Save a website to ZIP
Download a landing page, full website, or any page absolutely for free. Add your site’s url to the input box and click «Save» button to get the archive with all files.
Html
CSS & JavaScript
Images
Fonts
Were we able to help you download the site? Press ctrl+d ,
to bookmark the service so that you don’t lose us!
HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Веб-архивы Интернета: как искать удалённую информацию и восстанавливать сайты
Что такое Wayback Machine и Архивы Интернета
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
Какие существуют веб-архивы Интернета
Я знаю о трёх архивах веб-сайтов (если вы знаете больше, то пишите их в комментариях):
- https://web.archive.org/
- http://archive.md/ (также использует домены http://archive.ph/ и http://archive.today/)
- http://web-arhive.ru/
web.archive.org
Этот сервис веб архива ещё известен как Wayback Machine. Имеет разные дополнительные функции, чаще всего используется инструментами по восстановлению сайтов и информации.
Для сохранения страницы в архив перейдите по адресу https://archive.org/web/ введите адрес интересующей вас страницы и нажмите кнопку «SAVE PAGE».

Для просмотра доступных сохранённых версий веб-страницы, перейдите по адресу https://archive.org/web/, введите адрес интересующей вас страницы или домен веб-сайта и нажмите «BROWSE HISTORY»:

В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
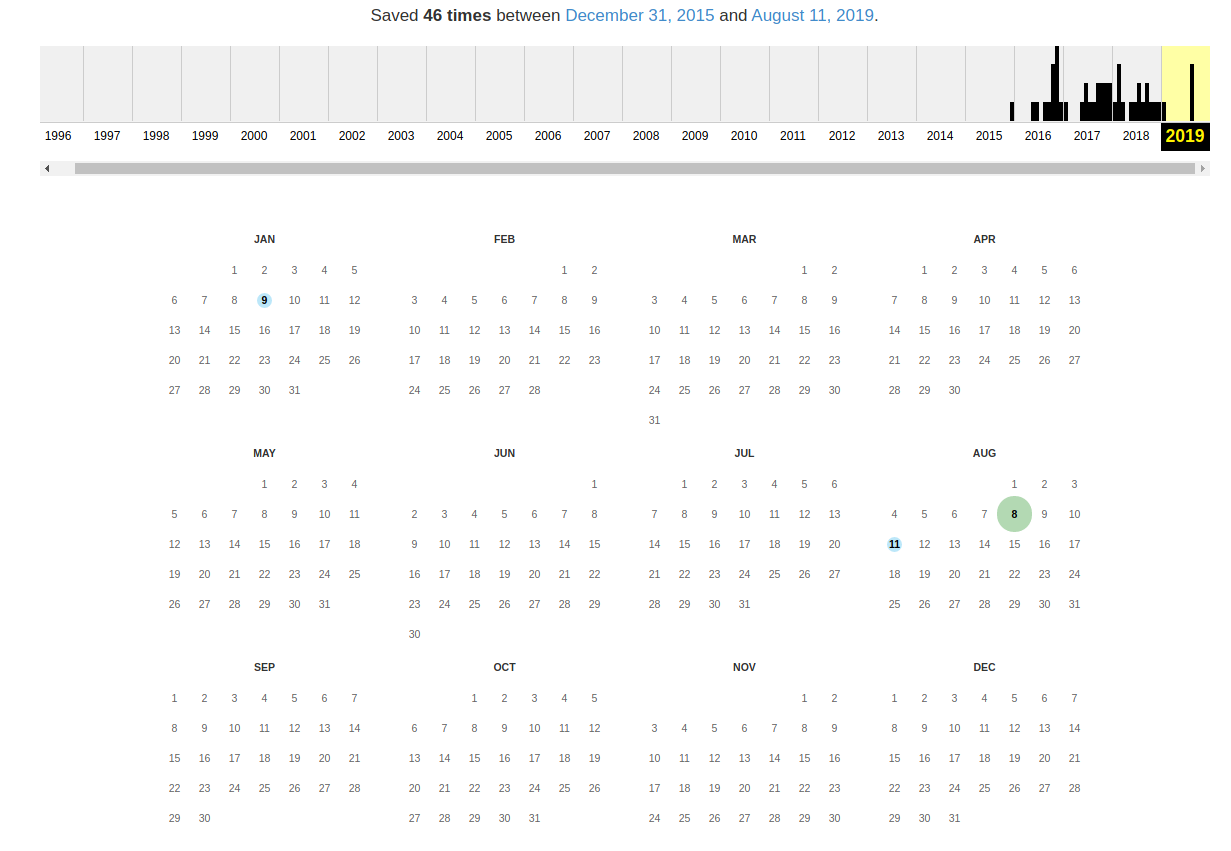
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.

При клике на выбранное время, будет открыта ссылка, например, http://web.archive.org/web/20160803222240/https://hackware.ru/ и вам будет показано, как выглядела страница в то время:

Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
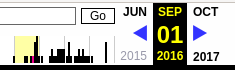
Лучший способ увидеть все файлы, которые были архивированы для определённого сайта, это открыть ссылку вида http://web.archive.org/*/www.yoursite.com/*, например, http://web.archive.org/*/hackware.ru/
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
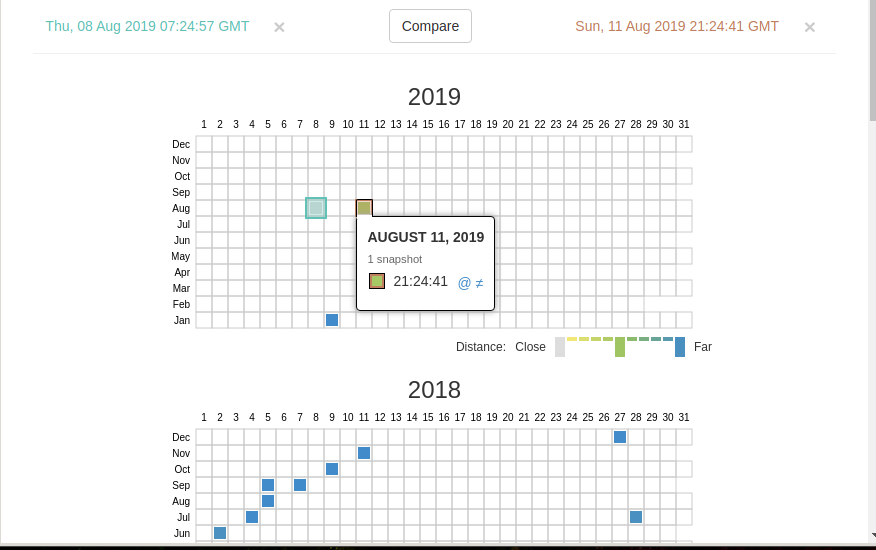
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
Summary
В этой вкладке статистика о количестве изменений MIME-типов.
