Определение ошибки выборки при различных способах отбора
При решении задач выборочного наблюдения обязательным этапом является определение ошибки выборки. Формулы для ее определения разработаны теорией вероятности и математической статистикой.
При собственно-случайном способе отбора обследованию подвергаются единицы совокупности без предварительного систематизирования.
Средняя ошибка выборки для среднего размера признака определяется по формулам 8.1 и 8.2.
При повторном способе:
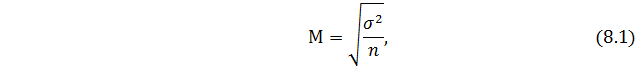
При бесповторном способе:
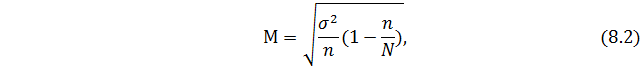
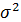
где — дисперсия;
n – объем выборочной совокупности;
N – объем генеральной совокупности.
Предельная (абсолютная ошибка выборки) находится по формуле:

, (8.3)
где t – коэффициент доверия, который определяется по таблице
значений функции Лапласа при заданной
Относительная ошибка выборки определятся с использованием формулы:
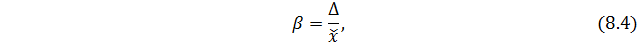
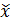
где — среднее значение признака в выборочной совокупности.
Считается, что если β превышает 12%, то погрешность высокая и необходимо увеличить объем выборки.
Зная величину выборочной средней и предельную ошибку выборки, определяется доверительный интервал, в котором находится значение генеральной средней:
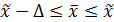 +
+ 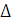 , (8.5)
, (8.5)
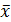
где – средний размер признака в генеральной совокупности.
При проектировании выборочного наблюдения решается задача нахождения необходимой численности выборки, обеспечивающей определенную точность расчета оценок генеральной средней.
Сначала задается величина относительной ошибки выборки (β), затем определяется абсолютная ошибка (Δ) при заданном значении β:
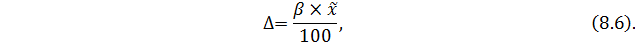
Затем находится объем выборки при повторном способе:
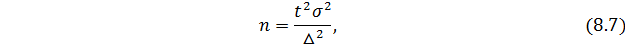
При бесповторном способе объем выборки определяется:
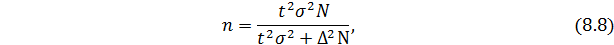
При определении ошибки доли единиц, которые обладают определенным признаком, используется формула:
— при повторном способе:
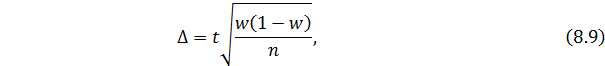
— при бесповторном способе:
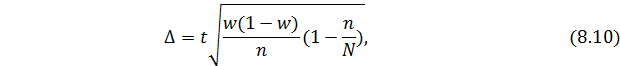
где w – доля единиц, обладающих каким-либо значением признака в
Значение генеральной доли (P) будет находиться в доверительном интервале:
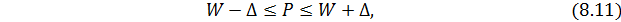
Пример 1. Для определения средней продолжительности междугородних телефонных разговоров из 1300 предоставленных абонентам разговоров в случайном порядке было отобрано 316. Результаты этого наблюдения представлены в таблице 8.1.
| Продолжительность междугородних телефонных разговоров, мин. | Количество разговоров |
| До 3 3-5 5-7 7-9 9-11 11-13 13-15 | |
| Итого |
По данным ряда распределения определить:
— среднюю протяженность разговоров;
— ошибку средней при вероятности 0,99;
— объем выборки при заданном значении β =4%.
Способ отбора бесповторный.
По средней арифметической взвешенной определено, что средняя продолжительность разговоров составляет 6,7 мин., а дисперсия 7,3 мин.
Абсолютная ошибка выборки составит:
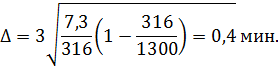
Значение коэффициента доверия t=3 взято из таблицы в зависимости от заданной вероятности равной 0,99.
Относительная ошибка выборки:
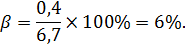
Интервал, в котором находится генеральная средняя:
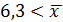
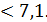
Определяется объем выборки при заданном β=4%.
