Как найти индекс элемента списка в Python
Изучая программирование на Python, вы практически в самом начале знакомитесь со списками и различными операциями, которые можете выполнять над ними. В этой статье мы бы хотели рассказать об одной из таких операций над списками.
Представьте, что у вас есть список, состоящий из каких-то элементов, и вам нужно определить индекс элемента со значением x . Сегодня мы рассмотрим, как узнать индекс определенного элемента списка в Python.
Но сначала давайте убедимся, что все понимают, что представляет из себя список.
Что такое список в Python?
Список в Python — это встроенный тип данных, который позволяет нам хранить множество различных значений, таких как числа, строки, объекты datetime и так далее.
Важно отметить, что списки упорядочены. Это означает, что последовательность, в которой мы храним значения, важна.
Индексирование списка начинаются с нуля и заканчивается на длине списка минус один. Для получения более подробной информации о списках вы можете обратиться к статье «Списки в Python: полное руководство для начинающих».
Итак, давайте посмотрим на пример списка:
fruits = ["apple", "orange","grapes","guava"] print(type(fruits)) print(fruits[0]) print(fruits[1]) print(fruits[2]) # Результат: # # apple # orange # grapes
Мы создали список из 4 элементов. Первый элемент в списке имеет нулевой индекс, второй элемент — индекс 1, третий элемент — индекс 2, а последний — 3.
Для списка получившихся фруктов fruits допустимыми индексами являются 0, 1, 2 и 3. При этом длина списка равна 4 (в списке 4 элемента). Индекс последнего элемента равен длине списка (4) минус один, то есть как раз 3.
Как определить индекс элемента списка в Python
Итак, как же определить индекс элемента в Python? Давайте представим, что у нас есть элемент списка и нам нужно узнать индекс или позицию этого элемента. Сделать это можно следующим образом:
print(fruits.index('orange')) # 1 print(fruits.index('guava')) # 3 print(fruits.index('banana')) # А здесь выскочит ValueError, потому что в списке нет значения banana
Списки Python предоставляют нам метод index() , с помощью которого можно получить индекс первого вхождения элемента в список, как это показано выше.
Познакомиться с другими методами списков можно в статье «Методы списков Python».
Мы также можем заметить, что метод index() вызовет ошибку VauleError , если мы попытаемся определить индекс элемента, которого нет в исходном списке.
Для получения более подробной информации о методе index() загляните в официальную документацию.
Базовый синтаксис метода index() выглядит так:
где list_var — это исходный список, item — искомый элемент.
Мы также можем указать подсписок для поиска, и синтаксис для этого будет выглядеть следующим образом:
list_var.index(item, start_index_of_sublist, end_index_of_sublist)
Здесь добавляются два аргумента: start_index_of_sublist и end_index_of_sublist . Тут всё просто. start_index_of_sublist обозначает, с какого элемента списка мы хотим начать поиск, а end_index_of_sublist , соответственно, на каком элементе (не включительно) мы хотим закончить.
Чтобы проиллюстрировать это для лучшего понимания, давайте рассмотрим следующий пример.
Предположим, у нас есть список book_shelf_genres , где индекс означает номер полки (индексация начинается с нуля). У нас много полок, среди них есть и полки с учебниками по математике.
Мы хотим узнать, где стоят учебники по математике, но не вообще, а после четвертой полки. Для этого напишем следующую программу:
book_shelf_genres = ["Fiction", "Math", "Non-fiction", "History", "Math", "Coding", "Cooking", "Math"] print(book_shelf_genres.index("Math")) # Результат: # 1
Здесь мы видим проблему. Использование просто метода index() без дополнительных аргументов выдаст первое вхождение элемента в список, но мы хотим знать индекс значения «Math» после полки 4.
Для этого мы используем метод index() и указываем подсписок для поиска. Подсписок начинается с индекса 5 до конца списка book_shelf_genres , как это показано во фрагменте кода ниже:
print(book_shelf_genres.index("Math", 5)) # Результат: # 7
Обратите внимание, что указывать конечный индекс подсписка необязательно.
Чтобы вывести индекс элемента «Math» после полки номер 1 и перед полкой номер 5, мы просто напишем следующее:
print(book_shelf_genres.index("Math", 2, 5)) # Результат: # 4
Как найти индексы всех вхождений элемента в списке
А что, если искомое значение встречается в списке несколько раз и мы хотим узнать индексы всех этих элементов? Метод index() выдаст нам индекс только первого вхождения.
В этом случае мы можем использовать генератор списков:
book_shelf_genres = ["Fiction", "Math", "Non-fiction", "History", "Math", "Coding", \ "Cooking", "Math"] indices = [i for i in range(0, len(book_shelf_genres)) if book_shelf_genres[i]=="Math"] print(indices) # Результат: # [1, 4, 7]
В этом фрагменте кода мы перебираем индексы списка в цикле for и при помощи range(). Далее мы проверяем значение элемента под каждым индексом на равенство « Math «. Если значение элемента — « Math «, мы сохраняем значение индекса в списке.
Все это делается при помощи генератора списка, который позволяет нам перебирать список и выполнять некоторые операции с его элементами. В нашем случае мы принимаем решения на основе значения элемента списка, а в итоге создаем новый список.
Подробнее про генераторы списков можно почитать в статье «Генераторы списков в Python для начинающих».
Благодаря генератору мы получили все номера полок, на которых стоят книги по математике.
Как найти индекс элемента в списке списков
Теперь представьте ситуацию, что у вас есть вложенный список, то есть список, состоящий из других списков. И ваша задача — определить индекс искомого элемента для каждого из подсписков. Сделать это можно следующим образом:
programming_languages = [["C","C++","Java"],\ ["Python","Rust","R"],\ ["JavaScript","Prolog","Python"]] indices = [(i, x.index("Python")) for i, x in enumerate(programming_languages) if "Python" in x] print(indices) # Результат: # [(1, 0), (2, 2)]
Здесь мы используем генератор списков и метод index() , чтобы найти индексы элементов со значением «Python» в каждом из имеющихся подсписков. Что же делает этот код?
Мы передаем список programming_languages методу enumerate() , который просматривает каждый элемент в списке и возвращает кортеж, содержащий индекс и значение элемента списка.
Каждый элемент в списке programming_languages также является списком. Оператор in проверяет, присутствует ли элемент «Python» в этом списке. Если да — мы сохраняем индекс подсписка и индекс элемента «Python» внутри подсписка в виде кортежа.
Результатом программы, как вы можете видеть, является список кортежей. Первый элемент кортежа — индекс подсписка, а второй — индекс искомого элемента в этом подсписке.
Таким образом, (1,0) означает, что подсписок с индексом 1 списка programming_languages имеет элемент «Python» , который расположен по индексу 0. То есть, говоря простыми словами, второй подсписок содержит искомый элемент и этот элемент стоит на первом месте. Не забываем, что в Python индексация идет с нуля.