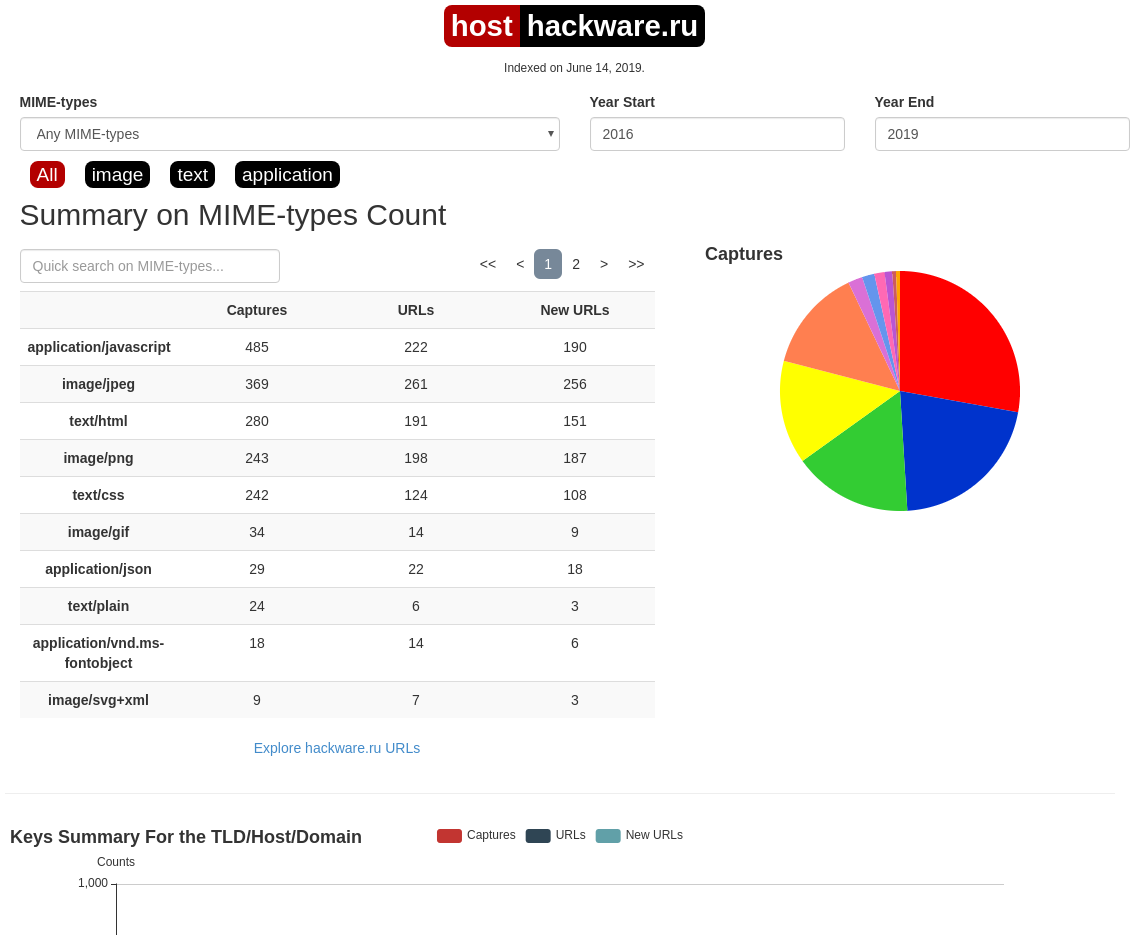
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Поиск по Интернет архиву
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:

Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
archive.md
Адреса данного Архива Интернета:
- http://archive.md
- http://archive.ph/
- http://archive.today/
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы

Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- http://twitter.com/burgerkingfor покажет архив данного url (поиск чувствителен к регистру)
- http://twitter.com/burg* поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
- http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
- http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
- http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
- добавить хэштег (#) с позицией прокрутки в качество которого число между 0 (вершина страницы) и 100 (низ страницы). Например, http://archive.md/dva4n#95%
- выбрать текст на страницы и получить URL с хэштегом, указывающим на этот раздел. Например, http://archive.is/FWVL#selection-1493.0-1493.53
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
web-arhive.ru
Архив интернет (Web archive) — это бесплатный сервис по поиску архивных копий сайтов. С помощью данного сервиса вы можете проверить внешний вид и содержимое страницы в сети интернет на определённую дату.
На момент написания, этот сервис, вроде бы, нормально не работает («Database Exception (#2002)»). Если у вас есть по нему какие-то новости, то пишите их в комментариях.
Поиск сразу по всем Веб-архивам
Может так случиться, что интересующая страница или файл отсутствует в веб архиве. В этом случае можно попытаться найти интересующую сохранённую страницу в другом Архиве Интернета. Специально для этого я сделал довольно простой сервис, который для введённого адреса даёт ссылки на снимки страницы в рассмотренных трёх архивах.

Что делать, если удалённая страница не сохранена ни в одном из архивов?
Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве.
Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести
cache:URL
cache:https://hackware.ru/?p=6045
Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша.
Для просмотра текстовой версии можно использовать ссылку вида:
- http://webcache.googleusercontent.com/search?q=cache:URL&strip=1&vwsrc=0
Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида:
- http://webcache.googleusercontent.com/search?q=cache:URL&strip=0&vwsrc=1
Например, текстовый вид:
Как полностью скачать сайт из веб-архива
Если вы хотите восстановить удалённый сайт, то вам поможет программа Wayback Machine Downloader.
Программа загрузит последнюю версию каждого файла, присутствующего в Архиве Интернета Wayback Machine, и сохранить его в папку вида ./websites/example.com/. Она также пересоздаст структуру директорий и автоматически создаст страницы index.html чтобы скаченный сайт без каких либо изменений можно было бы поместить на веб-сервер Apache или Nginx.
