. Е. Г. Агапова, Е. А. Битехтина. – Хабаровск : Изд-во Тихоокеан. гос. унта, 2012. – 32 с. 49
Учебное издание Усманов Раиф Рафикович ВЫПОЛНЕНИЕ ЗАДАНИЙ ПО КУРСУ «ОСНОВЫ НАУЧНЫХ ИССЛЕДОВАНИЙ В АГРОНОМИИ» В ПРОГРАММЕ «EXCEL» Методические указания Подписано в печать 2013 г. Формат Усл. печ. л. Тираж 120 экз. Зак. Издательство РГАУ – МСХА имени К.А. Тимирязева 127550, Москва, Тимирязевская ул., 44 Тел.: 977-00-12, 977-26-90, 977-40-64 50