Как искать индекс элемента, которого, возможно, нет в списке
Бывает, нужно получить индекс элемента, но мы не уверены, есть ли он в списке.
Если попытаться получить индекс элемента, которого нет в списке, метод index() вызовет ошибку ValueError . При отсутствии обработки исключений ValueError вызовет аварийное завершение программы. Такой исход явно не является хорошим и с ним нужно что-то сделать.
Вот два способа, с помощью которых мы можем избежать такой ситуации:
books = ["Cracking the Coding Interview", "Clean Code", "The Pragmatic Programmer"] ind = books.index("The Pragmatic Programmer") if "The Pragmatic Programmer" in books else -1 print(ind) # Результат: # 2
Один из способов — проверить с помощью оператора in , есть ли элемент в списке. Оператор in имеет следующий синтаксис:
var in iterable
Итерируемый объект — iterable — может быть списком, кортежем, множеством, строкой или словарем. Если var существует как элемент в iterable , оператор in возвращает значение True . В противном случае он возвращает False .
Это идеально подходит для решения нашей проблемы. Мы просто проверим, есть ли элемент в списке, и вызовем метод index() только если элемент существует. Это гарантирует, что метод index() не вызовет нам ошибку ValueError .
Но если мы не хотим тратить время на проверку наличия элемента в списке (это особенно актуально для больших списков), мы можем обработать ValueError следующим образом:
books = ["Cracking the Coding Interview", "Clean Code", "The Pragmatic Programmer"] try: ind = books.index("Design Patterns") except ValueError: ind = -1 print(ind) # Результат: # -1
Здесь мы применили конструкцию try-except для обработки ошибок. Программа попытается выполнить блок, стоящий после слова try . Если это приведет к ошибке ValueError , то она выполнит блок после ключевого слова except . Подробнее про обработку исключений с помощью try-except можно почитать в статье «Обрабатываем исключения в Python: try и except».
Заключение
Итак, мы разобрали как определить индекс элемента списка в Python. Теперь вы знаете, как это сделать с помощью метода index() и генератора списков.
Мы также разобрали, как использовать метод index() для вложенных списков и как найти каждое вхождение элемента в списке. Кроме того, мы рассмотрели ситуацию, когда нужно найти индекс элемента, которого, возможно, нет в списке.
Мы надеемся, что данная статья была для вас полезной. Успехов в написании кода!
Больше 50 задач по Python c решением и дискуссией между подписчиками можно посмотреть тут
Как устроено индексирование баз данных

Индексирование баз данных — это техника, повышающая скорость и эффективность запросов к базе данных. Она создаёт отдельную структуру данных, сопоставляющую значения в одном или нескольких столбцах таблицы с соответствующими местоположениями на физическом накопителе, что позволяет базе данных быстро находить строки по конкретному запросу без необходимости сканирования всей таблицы. Применяются разные типы индексов, однако они занимают пространство и должны обновляться при изменении данных. Важно тщательно продумывать стратегию индексирования базы данных и регулярно её оптимизировать.
Как базы данных создают индексы

Неиндексированная и индексированная базы данных
Индексирование базы данных обычно выполняется при помощи алгоритма, определяющего, как должен создаваться и храниться индекс. Конкретный процесс создания индекса может варьироваться в зависимости от типа используемой системы базы данных, однако в целом общие этапы выглядят так:
- Определение столбца или столбцов в таблице базы данных, которые нужно индексировать. Обычно они определяются по тому, какие столбцы чаще всего используются в запросах или поисках.
- Выбор алгоритма индексирования, подходящего для типа индексируемых данных. Например, индексы в виде B-деревьев обычно используются для индексирования строковых или числовых данных, а полнотекстовые индексы — для индексирования текстовых данных.
- Применение алгоритма индексирования к выбранным столбцам, что создаёт структуру данных, сопоставляющую значения в столбцах с местоположениями соответствующих записей таблицы.
- Сохранение индекса в отдельной структуре данных, обычно в другой части диска или в памяти, чтобы доступ к ней был более эффективным, чем к соответствующим табличным данным.
- Обновление индекса в случае добавления новых записей, удаления или изменения записей в таблице.
Алгоритмы индексирования
Как говорилось выше, существует множество алгоритмов индексирования, используемых для оптимизации скорости операций получения данных при помощи создания индексов столбцов таблиц. Вот некоторые из самых популярных алгоритмов индексирования баз данных:
- B-дерево
- Bitmap-индекс
- Хэш-индекс
- GiST (Generalized Search Tree, обобщённое поисковое дерево)
- Полнотекстовый индекс
B-дерево

▍ Определение
B-дерево — это структура данных самобалансирующегося дерева, которая часто используется в качестве алгоритма индексирования в базах данных. Каждый узел дерева состоит из набора ключей и указателей на дочерние узлы; хранение данных осуществляется в иерархической структуре. Деревья B-узлов упорядочены таким образом, что позволяют быстро выполнять поиск, вставку и удаление данных.
Самое большое преимущество алгоритма B-дерева заключается в минимизации количества дисковых операций ввода-вывода, необходимых для доступа к данным, потому что в B-дереве все узлы-листья находятся на одном уровне, а каждый узел может хранить множество ключей и указателей. Количество ключей и указателей, которое может храниться в узле, определяется параметром, называемым «порядок» дерева.
▍ Как это работает
Алгоритм B-дерева работает следующим образом:
- Инициализация : при создании B-дерева создаётся пустой корневой узел. Параметр, задающий максимальное количество ключей («порядок»), которые могут храниться в каждом узле, управляет B-порядком дерева.
- Вставка : при добавлении нового узла в B-дерево алгоритм сначала подыскивает подходящий узел-лист, в который нужно вставить ключ. B-дерево разделяет заполненный узел-лист на два новых узла и перемещает медианный ключ в родительский узел. Пока не достигнут корневой узел, процесс разделения может распространяться по дереву. Благодаря этой процедуре дерево остаётся сбалансированным, а узлы-листья находятся на одинаковой высоте.
- Удаление : когда ключ удаляется из B-дерева, алгоритм ищет узел, который изначально хранил ключ. Если узел-лист хранил ключ, то ключ извлекается и узел может нуждаться в перебалансировке. Алгоритм удаляет предшествующий или последующий лист после листа-узла, удалив ключ с ним, если ключ обнаружен не в узле-листе.
- Поиск : в процессе поиска ключа в B-дереве алгоритм начинает с корневого узла и рекурсивно движется к веткам, пока не найдёт нужный узел-лист. Метод поиска сравнивает искомый ключ с ключами, содержащимися в каждом узле, а затем использует соответствующий указатель для перехода к дочернему узлу, в котором может находиться ключ. Этот процесс продолжается, пока не будет найден искомый ключ или пока не будет определено, что он отсутствует в дереве.