Об установке программы и дополнительных опциях смотрите на странице https://kali.tools/?p=5211
Пример скачивания полной копии сайта suip.biz из веб-архива:
wayback_machine_downloader https://suip.biz
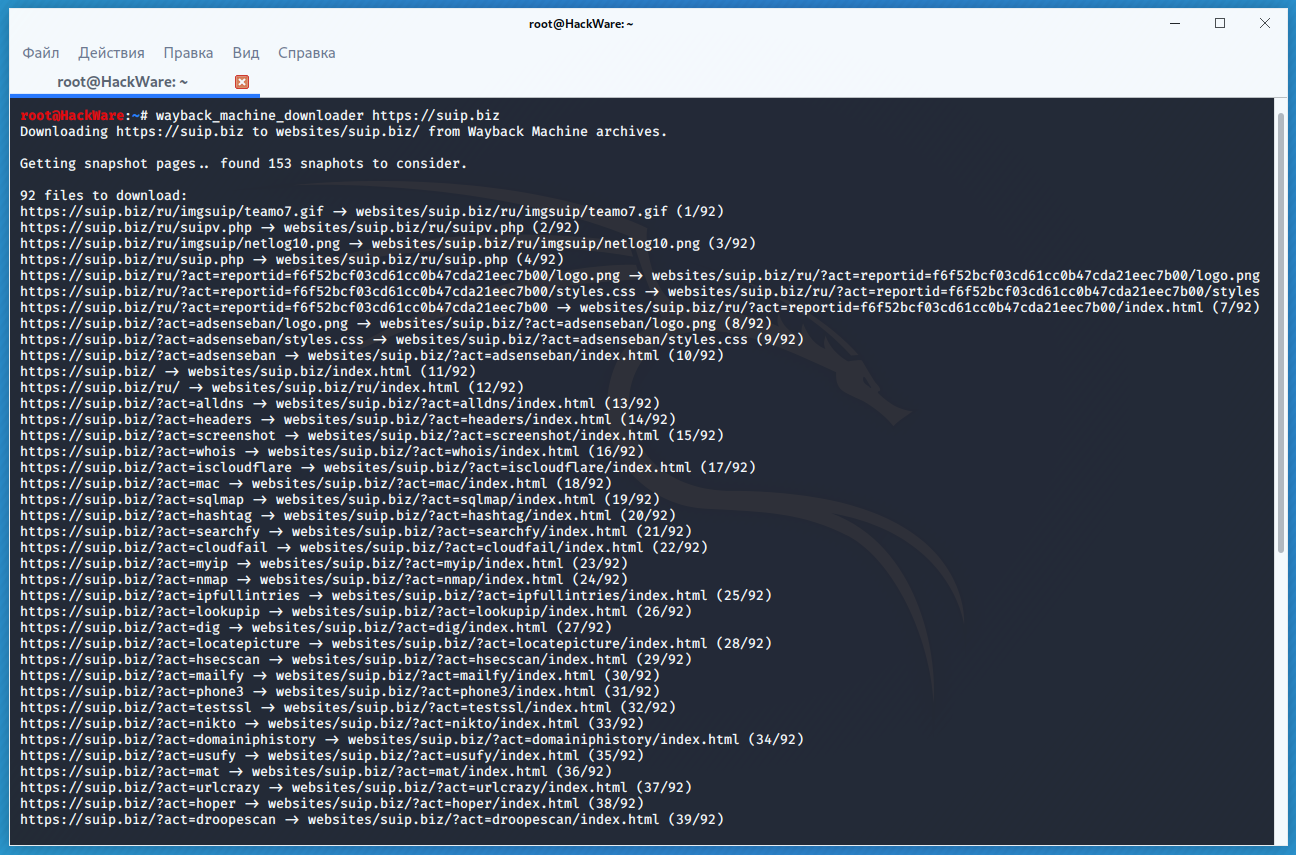
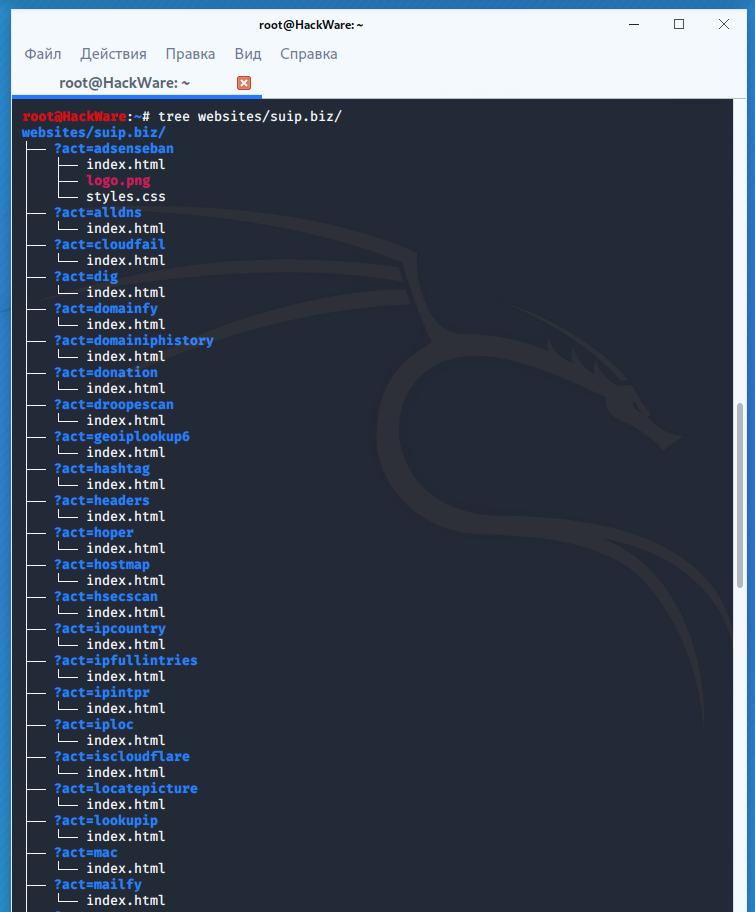
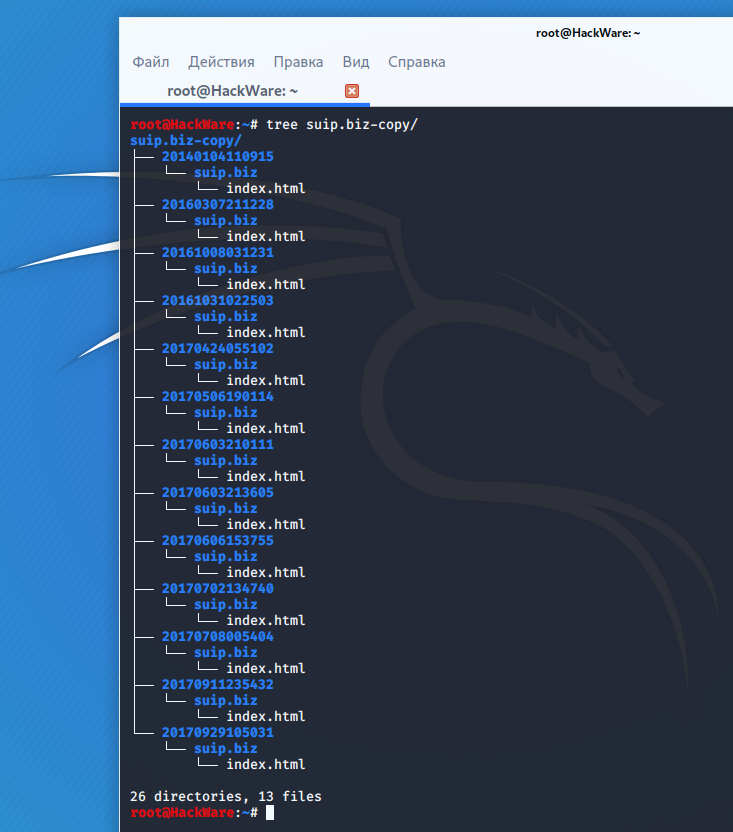
Структура скаченных файлов:
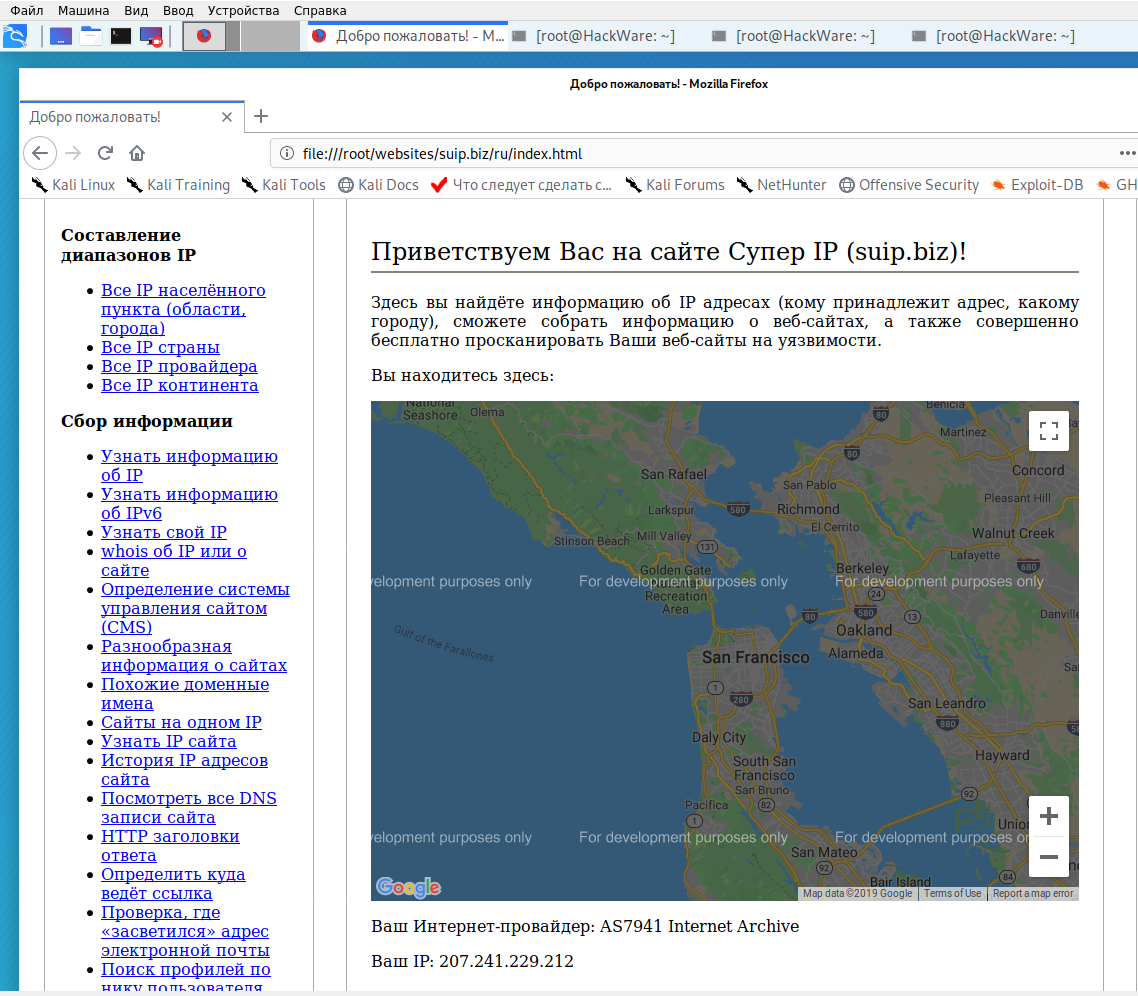
Локальная копия сайта, обратите внимание на провайдера Интернет услуг:
Как скачать все изменения страницы из веб-архива
Если вас интересует не весь сайт, а определённая страница, но при этом вам нужно проследить все изменения на ней, то в этом случае используйте программу Waybackpack.
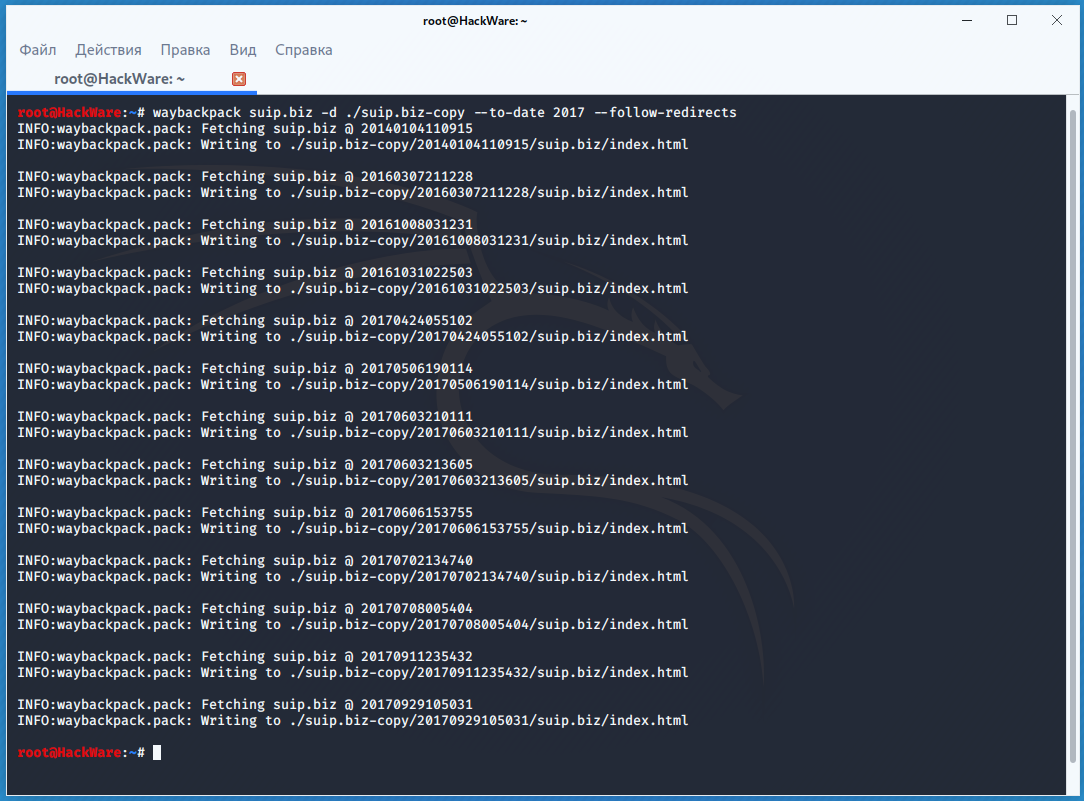
К примеру для скачивания всех копий главной страницы сайта suip.biz, начиная с даты (—to-date 2017), эти страницы должны быть помещены в папку (-d /home/mial/test), при этом программа должна следовать HTTP редиректам (—follow-redirects):
waybackpack suip.biz -d ./suip.biz-copy --to-date 2017 --follow-redirects
Чтобы для указанного сайта (hackware.ru) вывести список всех доступных копий в веб-архиве (—list):
waybackpack hackware.ru --list
Как узнать все страницы сайта, которые сохранены в веб-архиве
Для получения ссылок, которые хранятся в Архиве Интернета, используйте программу waybackurls.