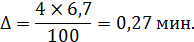
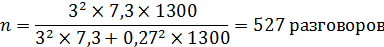
при β=4% необходимо взять в выборку 527 разговоров.
Пример 2. На предприятии работает 1250 человек, проведено бесповторное выборочное наблюдение и отобрано 280 человек, из них 105 человек прошли техническое обучение. Определить долю работников, прошедших техническое обучение при вероятности 0,995. Выборка бесповторная.
Доля работников, прошедших обучение в выборке:
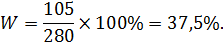
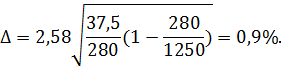
Интервал, в котором находится генеральная доля:
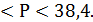
36,6
Относительная ошибка выборки составит:
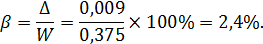
Механический способ отбора отличается от собственно-случайного тем, что исследуемые единицы сначала систематизируются, а потом отбираются или каждая пятая, или десятая единица в группе. Механический способ бывает только бесповторный, а формулы определения ошибки выборки аналогичны собственно-случайному способу.
Серийный способ отбора является групповым способом. Отбор производится случайно, целыми группами или сериями. В отобранных сериях обследованию подвергаются все единицы.
Ошибки средней величины при серийном способе определяются по формулам:
— при повторном способе:
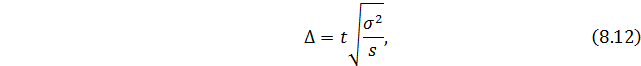
— при бесповторном способе:
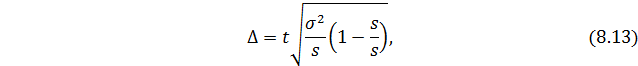
где s – количество серий в выборочной совокупности;
S – количество серий в генеральной совокупности.
Типический способ предполагает, что вначале вся совокупность разбивается на группы по определенному признаку, а затем в каждой группе в случайном порядке отбираются отдельные единицы.
Формула для определения ошибки выборки при этом способе следующая:
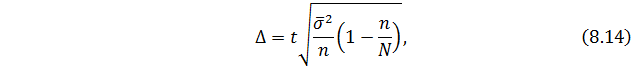
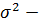
где средняя из групповых дисперсий.
Малой выборкой считается такая выборка, в которой количество отобранных единиц не превышает 20. Ошибка в малой выборке (Δ * ) определяется по формуле:
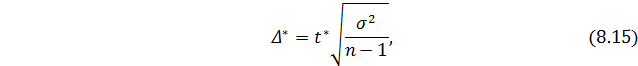
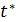
где — коэффициент доверия, который находится по таблице
Стьюдента в зависимости от заданной вероятности и объема
Вопросы для самопроверки
1. Какие существуют способы проведения выборочного наблюдения?
2. Какие факторы влияют на величину ошибки выборки?
3. Каким образом переносятся результаты выборочного наблюдения на генеральную совокупность?
4. Что показывает относительная ошибка выборки?
5. Каким образом находится необходимый объем выборки?
6. Чем отличается расчет ошибки в малой выборке от расчета ошибки, которая находится в большой выборке?
7. С точки зрения достоверности, какая выборка предпочтительнее: бесповторная или повторная?
Тест для самопроверки к теме 8 «Выборочное наблюдение»
1. При определении ошибки выборки откуда берется коэффициент доверия:
1. определяется по формуле
2. определяется по графику
3. находится по специальным таблицам
2. Какая ошибка выборочного наблюдения характеризует величину погрешности:
3. Имеются несколько формул для определения ошибки доли единиц, которые обладают данным признаком. Выбрать правильную формулу (выборка бесповторная):
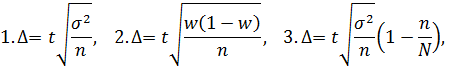
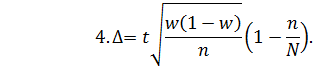
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Ошибки выборки
При правильном формировании выборки величину ее ошибки можно рассчитать заранее. В общем случае под ошибкой выборки понимают объективно возникающее расхождение между характеристиками выборки и генеральной совокупности.
Ошибки выборки подразделяются на ошибки регистрации и ошибки репрезентативности.