- Излишняя трата ресурсов : B-деревья задействуют большой объём излишнего пространства, поскольку каждый узел в B-дереве содержит указатель на родительский и дочерний узлы.
- Сложность : алгоритмы, используемые для вставки, удаления и поиска данных в B-дереве, сложнее по сравнению с другими структурами данных. Это усложняет реализацию и поддержку B-деревьев.
- Медленные обновления : обновление данных в B-дереве может быть относительно медленным по сравнению с другими структурами данных. Каждая операция обновления требует множества операций доступа к диску, и этот процесс может быть медленным для больших B-деревьев.
▍ Bitmap-индексирование

▍ Определение
Bitmap-индексирование — это методика индексирования данных, использующая битовые карты (bitmap) для обозначения наличия или отсутствия значения в таблице. Это успешная техника индексирования для таблиц с низкой кардинальностью, где количество уникальных значений в столбце довольно мало по сравнению с общим количеством строк.
Bitmap-индексирование может быть очень эффективным для столбцов с низкой кардинальностью, поскольку битовые карты крайне компактны и их можно быстро сканировать для извлечения данных. Bitmap-индексы очень удобны для применения в хранилищах данных, где необходимо быстро сканировать огромные объёмы данных. Кроме того, они полезны для баз данных, в которых много операций чтения, но мало обновлений или вставок.
▍ Как это работает
- Для создания bitmap-индекса столбца для каждого уникального значения столбца создаётся отдельный bitmap. Каждый bitmap имеет длину, равную количеству строк в таблице.
- Если значение присутствует в строке, соответствующему биту в bitmap присваивается значение 1, а если оно отсутствует, то присваивается значение 0. (Представьте таблицу, где столбец «Gender» имеет два уникальных значения, например, «Male» и «Female». Если этот столбец имеет bitmap-индекс, можно создать два bitmap, длина каждого из которых равна количеству строк в таблице. Когда в строке встречается «Male» или «Female», соответствующий бит в bitmap «Male» или «Female» получает значение 1, и наоборот. В случае отсутствия значения «Male» или «Female» соответствующему биту присваивается значение 0.)
- Чтобы выполнить запрос при помощи bitmap-индекса, соответствующие в запросе значения bitmap комбинируются при помощи побитовых операторов AND, OR и NOT. (например, если мы хотим найти все строки, где «Gender» равно «Male» И «Age» больше 30, нам сначала нужно получить bitmap «Male» и bitmap «Age > 30» из соответствующих индексов. Затем мы комбинируем эти два bitmap при помощи побитового оператора AND и получаем окончательный bitmap только с единицами в тех позициях, где оба условия истинны. Затем окончательный bitmap используется для получения из таблицы строк, удовлетворяющих запросу.)
- Большой размер : Bitmap-индексы могут быть большими, особенно при работе с крупными датасетами. Из-за этого они могут оказаться менее эффективными, чем другие методики индексирования.
- Столбцы с высокой кардинальностью : Bitmap-индексы неэффективны для столбцов с высокой кардинальностью, где количество уникальных значений очень высоко. В таких случаях bitmap-индексы могут становиться очень большими и не помещаться в памяти.
- Смещённое распределение данных : если данные смещены, у нескольких значений может быть гораздо более высокая частота, чем у других, и bitmap-индексы окажутся неэффективными. Это вызвано тем, что bitmap для наиболее частых значений становятся очень большими и могут доминировать в индексе.
Хэш-индекс

▍ Определение
Хэш-индекс — это разновидность методики индексирования баз данных, использующая хэш-функцию для сопоставления ключей индекса с местоположениями соответствующих записей данных. Это быстрый метод индексирования для запросов точного соответствия в одном столбце.
Сопоставление ключей индекса с местоположениями соответствующих записей данных позволяет выполнять быстрый поиск и вставки за постоянное время O(1). Однако этот метод плохо работает с запросами диапазонов или частичными совпадениями и может страдать от коллизий, с которыми можно справляться при помощи различных техник разрешения коллизий.
▍ Как это работает
Чтобы объяснить, как работает хэш-индекс, давайте рассмотрим пример. Допустим, у нас есть таблица базы данных, содержащая информацию о сотрудниках, в том числе, номера их пользовательских ID. Мы хотим создать хэш-индекс столбца пользовательских ID, чтобы получить возможность быстрого поиска данных пользователей на основании номера их ID.
- Мы создадим хэш-функцию, получающую на входе пользовательский ID и генерирующую на выходе уникальный хэш-код. Хэш-функция должна быть спроектирована таким образом, чтобы генерировать равномерно распределённое множество хэш-кодов для равномерного распределения записей по корзинам в файле индекса. На практике хэш-функция может использовать для генерации хэш-кода различные методики, например, модульную арифметику или побитовые операции.
- Мы создаём файл хэш-индекса, содержащий набор корзин (bucket), каждая из которых соответствует уникальному хэш-коду сгенерированному хэш-функцией. Каждая корзина содержит указатель на файл базы данных, содержащий записи для этого хэш-кода.
- При выполнении запроса к значению запроса применяется хэш-функция для генерации хэш-кода. Затем хэш-код используется для нахождения соответствующей корзины в файле хэш-индекса. Записи с одинаковым хэш-кодом хранятся в одной корзине, поэтому мы можем просто просканировать записи в этой корзине и найти совпадающую запись/записи. Если присутствуют коллизии (то есть несколько записей с одинаковым хэш-кодом), то для их разрешения можно использовать техники наподобие создания цепочек или открытой адресации.
- Чтобы вставить новую запись в хэш-индекс, мы применяем к значению ключа записи хэш-функцию, чтобы сгенерировать его хэш-код, а затем вставляем запись в соответствующую корзину в файле хэш-индекса. Если коллизии отсутствуют, вставку можно выполнить за постоянное время O(1), так как нам нужно всего лишь вычислить хэш-код и вставить запись в корзину. Если коллизии есть, нам может потребоваться проделать дополнительные операции, например, вставку записи в связанный список в корзине или проверку других корзин, пока не будет найден свободный слот.
- Ограниченные возможности поиска : хэш-индексы предназначены для обработки только поисков равенства (например, «найти все записи, где столбец A равен значению»). Они плохо подходят для запросов диапазонов или сортировки.
- Коллизии : хэш-индексы могут иметь коллизии, при которых несколько ключей соответствуют одному хэш-значению. Это может привести к снижению производительности, поскольку базе данных нужно будет выполнять дополнительные операции для разрешения коллизий.
- Непредсказуемые требования к размеру хранилища : размер хэш-индекса невозможно предугадать, так как он зависит от количества уникальных значений в индексируемом столбце. Это усложняет планирование требований к размеру хранилища.