Эта программа извлекает все URL указанного домена, о которых знает Wayback Machine. Это можно использовать для быстрого составления карты сайта.
Чтобы получить список всех страниц о которых знает Wayback Machine для домена suip.biz:
echo suip.biz | waybackurls
Заключение
Предыдущие три программы рассмотрены совсем кратко. Дополнительную информацию об их установке и об имеющихся опциях вы сможете найти по ссылкам на карточки этих программ.
Ещё парочка программ, которые работают с архивом интернета:
- https://github.com/relrelb/wayback-downloader
- https://github.com/erlange/wbm-dl
Связанные статьи:
- Инструкция по использованию HTTrack: создание зеркал сайтов, клонирование страницы входа (79.2%)
- badKarma: Продвинутый набор инструментов для сетевой разведки (79.2%)
- Обход файерволов веб приложений Cloudflare, Incapsula, SUCURI (74.3%)
- FinalRecon: простой и быстрый инструмент для сбора информации о сайте, работает и на Windows (74.3%)
- Сбор информации о владельце сайта. Поиск сайтов одного лица (53.5%)
- Поиск субдоменов (поддоменов) без брут-форса (RANDOM — 53.5%)
факультете информационной безопасности от GeekBrains? Комплексная годовая программа практического обучения с охватом всех основных тем, а также с дополнительными курсами в подарок. По итогам обучения выдаётся свидетельство установленного образца и сертификат. По этой ссылке специальная скидка на любые факультеты и курсы!