Ошибки регистрации возникают из-за неправильных или неточных сведений. Их источником является невнимательность регистратора, неправильное заполнение формуляров, описки или же непонимание существа исследуемого вопроса.
Ошибки репрезентативности возникают вследствие несоответствия структуры выборки структуре генеральной совокупности. Источником их существования является разная вариация признака у статистических единиц, в результате которой распределение единиц в выборочной совокупности отличается от распределения единиц в генеральной совокупности.
Ошибки репрезентативности делятся на систематические и случайные.
Систематические ошибки репрезентативности возникают из-за неправильного формирования выборки, при котором нарушается основной принцип научно организованной выборки – принцип случайности.
Случайные ошибки репрезентативности означают, что даже при соблюдении принципа случайности отбора единиц, расхождения между характеристиками выборки и генеральной совокупности все же имеют место.
Ошибка выборочного наблюдения – это разность между величиной параметра в генеральной совокупности и его величиной, вычисленной по результатам выборочного наблюдения. Для среднего значения ошибка будет определяться так:
хi – вариант (значение варьирующего признака)
N – объем генеральной совокупности (= сумме fi)
хi – вариант (значение варьирующего признака)
n – объем выборочной совокупности
Рассмотрим пример: Даны две 10-ти процентные выборки успеваемости студентов (табл. 6.1).
Таблица 6.1 – Исходные данные
| Оценка | Число студентов | |
| Генеральная совокупность | 1-я выборка | 2-я выборка |
| Итого: |
Рассчитаем ошибку выборки.
1. Средний балл рассчитываем по средней арифметической взвешенной:
По генеральной совокупности:
По выборочным совокупностям:
Разность между показателями выборочной и генеральной совокупности и будет случайной ошибкой репрезентативности:
Величина ошибки выборки зависит от следующих факторов:
— Степени колеблемости признака в генеральной совокупности
Чем однороднее исследуемая совокупность, тем меньше величина средней ошибки при той же самой численности выборки.
— Объема (численности) выборки
Увеличивая или уменьшая объем выборки n, можно регулировать величину средней ошибки. Чем больше единиц будет включено в выборку, тем меньше будет величина ошибки, так как тем точнее в выборке будет представлена генеральная совокупность.
— Способа отбора единиц в выборочную совокупность
Для каждого способа формирования выборки величина ее ошибки определяется по разному. В практической деятельности используются различные способы формирования выборочной совокупности, но принципиальное значение имеет их деление на способы случайного (повторного и бесповторного) отбора.
При собственно случайном повторном отборе общее число единиц генеральной совокупности в процессе выборке не меняется.
Статистическая единица, попавшая в выборку, после регистрации изучаемого признака возвращается в генеральную совокупность и можетвновь попасть в выборку. Таким образом, для всех единиц генеральнойсовокупности обеспечивается равная вероятность отбора.
В математической статистике доказывается, что средняя ошибка выборки определяется по формуле: (6.3)
где — дисперсия генеральной совокупности;
n – объем выборочной совокупности.
Дисперсия – отклонение признака от средней величины. Генеральная дисперсия, также как и остальные параметры генеральной совокупности, является неизвестной величиной, но известно соотношение между генеральной и выборочной дисперсией: ~ , тогда при достаточно большом объеме выборки (n>30), является величиной близкой к 1, и можно считать, что ~ . В случаях малой выборки при n
На практике показатель дисперсии по генеральной совокупности заменяют на аналогичный показатель по выборочной совокупности на базе закона больших чисел. По этому закону выборочная совокупность при достаточно большом ее объеме точно воспроизводит характеристики генеральной совокупности.
где — выборочная дисперсия количественного признака, .
n – объем выборочной совокупности.
Средняя ошибка выборки для доли определяется по формуле: (6.5)
где — выборочная дисперсия доли альтернативного признака,
Применение простой случайной повторной выборки на практике весьма ограниченно. Это связано с тем, что практически нецелесообразно, а иногда и невозможно повторное наблюдение одних и тех же единиц, и поэтому однажды обследованная единица повторному учету не подвергается. Поэтому чаще на практике применяется бесповторный отбор.