▍ GiST

▍ Определение
GiST (Generalized Search Tree, обобщённое поисковое дерево) — это техника индексирования баз данных, которая может использоваться для индексирования сложных типов данных, например, геометрических объектов, текста или массивов. Это сбалансированная древовидная структура, состоящая из узлов с множественными дочерними узлами. Каждый узел описывает диапазон или множество значений и связан с предикативной функцией, проверяющей, принадлежит ли значение диапазону или множеству. Предикативная функция зависит от типа индексируемых данных и может быть подстроена под разные типы данных.
▍ Как это работает
Чтобы проиллюстрировать принцип работы индекса GiST, рассмотрим пример индексирования пространственных данных. Допустим, у нас есть таблица базы данных, содержащая информацию о городах, в том числе их названия и координаты в формате широты и долготы.
- Зададим множество предикатов и функций преобразования, специфичных для индексируемого типа пространственных данных. В данном случае мы должны задать предикат, проверяющий, находится ли заданная точка в ограничивающем прямоугольнике, описанном узлом в индексе, и функцию преобразования, преобразующую точку в набор ключей на основании её позиции в ограничивающем прямоугольнике.
- Создаём файл индекса GiST, состоящий из множества узлов, каждый из которых описывает ограничивающий прямоугольник, охватывающий диапазон координат.
Корневой узел описывает весь диапазон координат в таблице базы данных, а каждый дочерний узел описывает подмножество этого диапазона.
Затем ключи сравниваются с предикатами, связанными с каждым узлом индекса, начиная с корневого узла.
Поиск продолжается вниз по дереву и выбирает дочерний узел, содержащий значение из запроса.
Затем ключи вставляются в соответствующие узлы индекса, начиная с корневого узла.
- Сниженная скорость вставок и обновлений : структуры индексирования GiST могут быть сложнее, чем традиционные структуры индексирования, что может привести к снижению скорости операций вставки и обновления.
- Больше дискового пространства : структуры индексирования GiST могут требовать больше дискового пространства, чем другие методики индексирования, поскольку хранят дополнительную информацию для поддержки различных типов поиска.
- Подходит не для всех типов данных : GiST оптимизирован под индексирование сложных типов данных, например, пространственных данных, однако может быть не лучшим выбором для индексирования более простых типов данных, например, целочисленных значений или строк.
- Повышенные затраты на поддержку : из-за сложности реализации индексы GiST требуют больше обслуживания по сравнению с традиционными индексами.
▍ Полнотекстовый индекс

▍ Определение
Полнотекстовое индексирование — это методика индексирования баз данных, используемая для повышения эффективности поиска текстовых запросов. Это особый вид индекса, спроектированный для работы с текстовыми данными. В отличие от традиционных индексов, хранящих значения отдельных столбцов, полнотекстовый индекс хранит текстовое содержимое одного или нескольких столбцов как множества слов или токенов. Эти слова или токены используются при выполнении поискового запроса для быстрого нахождения релевантных строк.
Полнотекстовое индексирование способно существенно улучшить производительность текстовых поисковых запросов, особенно при работе с большими объёмами текстовых данных. Однако оно требует дополнительного дискового пространства и вычислительных ресурсов, а также тщательной настройки параметров индексирования для обеспечения оптимальной производительности.
▍ Как это работает
Процесс полнотекстового индексирования состоит из нескольких этапов:
- Токенизация : текстовое содержимое индексируемого столбца разбивается на отдельные слова или токены, которые затем сохраняются в индекс. При создании полнотекстового индекса система базы данных сначала анализирует текстовое содержимое индексируемых столбцов, а затем разбивает его на отдельные слова или токены. Этот процесс называется токенизацией, он может включать в себя фильтрацию игнорируемых слов (например, «the», «and», «or») и выделение корней (редуцирование слов до их базовой формы).
- Индексирование : затем токены индексируются при помощи специальной структуры данных, например, B-дерева или инвертированного индекса. Структура индекса обеспечивает возможность эффективного поиска и извлечения строк, содержащих указанные токены.
- Построение и выполнение запросов : система базы данных использует полнотекстовый индекс для поиска строк, содержащих релевантные токены. В процессе поиска токены запроса сопоставляются с индексированными токенами и извлекаются строки, соответствующие запросу. Результаты поиска можно ранжировать на основании их релевантности запросу, который вычисляется при помощи алгоритмов наподобие TF-IDF (term frequency-inverse document frequency).
- Сниженная скорость индексирования и поиска : полнотекстовое индексирование может быть более сложным, чем другие техники индексирования, что может приводить к снижению скорости индексирования и поиска, особенно в больших базах данных со множеством текстовых полей.
- Подходит не для всех типов данных : полнотекстовое индексирование лучше всего подходит для баз данных, содержащих большие объёмы текстовых данных. Оно может и не быть наиболее эффективной техникой для баз данных, по большей мере, для содержащих числовую или другую нетекстовую информацию.
- Зависимость от языка : полнотекстовое индексирование может быть не очень эффективно для многоязычных баз данных, поскольку требует отдельных индексов для каждого языка и может оказаться неспособным справиться с нюансами различных языков и систем письменности.
Заключение
Индексирование баз данных — критически важная технология, повышающая эффективность запросов к базам данных. Оно заключается в создании специальных структур данных, обеспечивающих эффективный поиск и извлечение данных на основании одного или нескольких столбцов таблицы. Для оптимизации запросов под различные типы данных и сценарии использования применяются разные типы алгоритмов индексирования, например, B-деревья, bitmap-индексы, хэш-индексы и GiST-индексы.
Подробнее об индексировании баз данных можно узнать из следующих ресурсов:
- “Use The Index, Luke!”, Markus Winand — это подробное руководство по индексированию баз данных SQL, в котором освещаются как основы, так и расширенные возможности.
- “Database Indexing Explained”, DigitalOcean — в этом туториале представлено понятное для новичков введение в концепции и методики индексирования с примерами на PostgreSQL.
- “Indexing Strategies for MySQL and MariaDB”, Severalnines — в этом посте представлены практические советы по проектированию и оптимизации индексов в MySQL и MariaDB.

- ruvds_перевод
- индексирование
- b-дерево
- bitmap-индексирование
- хэш-индекс
- gist
- полнотекстовый индекс
- базы данных
Как создавать и использовать индексы в БД Oracle
Индексы – это одни из самых мощных и непонятных аспектов производительности SQL. В этой статье мы рассмотрим назначение индекса, как правильно создать и выбрать нужный тип индекса. Затем мы обсудим как решить, что индексировать и полезно ли это.