Как скачать сайт целиком — обзор способов и средств
В наше время, когда интернет доступен практически в любой момент, иногда возникает необходимость скачать сайт целиком. Зачем это нужно? Причины могут быть разные: и желание сохранить важную информацию на будущее, и необходимость получить доступ к нужным данным при отсутствии доступа в сеть, и возможность ознакомиться с тем, как сверстаны страницы. Могут быть и другие резоны. Важно знать, как выполнить эту задачу, и далее мы покажем несколько способов как сделать копию сайта для последующего его использования в оффлайн режиме.
Способ 1. Постраничное сохранение
Самый простой способ о котором все знают, даже если ни разу не пользовались. Эта возможность есть в любом браузере. Достаточно лишь нажать комбинацию клавиш «Ctrl»+«S», после чего в открывшемся окне отредактировать название сохраняемой страницы и указать папку, в которую ее следует поместить.
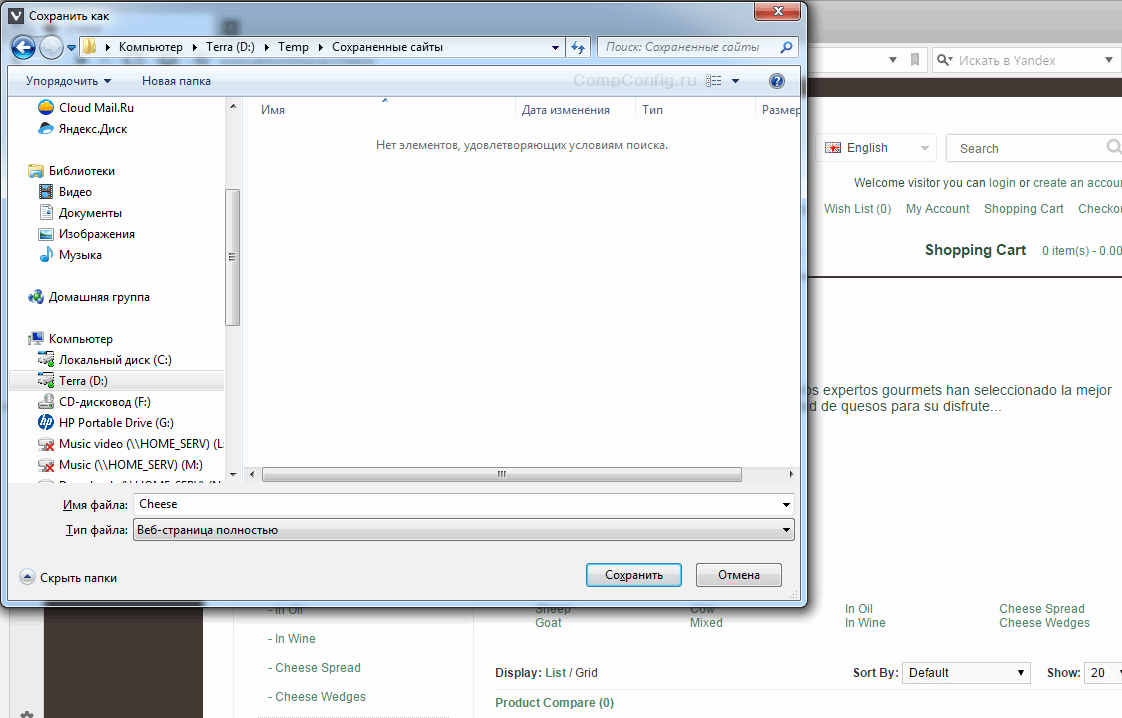
Казалось бы, куда проще. Вот только есть в этом способе один существенный недостаток. Мы скачали всего лишь одну страницу, а в интересующем нас сайте таких страниц может быть весьма большое количество.
Хорошо, если сайт маленький, или состоит всего из одной страницы, а если нет? Придется выполнять это действие для каждый из них. В общем, работа для усидчивых и целеустремленных, не знающих об одном из основных двигателей прогресса.
Способ 2. Использование онлайн-сервисов
Вот оно, самое простое решение. Сейчас много есть полезных онлайн-ресурсов для перекодирования файлов, редактирования аудиофайлов и т. п. Среди достоинств этого метода – кроссплатформенность, отсутствие необходимости захламлять свою операционную систему утилитами, которые, возможно, понадобятся лишь однажды.
Всего делов-то, зайти на такой ресурс, ввести в строку адрес интересующего сайта, нажать кнопку запуска процесса скачивания и подставить «емкость», в которую польется интересующая информация…
В теории так, но, к сожалению, подобных онлайн-ресурсов, позволяющих скачать сайт целиком, раз, два, три и… И, пожалуй, все, если говорить о бесплатной возможности сохранить копию сайта на компьютер. А за все остальное придется платить, или мириться с урезанным функционалом.
Но давайте рассмотрим примеры поближе.
Site2Zip.com
Перестал работать в начале 2019 года.
Едва ли не единственный бесплатный и русскоязычный ресурс. Интерфейс предельно прост. В строке вводим адрес интересующего сайта, вводим капчу, нажимаем кнопку «Скачать» и ждем…
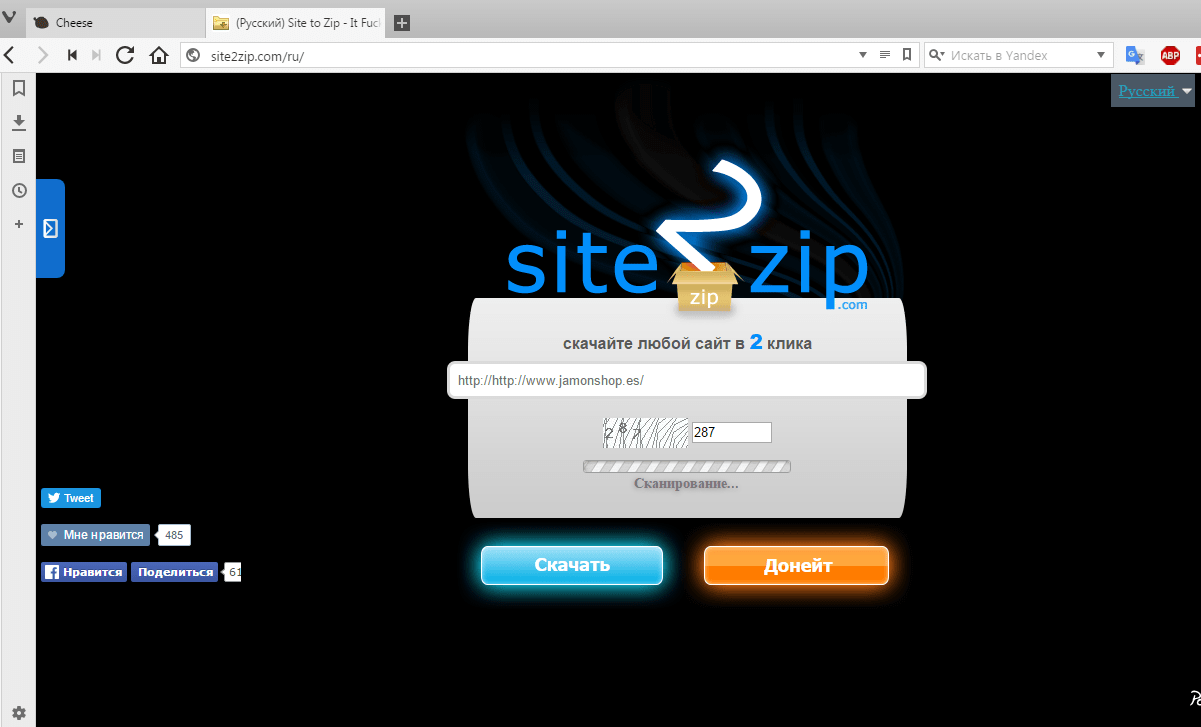
Процесс небыстрый, к тому же с первого раза может и не получиться. Если все удачно, то на выходе получим архив с сайтом.