При бесповторном собственно случайном отборе общее количество статистических единиц в генеральной совокупности в процессе формирования выборки меняется, уменьшаясь каждый раз на единицу, попавшую в выборку, поскольку отобранные единицы в генеральную совокупность не возвращаются. Таким образом, вероятность попадания отдельных единиц в выборку при бесповторном случайном отборе также меняется (для оставшихся единиц она возрастает). В целом вероятность попадания любой статистической единицы в выборку при бесповторном отборе может быть определена как . На эту величину должна быть скорректирована и средняя ошибка выборки при бесповторном отборе.
Таким образом, расчетные формулы средней ошибки выборки при бесповторном отборе принимают вид:
• для средней количественного признака (6.6)
• для доли альтернативного признака (6.7)
На практике при применении выборочного метода определяются пределы, за которые не выйдет величина конкретной ошибки выборочногоисследования. Величина пределов конкретной ошибки определяетсястепенью вероятности, с которой измеряется ошибка выборки.
Ошибка выборки, исчисленная с заданной степенью вероятности, называется предельной ошибкой выборки.
Предельная ошибка выборки является максимально возможной при данной вероятности ошибкой. Это означает, что с заданной вероятностью гарантируется, что ошибка любой выборки не превысит предельную ошибку. Такая вероятность называется доверительной.
Предельная ошибка выборки рассчитывается по формуле:
где t – коэффициент доверия, значения которого определяются доверительной вероятностью F (t).
Значения коэффициента доверия t задаются в таблицах нормального распределения вероятностей. Чаще всего используются следующие сочетания:
| t | F(t) |
| 0,683 | |
| 1,5 | 0,866 |
| 0,954 | |
| 2,5 | 0,988 |
| 0,997 | |
| 3,5 | 0,999 |
Так, если t = 1, то с вероятностью 0,683 можно утверждать, что расхождение между выборочными характеристиками и параметрами генеральной совокупности не превысит одной средней ошибки.
Предельные ошибки выборки для разных параметров при разных методах отбора статистических единиц рассчитываются по формулам, приведенным в таблице 6.2.
Таблица 6.2 – Формулы расчета предельных ошибок выборки при собственно-случайном отборе единиц выборочной совокупности
| Метод отбора | Предельные ошибки выборки |
| Для средней характеристики | Для доли |
| Повторный | |
| Бесповторный |
Зная величину предельной ошибки выборки, можно рассчитать интервалы, в которых будут находиться характеристики генеральной совокупности:
Пределы, в которых с данной степенью вероятности будет заключена неизвестная величина изучаемого показателя в генеральной совокупности, называют доверительными интервалами, а вероятность F(t) – доверительной вероятностью. Чем выше значение ошибки выборки , тем больше величина доверительного интервала и, следовательно, ниже точность оценки.
Рассмотрим нахождение средних и предельных ошибок выборок, определение доверительных интервалов для средней и доли на следующем примере:
Пример: При оценке спроса на товар А было проведено пятипроцентное бесповторное обследование регионального рынка. При этом было выяснено, что в 90 из 100 обследованных семей данный товар потребляется. В среднем каждая из обследованных семей потребляла 5 единиц товара ( = 5) при стандартном отклонении 0,5 единицы ( =0,5 ед.).
С вероятностью p = 0,954 необходимо установить долю семей, потребляющих данный товар и среднее его потребление (спрос).
Для получения статистических оценок параметров генеральной совокупности выполним следующие процедуры:
1.Определим характеристики выборочной совокупности:
— выборочную долю (удельный вес семей в выборке, потребляющих товар А):
— выборочную среднюю (средний объем потребления товара А одной семьей в выборке): = 5 единиц.
2.Определим предельные ошибки выборки:
для средней
3. Рассчитаем доверительные интервалы характеристик генеральной совокупности:
0,9-0,059 ≤ P ≤ 0,9+0,059,
0,841≤ P ≤ 0,959;
для средней:
Таким образом, с вероятностью 0,954 можно утверждать, что доля семей потребляющих данный товар не меньше 84,1%, но не более 95,9%, а среднее потребление товара в семьях находится в пределах от 4,9 до 5,1 единиц. На основании проведенных расчетов можно определить границы потребления (спроса) товара А на данном рынке:
Таким образом, с вероятностью в 95% можно утверждать, что спрос на товар А не будет ниже 8240 единиц, но и не превысит 9780 единиц.