Зачем индексы
Таблицы базы данных могут стать очень большими. Невероятно, колоссально большими. Например, Большой Адронный Колайдер в ЦЕРН генерирует суммарно 10 TB данных в день. А для поиска нескольких строк из миллионов, миллиардов, триллионов записей требуется большое количество времени. И индексы помогут вам это время сократить.
Индекс хранит значения в индексируемом столбце или столбцах. А для каждого значения — расположение строк, в которых есть это значение. Подобно указателю в конце книги. Это позволяет вам сосредоточиться только на тех данных, которые вас интересуют.
Индексы наиболее эффективны, когда позволяют вам найти несколько строк. Так что, если у вас есть запрос и большая таблица без индексов, то есть большая вероятность, что вы захотите их создать.
Как создать индекс
Создать индекс легко. Все что вам нужно сделать, это указать какие столбцы вы хотите индексировать, и дать имя индексу:
create index on ( , , … );Так, если вы хотите проиндексировать столбец Color таблицы Toys и назвать индекс toys_color_idx, то скрипт будет таким:
create index toys_color_i on toys ( color );Но как всегда, это еще не все. Вы можете помсетить много стобцов в один индекс. Например, вы можете включить в индекс тип игрушек, как показано ниже:
create index toys_color_type_i on toys ( color, type );Это завывается составным или комбинированным индексом. Порядок расположения столбцов в индексе оказывает большое влияние на то, будет ли оптимизатор использовать его. Мы обсудим это позже.
Как выбрать тип индекса
БД Oracle предлагает множество различных типов индексов для улучшения ваших SQL запросов. Одно из ключевых решений, которое вам необходимо принять, — это выбор Bitmap или B-tree индекса.
B-tree vs Bitmap
По умолчанию создаются B-tree индексы. Они являются сбалансированными деревьями. Это означает, что все листовые узлы находятся на одинаковой глубине в дереве. Поэтому для доступа к любому значению требуется одинаковое количество работы

Каждая запись листового индекса указывает ровно на одну строку.
Bitmap как и B-tree, хранят индексированные значения. Но вместо одной строки на запись, база данных связывает каждое значение с диапазоном строк. Затем имеется ряд единиц и нулей, чтобы показать, имеет ли каждая строка в диапазоне значение (1) или нет (0).
Value Start Rowid End Rowid Bitmap VAL1 AAAA ZZZZZ 001000000. VAL2 AAAA ZZZZZ 110000000. VAL3 AAAA ZZZZZ 000111100. . Обратите внимание, что начальный и конечный диапазоны строк охватывают все строки таблицы. Но в больших таблицах может потребоваться разделить строки на несколько диапазонов. Поэтому каждое индексированное значение имеет много записей.
Вот клчивые различия между B-tree и Bitmap.
Строки, в которых все индексированные значения равны null, НЕ включаются в B-tree. Но они включены в Bitmap! Поэтому оптимизатор может использовать Bitmap для ответов на такие запросы, как:
where indexed_column is null;Но обычно для B-tree это не так. Вы можете обойти это в B-tree, добавив константу в конец индекса. Таким образом, получается следующий составной индекс:
create index enable_for_is_null_i on tab ( indexed_column, 1 );Еще одним преимуществом Bitmap является то, что все эти единицы и нули легко сжимаются. Поэтому индекс Bitmap обычно меньше, чем тот же индекс B-tree. Но это преимущество уменьшается по мере увеличения количества различных значений в индексе.
Допустим у нас есть таблица победителей Олимпийских игр. Создание индексов на Edition, Sport, Medal, Event и Athleteдает следующие размеры (в блоках)
Если вы знакомы с таблицами истинности булевой логики, вы можете заметить одно большое преимущество Bitmap:
Для оптимизатора не составит труда объединить их.
Наложив диапазоны строк двух индексов, вы можете найти строки, соответствующие предложению where в обоих индексах. Затем перейти к таблице только для этих строк.
Это означает, что индексы, указывающие на большое количество строк, могут быть полезны. Допустим, вы хотите найти всех женщин, завоевавших золотые медали на Олимпийских играх в Афинах в 2000 году. Ваш запрос будет следующим:
select * from olym_medals where gender = 'Women' and medal = 'Gold' and edition = 2000;Каждая медаль составляет примерно одну треть строк. И можно подумать, что мужчины и женщины делятся примерно 50/50. К сожалению, это скорее 75/25 мужчин и женщин. Но в любом случае вряд ли будет полезен индекс только по gender или medal. Предположим, что в таблице 26 олимпийских игр. Что приближается к «малому количеству» строк. Но нет никакой гарантии, что оптимизатор выберет этот индекс.
Но в совокупности эти условия можно определить приблизительно:
(1/2) * (1/3) * (1/26) = 1/156 ~ 0.64% строкЭто определенно попадает в область «нескольких» строк. Поэтому, скорее всего, запрос выиграет от использования какого-то индекса.
Если вы создаете Bitmap с одним столбцом, база данных может объединить с помощью BITMAP AND следующим образом:
--------------------------------------------------------------- | Id | Operation | Name | --------------------------------------------------------------- | 0 | SELECT STATEMENT | | | 1 | TABLE ACCESS BY INDEX ROWID BATCHED| OLYM_MEDALS | | 2 | BITMAP CONVERSION TO ROWIDS | | | 3 | BITMAP AND | | |* 4 | BITMAP INDEX SINGLE VALUE | OLYM_EDITION_BI | |* 5 | BITMAP INDEX SINGLE VALUE | OLYM_MEDAL_BI | |* 6 | BITMAP INDEX SINGLE VALUE | OLYM_GENDER_BI | ---------------------------------------------------------------Это дает большую гибкость. Вам нужно создавать индексы только для одного столбца вашей таблицы. Если у вас есть условия для нескольких столбцов, база данных сшивает их вместе!
В-tree не имеют этой роскоши. Вы не можете просто наложить одно на другое, чтобы найти то, что вы ищете. Хотя Oracle может объединять B-tree (через «преобразование bitmap из rowids»), это относительно дорого. В целом, чтобы получить ту же производительность, что и при использовании трех bitmap, необходимо поместить все три столбца в один индекс. Это влияет на то, насколько многоразовым является индекс, о чем мы поговорим позже.
На данный момент это выглядит как безоговорочная победа bitmap над B-tree. Но теперь вы можете задасться вопросом:
Почему по умолчанию используются B-tree, а не Bitmap?
Индексы Bitmap имеют существенный недостаток: Убивают параллелизм записи.
Это одна из немногих ситуаций в Oracle, когда вставка в одном сеансе может блокировать вставку в другом. Это делает их сомнительными для большинства OLTP-приложений.
Каждый раз, когда вы вставляете, обновляете или удаляете строки таблицы, база данных должна синхронизировать индекс. Это происходит в B-tree путем прохождения по дереву, изменяя по мере необходимости записи в листьях.