Webparse.ru
Условно-бесплатный ресурс, позволяющий один раз воспользоваться его услугами бесплатно, после чего за скачивание сайтов придется платить.
Работает webparse.ru быстрее предыдущего ресурса, но делает это не бесплатно. В итоге получаем архив со скачанным сайтом. В настройках нет настройки глубины парсинга структуры скачиваемого сайта, поэтому убедиться, что удалось скачать сайт полностью, придется только самостоятельной сверкой оригинала и его копии.
Другие ресурсы
Среди других способов можно отметить ресурс Web2PDFConvert.com, создающий PDF-файл со страницами скачиваемого сайта. Естественно, часть функционала сайта будет утеряна. Если это допустимо, то воспользоваться данным ресурсом можно.
 Еще один ресурс, позволяющий скачать сайт – r-tools.org. К сожалению, пользоваться им можно только на платной основе.
Еще один ресурс, позволяющий скачать сайт – r-tools.org. К сожалению, пользоваться им можно только на платной основе. 
Способ 3. Специализированные программы
Использование утилит для скачивания файлов — пожалуй, наиболее функциональный вариант, позволяющий добиться своей цели. Придется смириться с тем, что в системе появятся дополнительные программы, одна часть из которых бесплатна, а другая – более меркантильна и требует за выполнение тех же функций поощрение. Причем, бесплатные программы (иногда их еще называют оффлайн-браузерами) по возможностям практически не уступают платным аналогам.
В отличие от онлайн-сервисов, подобная программа работает гораздо быстрее, хотя придется искать подходящую под вашу ОС версию этого ПО. Некоторые программы можно найти не только для ОС Windows, но и для других.
Рассмотрим несколько примеров таких программ.
WinHTTrack WebSite Copier
Одна из самых популярных программ, предназначенных для создания оффлайн-копий сайтов. Справедливости ради надо сказать, что бесплатных аналогов практически нет.
Для того, чтобы пользоваться программой, надо скачать с сайта разработчика подходящую версию, проинсталлировать ее в свою систему и запустить. В первом окне будет предложено выбрать язык интерфейса. Среди всех вариантов есть и русский.
Интерфейс программы прост и запутаться в нем не получится. В первом окне надо указать имя и категорию проекта, а также указать место, где будет храниться скачиваемый сайт.

Теперь надо ввести адрес сайта, который надо скачать. Программа имеет большое количество настроек, где задается глубина просмотра сайта, определяются фильтры, указывающие что скачивать надо, а что – нет. Например, можно запретить скачку изображений, исполняемых файлов и т. п. Настроек много, и если есть необходимость, можно внимательно с ними ознакомиться.
В следующем окне надо нажать кнопку «Готово», после чего остается только дождаться окончания процесса. По окончании в указанной папке будут находиться файлы скачанного сайта. Для того, чтобы открыть его для просмотра необходимо выбрать файл index.htm.
Теперь папку с проектом можно скачивать на любой носитель и просматривать там, где это удобно.
Cyotek WebCopy
Англоязычная программа с солидно выглядящим интерфейсом и большими возможностями по настройке процедуры скачивания сайта. Достаточно только вести адрес интересующего ресурса, указать папку, в которую сохранить скачанные данные и нажать кнопку «Copy Website».
Все, теперь остается дождаться окончания работы программы и в указанном места найти файл «index.htm», который и будет начальной страницей ресурса, который подготовили для оффлайн-просмотра.
Из недостатков можно отметить только отсутствие русификации, а также то, что Cyotek WebCopy работает только на ОС Windows, начиная с версии Vista. Версий под другие ОС нет.
Teleport Pro
Одна из старейших программ, к сожалению, платная. Имеется тестовый период. После установки и запуска появится главное окно, где необходимо указать режим скачивания сайта. Это может быть полная копия, можно сохранить только определенный тип файлов и т. п.
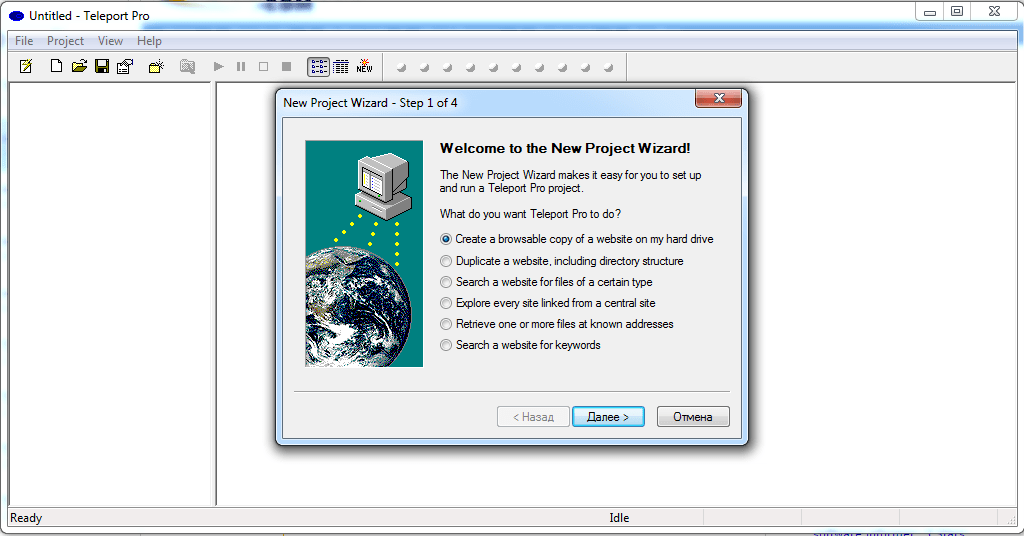
После этого надо создать новый проект, который будет ассоциирован со скачиваемым сайтом и ввести адрес интересующего интернет-ресурса. По умолчанию глубина переходов по страницам имеет значение 3. Этот параметр можно изменить. После этого можно нажать кнопку «Далее».