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Формулы средней ошибки выборки
В связи с тем, что признаки в изучаемой совокупности варьируют, то состав единиц, попавших в выборку, может не совпадать с составом единиц всей совокупности. Это означает, что Р и не совпадают с W и . Возможное расхождение между этими характеристиками определяется ошибкой выборки, которая определяется по формуле:
где — генеральная дисперсия.
где — выборочная дисперсия.
Отсюда видно, где генеральная дисперсия отличается от выборочной дисперсии в раз.
Существует повторный и бесповторный отбор. Сущность повторного отбора состоит в том, что каждая, попавшая в выборку единица, после наблюдения возвращается в генеральную совокупность и может быть исследована повторно. При повторном отборе средняя ошибка выборки рассчитывается:
Для показателя доли альтернативного признака дисперсия выборки определяется по формуле:
На практике повторный отбор применяется редко. При бесповторном отборе, численность генеральной совокупности N в ходе выборки сокращается, формула средней ошибки выборки для количественного признака имеет вид:
Одно из возможных значений, в которых может находиться доля изучаемого признака равно:
где — ошибка выборки альтернативного признака.
При выборочном обследовании 10 % изделий партии готовой продукции по методу без повторного отбора получены следующие данные о содержании влаг в образцах.
| Влажность % | Число образцов | хi |
| До 13 | ||
| 13-15 | ||
| 15-17 | ||
| 17-19 | ||
| 19 и выше |
Определить средний % влажности, дисперсию, среднее квадратическое отклонение, с вероятностью 0,954 возможные пределы, в которых ожидается ср. % влажности всей готовой продукции, с вероятность 0,987 возможные пределы удельного веса стандартной продукции при условии, что к нестандартной партии относятся изделия с влажностью до 13 и выше 19 %.
Лишь с определенной вероятностью можно утверждать, что генеральная доля от выборочной доли и генеральная средняя от выборочной средней, отклоняются в t раз.
В статистике эти отклонения называются предельнымиошибкамивыборки и обозначаются .
Вероятность суждений можно повысить или понизить в t раз. При вероятности 0,683 , при 0,954 , при 0,987 , тогда показатели генеральной совокупности по показателям выборки определяются:
Средний процент влажности генеральной совокупности может быть любым значением, находящемся в пределах от 15,82 до 16,33.
Таким образом, удельный вес стандартных изделий в генеральной совокупности находится в пределах 81 % – 99 %.
Из расчета задачи видно, что возможные пределы удельного веса единиц генеральной совокупности будут находиться:
А среднее значение генеральной совокупности находится в пределах:
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Выборочное наблюдение в статистике

Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ().
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
— при оценивании среднего значения признака;
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
— для среднего значения признака;
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.

Предельная ошибка выборки () равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):

.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:
Итак, определение границ генеральной средней и доли состоит из следующих этапов:
- нахождение в выборке среднего значения признака (или доли);
- определение в соответствии с выбранной схемой отбора и вида выборки;
- задание доверительной вероятности Р и определение коэффициента доверия t по соответствующей таблице;
- вычисление предельной ошибки выборки ;
- построение доверительного интервала для средней (или доли).
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
 Таблица 11.4.
Таблица 11.4.
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., xi | количество предприятий, fi | середина интервала, xi \xb4 | xi \xb4 fi | xi \xb4 2 fi |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Выборочная дисперсия изучаемого признака
- Определяем среднюю ошибку повторной случайной выборки
Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
 Таблица 11.6. Формулы для расчета средней ошибки выборки (
Таблица 11.6. Формулы для расчета средней ошибки выборки ( ) при использовании типического отбора, пропорционального объему типических групп
) при использовании типического отбора, пропорционального объему типических групп
Таблица 11.7.
 1
1
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
- общий объем выборочной совокупности: n = 2550/130*5 =128 (чел.);
аналогично для других групп:
Проведем необходимые расчеты.
- Выборочная средняя, исходя из значений средних типических групп, составит:
С вероятностью 0,954 находим предельную ошибку выборки:
 Таблица 11.8. Формулы для определения численности выборочной совокупности
Таблица 11.8. Формулы для определения численности выборочной совокупности
Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить
При бесповторном случайном отборе потребуется проверить
Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.
Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.