Но Bitmap блокирует весь диапазон строк начала/конца! Допустим, вы добавляете строку со значением RED. Любые другие вставки, которые попытаются добавить еще одну строку со значением RED в тот же диапазон, будут заблокированы до тех пор, пока первая не будет зафиксирована!
Это еще большая проблема с обновлениями. Обновление в B-tree — это удаление старого значения и вставка нового. Но при использовании Bitmap Oracle должна заблокировать затронутые диапазоны для старого и нового значений!
В результате Bitmap лучше всего подходят для таблиц, в которые одновременно будет записываться только один процесс. Это часто бывает в таблицах отчетов или хранилищах данных. Но это не ваше типичное приложение.
Поэтому, если несколько сеансов будут одновременно изменять данные в таблице, хорошо подумайте, прежде чем использовать Bitmap.
Поэтому, как бы ни были хороши Bitmap, для большинства приложений лучше использовать B-tree!
Индексы на основе функций
Это просто индексы, в которых к одному или нескольким столбцам применяется функция. Индекс хранит результат этого вычисления. Например:
create index date_at_midnight_i on table ( trunc ( datetime ) );create index upper_names_i on table ( upper ( name ) );Вы можете использовать функции в индексах Bitmap или B-tree.
Имейте в виду, что если у вас есть индекс на основе функции, то для его использования функция в предложении where должна точно соответствовать определению в индексе. Поэтому если ваш индекс имеет вид:
create index dates_i on dates ( trunc (datetime) );Ваше условие where должно быть таким:
where trunc (datetime) = :some_dateЛучше избегать индексов на основе функций, если это возможно. Вместо этого перенесите вычисления из столбца в переменную.
Например, используя стандартную математику, перестройте формулу так, чтобы в столбце не было функций:
column + 10 = val -> column = val – 10
column * 100 = val -> column = val / 100
Или так. Тип данных даты в Oracle всегда включает время суток. Поэтому, чтобы гарантированно получить все строки, приходящиеся на определенный день, вы можете нормализовать дату до полуночи. Затем сравните результат с датой, например, так:
trunc( datetime_col ) = :dtНо есть и другой способ сделать это. Проверьте, что столбец больше или равен переменной и строго меньше переменной плюс один день:
datetime_col >= :dt and datetime_col < :dt + 1Уникальный индекс - это форма ограничения. Он утверждает, что вы можете хранить заданное значение в таблице только один раз. Когда вы создаете первичный ключ или уникальное ограничение, Oracle автоматически создаст для вас уникальный индекс (при условии, что индекс еще не существует). В большинстве случаев вы добавляете ограничение в таблицу и позволяете базе данных создать индекс за вас.
Но есть один случай, когда необходимо вручную создать индекс: Уникальные ограничения на основе функций.
Вы не можете использовать функции в уникальных ограничениях. Например, вы можете захотеть создать таблицу "dates", которая хранит одну строку для каждого календарного дня. К сожалению, в Oracle нет типа данных "день". Даты всегда содержат компонент времени. Чтобы обеспечить одну строку в день, необходимо зафиксировать время до полуночи. Для этого применяется функция trunc(). Но ограничение не сработает:
alter table dates add constraint date_u unique ( trunc ( calendar_date ) );Поэтому необходимо прибегнуть к уникальному индексу на основе функции:
create unique index date_ui on dates ( trunc ( calendar_date ) );Или вы можете скрыть функцию в виртуальном столбце. Затем проиндексировать ее. Например:
alter table dates add cal_date_no_time as ( trunc(calendar_date) ); alter table dates add constraint date_u unique ( cal_date_no_time );Индексы B-tree - это упорядоченные структуры данных. Новые записи должны попадать в нужное место в соответствии с логическим порядком, навязанным столбцами. По умолчанию они сортируются от малого к большому.
Но вы можете изменить это. Указав desc после столбца, Oracle сортирует значения от больших к маленьким.
Обычно это не имеет большого значения. База данных может подниматься или опускаться по индексу по мере необходимости. Поэтому редко кто захочет их использовать.
Но есть случай, когда они могут помочь. Если ваш запрос содержит "order by desc", то нисходящий индекс может избежать операции сортировки. Простейший случай - это когда вы ищете диапазон значений, сортируете их по убыванию и по другому столбцу.
Например, поиск заказов по идентификаторам customer_ids в заданном диапазоне. Верните эти идентификаторы в обратном порядке. Затем отсортируйте по дате продажи:
select * from orders where customer_id between :min_cust_id and :max_cust_id order by customer_id desc, order_datetime;Если использовать обычный составной индекс на ( customer_id, order_datetime ), план будет выглядеть следующим образом:
------------------------------------------------- | Id | Operation | Name | ------------------------------------------------- | 0 | SELECT STATEMENT | | | 1 | SORT ORDER BY | | | 2 | TABLE ACCESS BY INDEX ROWID| ORDERS | | 3 | INDEX RANGE SCAN | ORDERS_I | -------------------------------------------------Но создайте его с ( customer_id desc, order_datetime ) и шаг сортировки исчезает!
------------------------------------------------ | Id | Operation | Name | ------------------------------------------------ | 0 | SELECT STATEMENT | | | 1 | TABLE ACCESS BY INDEX ROWID| ORDERS | | 2 | INDEX RANGE SCAN | ORDERS_I | ------------------------------------------------Это может существенно сэкономить время, если сортировка "дорогая".
JSON Search Indexes
Хранение данных в виде документов JSON (к сожалению) становится все более распространенным. Все атрибуты являются частью документа, а не отдельным столбцом. Это затрудняет индексирование значений. Поэтому поиск документов, содержащих определенные значения, может быть мучительно медленным. Эту проблему можно решить, создав индексы на основе функций для искомых атрибутов.
Например, допустим, вы храните данные об Олимпийских играх в формате JSON. Вы регулярно ищете, какие медали завоевал тот или иной спортсмен. Вы можете проиндексировать это следующим образом:
create index olym_athlete_json_i on olym_medals_json ( json_value ( jdoc, '$.athlete' ) );И ваши запросы с этим выражением json_value должны получить хороший прирост.
Но вы можете захотеть выполнить специальный поиск в JSON, ища любые значения в документах. Чтобы помочь в этом, вы можете создать индекс специально для данных JSON начиная с Oracle 12.2. Это легко сделать:
create search index olym_medals_json_i on olym_medals_json ( jdoc ) for json;Затем база данных может использовать его для любого SQL запроса с помощью различных функций JSON.
Если вам интересно, как работает поисковый индекс JSON, то под обложкой он использует Oracle Text. Это подводит нас к следующему:
Oracle Text Indexes
Возможно, в вашей базе данных есть большие объемы свободного текста. Такие, по которым вы хотите проводить нечеткий поиск, семантический анализ и так далее. Для них вы можете создать текстовый индекс. Они бывают трех видов:
Использование этих индексов само по себе является огромной темой. Поэтому, если вы хотите выполнить такой поиск, я рекомендую начать с Руководства разработчика.