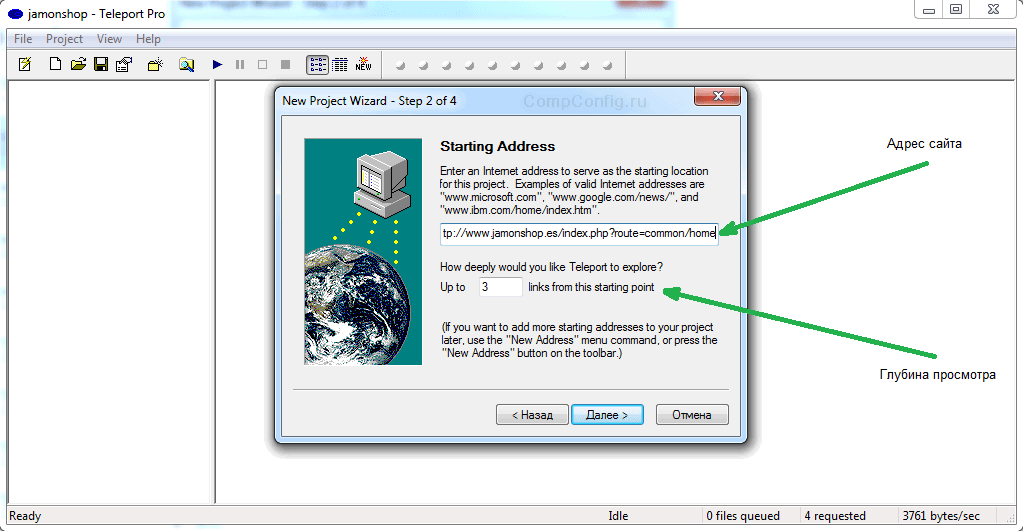
Создастся новый проект, необходимо указать папку, в которую сохранять данные. Для запуска процедуры скачивания надо нажать кнопку «Start» (синий треугольник) в панели управления. Начнется процесс сохранения сайта на ваш диск.
Offline Explorer
Еще одна платная, но весьма функциональная программа. Есть русифицированная версия. Триальная версия работает 30 дней, при этом есть ограничение на количество скачиваемых файлов – 2000. Программа существует разновидностях Standard, Pro и Enterprise. Самая дешевая версия стоит 59.95$, а самая дорогая – 599.95$.
Как и в других программах, работа начинается с того, что необходимо создать новый проект и указать адрес интересующего сайта. Доступно большое количеств настроек, при помощи которых можно отфильтровать ненужную информацию, задать глубину просмотра сайта и т. п.

После того как проект создан, отредактированы параметры загрузки, можно нажать кнопку «Загрузить» и дожидаться результата.
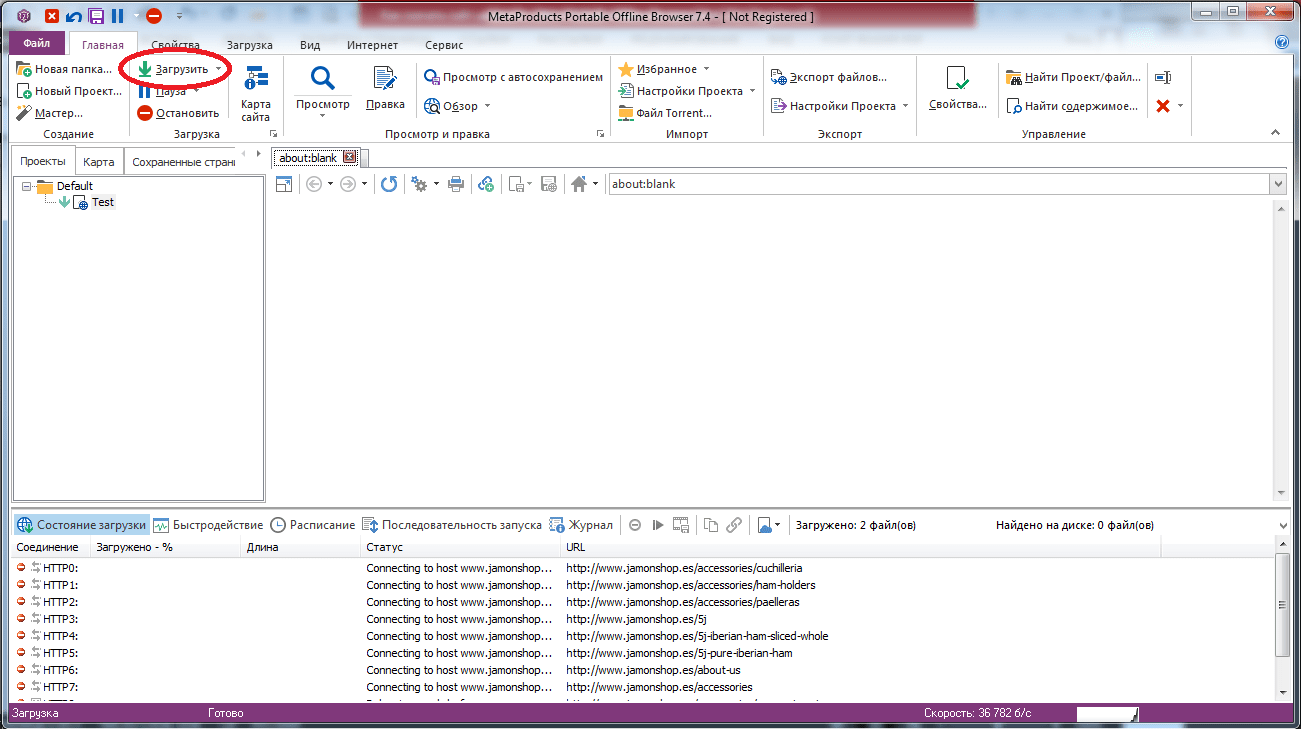
Возможностей у программы действительно много. Есть многопоточная загрузка, собственный веб-сервер для просмотра того, что было скачано, масса настроек. Если оценивать все возможности, то программа действительно ценная (уж простите за тавтологию), вот только стоимость ее неприлично высока.
Webcopier
Платная программа с 15-дневным триальным периодом. Существует в версиях для Windows и Mac OS. Алгоритм работы не отличается оригинальностью, что, впрочем, является плюсом. Для скачивания сайта надо создать новый проект, ввести URL.
 Мастер попросит ответить на несколько вопросов, например, ввести логин и пароль пользователя на скачиваемом сайте, указать папку назначения, позволит изменить некоторые параметры, например, отключить возможность скачивания изображений. После окончания создания проекта для начала процедуры создания локальной копии сайта надо нажать кнопку «Start download». Будет отображаться процесс при помощи графика, показывающего скорость работы, а также время работы.