Существует несколько других типов индексов. Скорее всего, вам никогда не понадобится их создавать, но я включил их на всякий случай 😉
Application Domain Indexes
Время от времени вы хотите создать специализированный индекс, адаптированный к вашим данным. Здесь вы указываете, как база данных индексирует и хранит ваши данные.
Если вы хотите сделать это, ознакомьтесь с Руководством разработчика.
Reverse Key Indexes
Если у вас есть индекс на столбце, который хранит постоянно увеличивающиеся значения, все новые записи должны располагаться на правом краю индекса. Первичные ключи на основе последовательностей и временные метки вставки являются распространенными примерами.
Если у вас есть большое количество сессий, делающих это одновременно, это может привести к проблемам. Все они должны получить доступ к одному и тому же индексному блоку, чтобы добавить свои данные. Поскольку только один может изменить его за один раз, это может привести к конфликту. Этот термин называется "hot blocks".
Индексы с обратным ключом позволяют избежать этой проблемы, меняя порядок байтов индексируемых значений. Таким образом, вместо того чтобы хранить 12345, вы храните 54321. Чистым эффектом этого является распространение новых строк по всему индексу.
В редких случаях вам понадобится это сделать. А поскольку записи хранятся не в естественном порядке сортировки, вы можете использовать эти индексы только для запросов на равенство. Поэтому часто лучше решить эту проблему другим способом, например, с помощью хэш-разбиения индекса.
Итак, мы рассмотрели различные типы доступных индексов. Но мы все еще не разобрались с тем, какие индексы следует создавать для вашего приложения. Пришло время разобраться.
Как решить, что индексировать
Прежде всего, важно знать, что здесь нет "правильного" ответа (хотя есть несколько неправильных ;)). Вполне вероятно, что у вас будет много различных запросов к таблице. Если вы создадите индекс для каждого из них, то в итоге у вас будет масса индексов. Это проблема, поскольку каждый дополнительный индекс увеличивает накладные расходы на хранение и обслуживание данных.
Поэтому для каждого запроса необходимо найти компромисс между максимально возможной скоростью выполнения и общим воздействием на систему. Все - это компромисс!
Самое главное - помнить, что для того, чтобы база данных использовала индекс, столбец(и) должен быть в вашем запросе! Поэтому если столбец никогда не появляется в ваших запросах, его не стоит индексировать. С некоторыми оговорками:
- Уникальные индексы - это действительно ограничения. Поэтому они могут понадобиться вам для обеспечения качества данных. Даже если вы не запрашиваете сами столбцы.
- Вы должны индексировать все столбцы внешнего ключа, которые вы удаляете из родительской таблицы или обновляете ее первичный ключ.
Кроме того, индекс наиболее эффективен, когда его столбцы появляются в предложении where для поиска "немногих" строк в таблице.
Ключевой момент заключается в том, что важно не столько количество строк, сколько количество блоков базы данных, к которым вы обращаетесь. Как правило, индекс полезен, если он позволяет базе данных обращаться к меньшему количеству блоков, чем при полном сканировании таблицы. Запрос может вернуть "много" строк, но получить доступ к "малому количеству" блоков базы данных.
Обычно это происходит, когда логическая сортировка строк по столбцу (столбцам) запроса близко соответствует физическому порядку, в котором они хранятся в базе данных. Индексы хранят значения в этом логическом порядке. Поэтому вы обычно хотите использовать индексы там, где это происходит. Фактор кластеризации - это мера того, насколько тесно совпадают эти логический и физический порядки. Чем меньше это значение, тем более эффективным будет индекс. И, следовательно, оптимизатор будет его использовать.
Но, вопреки распространенному мнению, вам не обязательно указывать индексированный столбец (столбцы) в предложении where. Например, если у вас такой запрос:
select indexed_col from table;Oracle может выполнять полное сканирование индекса вместо таблицы. Это хорошо, потому что индексы обычно меньше, чем таблица, на которой они находятся. Но помните: null исключены из B-tree. Поэтому их можно использовать, только если у вас есть ограничение not null на столбец!
Если ваш SQL запрос использует только один столбец таблицы в предложениях join и where, то вы можете иметь одностолбцовые индексы и все.
Но реальный мир сложнее. Скорее всего, у вас относительно немного базовых запросов, таких как:
select * from tab where col = 'value';select * from tab1 join tab2 on t1.col = t2.col join tab3 on t2.col2 = t3.col1 where t1.other_col = 3 and t3.yet_another_col order by t1.something_else;Как обсуждалось ранее, если вы используете Bitmap, вы можете создать индексы для одного столбца. И предоставить оптимизатору объединять их по мере необходимости. Но с B-tree этого может не произойти. А когда это происходит, работы становится больше.
Поэтому, скорее всего, вам понадобятся составные индексы. Это означает, что вам нужно подумать о том, в каком порядке расположить столбцы в индексе.
Потому что Oracle читает индекс, начиная с самого левого ("первого") столбца. Затем он переходит ко второму, третьему и т.д. Поэтому если у вас есть индекс на:
create index i on tab ( col1, col2, col3 );where col3 = 'value'Чтобы использовать индекс, база данных должна либо просмотреть все значения в col1 и col2. Или, что более вероятно, прочитать все значения, чтобы найти те, которые соответствуют вашим условиям.
Принимая это во внимание, вот несколько рекомендаций для составных индексов:
- Колонки с условиями равенства (=) должны идти первыми в индексе
- Те, которые имеют условия диапазона (=, между и т.д.), должны идти ближе к концу
- Столбцы только в пунктах select или order by должны идти последними
Приведенные здесь выводы для порядка колонок НЕ являются чугунными правилами. Специфика ваших данных и требований может привести вас к другим выводам и, соответственно, индексам. Важно понять процесс анализа компромиссов, чтобы найти "лучшие" индексы для вашего приложения.
Чтобы представить это в контексте, давайте вернемся к таблице олимпийских медалей и исследуем некоторые запросы.
Допустим, у вас есть три обычных запроса к этим данным:
select listagg(athlete,',') within group (order by athlete) from olym_medals where medal = 'Gold'; select listagg(athlete,',') within group (order by athlete) from olym_medals where event = '100m'; select listagg(athlete,',') within group (order by athlete) from olym_medals where medal = 'Gold' and event = '100m';Что вы индексируете?
При наличии всего трех значений для medal и равномерном разбросе между ними индекс по этому показателю вряд ли поможет. Запросы по событию возвращают мало строк. Так что это определенно стоит индексировать.
Но как насчет запросов к обоим столбцам?