Мастер попросит ответить на несколько вопросов, например, ввести логин и пароль пользователя на скачиваемом сайте, указать папку назначения, позволит изменить некоторые параметры, например, отключить возможность скачивания изображений. После окончания создания проекта для начала процедуры создания локальной копии сайта надо нажать кнопку «Start download». Будет отображаться процесс при помощи графика, показывающего скорость работы, а также время работы. 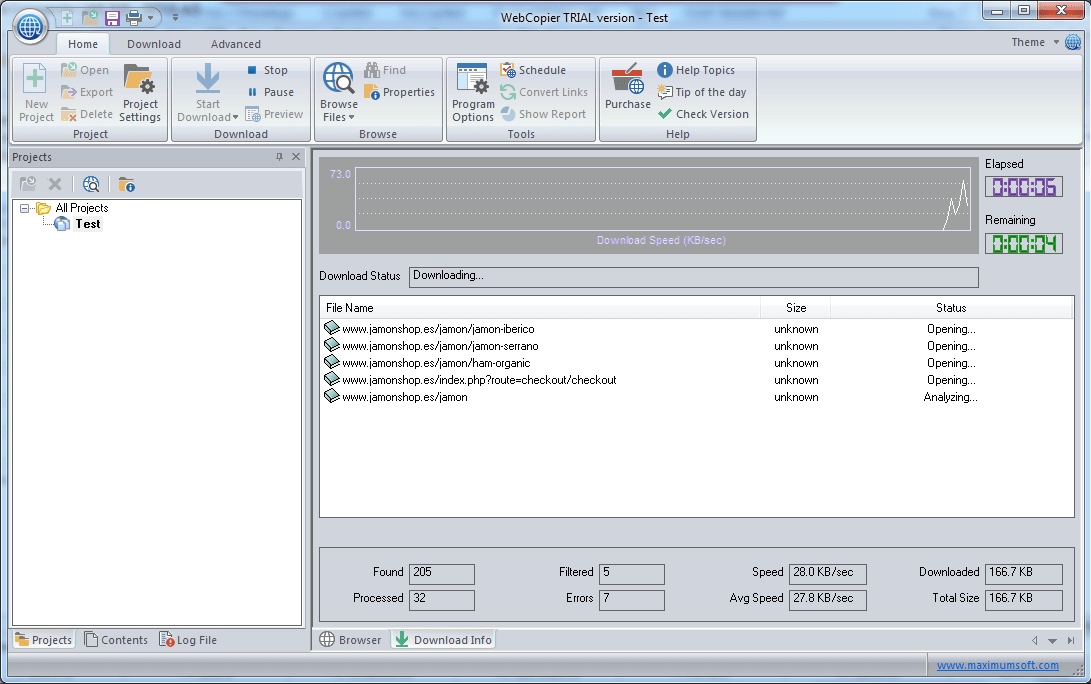
Заключение
Возможностей создать локальную коллекцию нужных сайтов для их просмотра достаточно. Есть и онлайн-ресурсы, есть и специализированное ПО. Каждый из вариантов имеет свои достоинства и недостатки. К сожалению, большинство программ платные, и готовы ли вы раскошелиться за более широкий функционал или достаточно того, что умеют бесплатные утилиты – решать каждому самостоятельно.
Прежде чем отдавать предпочтение тому или иному решению, следует попробовать их все, благо даже платные программы имеют тестовый период, пусть и с некоторыми ограничениями. Это позволит оценить возможности этого ПО, понять, необходим ли вам весь этот функционал, насколько корректно производится скачивание сайтов.
Как скачать сайт полностью на компьютер?
Всем привет подскажите пожалуйста как скачать сайт www.bartek.wojtyca.pl/work/kceto.html себе на комп? Я качал через Teleport Pro, HTTrack но обе программы не полностью его качают! Они не могут скачать папку primary и все что в ней находится!
Жду ваших гениальных предложений!
- Вопрос задан более трёх лет назад
- 370670 просмотров
6 комментариев
Простой 6 комментариев
главный вопрос, зачем.
Saboteur @saboteur_kiev
По ftp не пробовали?
Андрей Васильченко @dron_4r Автор вопроса
Сергей: Это не мой сайт! так что FTP не канает
Андрей Васильченко @dron_4r Автор вопроса
386DX: Что бы был!
Saboteur @saboteur_kiev
Андрей Васильченко: Программы типа teleport pro и так далее устарели по своим алгоритмам, и подходят для примитивных сайтов. Современные динамические сайты адекватно и целиком такими методами скачать невозможно.

те же .php вытянуть не получится
Решения вопроса 0
Ответы на вопрос 13
Olejik2211 @Olejik2211
Чужой лендинг/сайт можно скачать с помощью webcloner.ru, если свой выгрузить хотите с сервера, то в помощь filezilla. Но если конструктор какой: тильда, викс, юкоз, то только через сервисы. Т.к. не дают они выгружать полностью сайт.
Ответ написан более трёх лет назад
Нравится 28 1 комментарий
А каким сервером бользоватся если через конструтор?
Владимир Мартьянов @vilgeforce
Раздолбай и программист
Ответ написан более трёх лет назад
Комментировать
Нравится 24 Комментировать
Попробуйте «Cyotek WebCopy».
www.cyotek.com/cyotek-webcopy
Ответ написан более трёх лет назад
Комментировать
Нравится 12 Комментировать
Чтобы скачать сайт целиком с помощью wget нужно выполнить команду:
wget -r -k -l 7 -p -E -nc http://site.com/
-r — указывает на то, что нужно рекурсивно переходить по ссылкам на сайте, чтобы скачивать страницы.
-k — используется для того, чтобы wget преобразовал все ссылки в скаченных файлах таким образом, чтобы по ним можно было переходить на локальном компьютере (в автономном режиме).
-p — указывает на то, что нужно загрузить все файлы, которые требуются для отображения страниц (изображения, css и т.д.).
-l — определяет максимальную глубину вложенности страниц, которые wget должен скачать (по умолчанию значение равно 5, в примере мы установили 7). В большинстве случаев сайты имеют страницы с большой степенью вложенности и wget может просто «закопаться», скачивая новые страницы. Чтобы этого не произошло можно использовать параметр -l.
-E — добавлять к загруженным файлам расширение .html.
-nc — при использовании данного параметра существующие файлы не будут перезаписаны. Это удобно, когда нужно продолжить загрузку сайта, прерванную в предыдущий раз.
Ответ написан более года назад
Комментировать
Нравится 12 Комментировать
archivarix @archivarix
Можно попровобать еще эту систему скачивания сайтов — https://ru.archivarix.com
Сервис скачитвает сайт онлайн, потом готовый сайт отправляет на емайл в zip файле вместе с CMS. Это будет работоспособный сайт, с лоадером и возможностью редактирования файлов, а не просто набор html файлов и картинок, который обычно получают при скачивании другими даунлоадерами. В этом основное отличие сервиса, по сути дела он импортирует скачиваемый сайт на свою CMS из любой другой, это дает огромные возможности для последующиего редактирования контента, вроде удаления битых ссылок, счетчиков и рекламы, создание новых страниц в скачанном сайте на основе существующих и тд.
Для того, чтобы посмотреть сайт на своем компьютере надо будет поставить локальный Apache сервер, например вот этот — https://www.apachefriends.org/ru/index.html
Ответ написан более трёх лет назад
Нравится 8 2 комментария
Эта программа больше предназначена не для скачивания сайта на комп, а для клонирования сайтов и для скачивания старых сайтов из web.archive.org. В отличие от всех других программ к скаченному сайту идет CMS, хоть и простая но вполне функциональная. Так что полученный контент можно легко подправить под свои нужды.

Руслан @Konovalovrg
archivarix а копируется ли сайт на Тильде с внутренним квизом в нем?
Java Developer
Выкачивал сайты с помощью программы Offline Explorer.
Скачивал без всяких проблем со всеми страницами и ресурсами.
На рутрекере много крякнутых версий данной программы.
Ответ написан более трёх лет назад
Нравится 4 1 комментарий
Андрей Васильченко @dron_4r Автор вопроса
Так же не может скачать!
Пробовал webparse.ru — можно скачать мобильную версию и десктопную. Доступны различные тарифы. Тестовая скачка бесплатна
Ответ написан более трёх лет назад
Нравится 4 1 комментарий
Спасибо большое!!
Web Developer
Есть ещё saveweb2zip.com, можно бесплатно скопировать сайт в архив, а там дальше делай с ним, что хочешь.