Нужно ли индексировать:
( event, medal )( medal, event )Для запроса с поиском по обоим столбцам это мало что изменит. Оба варианта попадут в таблицу только для строк, соответствующих условию where.
Но порядок влияет на то, какие из других запросов будут его использовать.
Помните, что Oracle читает индексные столбцы слева направо. Поэтому если вы индексируете (medal, event), ваш запрос, ищущий всех победителей в беге на 100 метров, должен сначала считать значения medal.
Обычно оптимизатор не делает этого. Но в случаях, когда в первом столбце мало значений, он может обойти его при так называемом сканировании с пропуском индекса.
Использование ( event, medal ) имеет преимущество более целенаправленного индекса по сравнению с просто ( event ). И это дает небольшое сокращение работы запроса по обоим столбцам по сравнению с индексом только по event.
Так что у вас есть выбор. Вы индексируете только event, или event и medal?
Индекс на обоих столбцах немного сокращает объем работы при запросах на event и medal.
Но стоит ли иметь два индекса для такой экономии?
Помимо того, что составной индекс занимает больше дискового пространства, увеличивает накладные расходы на DML и т.д., есть еще одна проблема. Коэффициент кластеризации для event_medal почти в 3 раза выше, чем для medal!
Так что же в этом плохого?
Фактор кластеризации является одним из ключевых факторов, определяющих, насколько "привлекательным" является индекс. Чем он выше, тем меньше вероятность того, что оптимизатор выберет именно его. Если вам не повезет, этого может быть достаточно, чтобы оптимизатор решил, что полное сканирование таблицы дешевле.
Конечно, если вам действительно нужно, чтобы SQL запрос, ищущий золотых призеров в определенных соревнованиях, был сверхскоростным, используйте композитный индекс. Но в данном случае, возможно, лучше пойти на шаг дальше. Добавьте к индексу еще и спортсмена. Таким образом, Oracle сможет ответить на запрос, обратившись только к индексу. Избежав обращения к таблице, вы сэкономите немного работы. В большинстве других случаев я бы придерживался одноколоночного индекса событий.
Рассмотрим другой пример. Допустим, ваш доминирующий запрос заключается в поиске победителей для заданных событий в определенном году:
select listagg(athlete,',') within group (order by athlete) from olym_medals where edition = 2000 and event = '100m';В большинстве случаев это дает три или шесть строк. Даже если речь идет о досадных командных соревнованиях с большим количеством спортсменов, получающих медали, вы получите не более 100 строк. Поэтому составной индекс - хорошая идея.
Но в каком порядке вы должны расположить колонки?!
Если у вас нет других запросов к этим столбцам, это не имеет значения. Но есть и другой аспект, который необходимо учитывать:
Вы можете сжать индекс. Это эффективно удаляет дубликаты в его ведущем столбце (столбцах). При условии, что для каждого значения имеется "много" строк, это может значительно уменьшить размер индекса. Это экономит дисковое пространство. А это значит, что при запросе нужно сканировать меньше данных. Это может уменьшить объем работы, выполняемой вашим SQL запросом.
Итак, какую колонку следует поставить на первое место и сжать? Edition или event?
Для edition существует гораздо больше строк, чем для event. Так что это должно быть первым, верно?
Давайте посмотрим. Восстановление индекса с помощью "compress N" сжимает первые N столбцов. Поэтому, чтобы сжать ведущий столбец, нужно выполнить:
alter index olym_event_year_i rebuild compress 1; alter index olym_year_event_i rebuild compress 1;Что приводит к уменьшению размеров индекса.
Размещение события на первом месте почти вдвое сокращает размер индекса по сравнению с edition. Несмотря на то, что в среднем на edition приходится в три раза больше строк, чем на event.
Так почему же? Все дело в длине значений.
Некоторые evnt имеют длинные описания, например, тяжелая атлетика "75 - 82,5 кг, один-два рывка руками 3 э. (полутяжелый-тяжелый вес)". Это приводит к тому, что средняя длина event составляет 15 байт. Почти в четыре раза больше, чем 4 байта, необходимые для хранения лет.
Поэтому нужно смотреть на то, насколько сжимаемы значения, а не только на то, сколько их у вас.
Конечно, в этом случае можно пойти дальше и сжать оба столбца обоих индексов с помощью функции:
alter index olym_event_year_i rebuild compress 2; alter index olym_year_event_i rebuild compress 2;Поэтому вопрос о том, какой столбец разместить первым, остается открытым. Проверьте свой другой SQL и посмотрите, не подталкивает ли это вас к тому, чтобы поместить один или другой столбец первым.
До сих пор мы говорили только о проверке равенства. Часто в SQL запросах вы ищете диапазон значений в одном из столбцов. Например, поиск всех победителей в беге на 100 м после 2000 года:
select * from olym_medals where event = '100m' and edition > 2000;В этом случае лучше создать индекс по (event, edition), а не наоборот. Это связано с тем, что база данных может сначала определить только записи о беге на 100 метров. Затем отфильтровать те, которые относятся к Олимпийским играм этого века. В отличие от поиска всех записей после 2000 года. Затем отфильтровать их, чтобы найти победителей в беге на 100 м.
Помните: приведенные здесь рекомендации по порядку колонок относятся только к данному набору данных. Важнее понять сам процесс и вопросы, которые необходимо задать. Например:
- Какой столбец (столбцы) фигурирует в предложении where большинства запросов?
- Возвращают ли условия по этим столбцам достаточно маленький набор строк и доступ к достаточно малому количеству блоков, чтобы индекс был полезен?
- Какие столбцы в индексе наиболее сжимаемы?
- Какие операторы SQL вы хотите сделать приоритетными для производительности?
Итак, вы создали индексы. И вы хотите оценить, помогают они или нет. Таким образом, остается важный вопрос:
Как узнать, какие индексы использовались в запросе?
Чтобы выяснить это, необходимо просмотреть план выполнения запроса. Он показывает все шаги, которые предприняла база данных для обработки запроса. Если оптимизатор выбрал индекс, он будет отображаться в плане как шаг.
Например, этот план показывает запрос, использующий индекс orders_i для доступа к таблице orders:
------------------------------------------------ | Id | Operation | Name | ------------------------------------------------ | 0 | SELECT STATEMENT | | | 1 | TABLE ACCESS BY INDEX ROWID| ORDERS | | 2 | INDEX RANGE SCAN | ORDERS_I | ------------------------------------------------На этом этапе вы можете обнаружить, что оптимизатор не выбрал ваш индекс. Вы уверены, что это "правильный" индекс и SQL должен его использовать. Поэтому вы можете задаться вопросом:
Как заставить SQL-запрос использовать индекс?
Я уверен, что некоторые из вас сейчас испытывают искушение потянуться к подсказке индекса. Это дает указание базе данных использовать индекс. Это может быть полезно для того, чтобы проверить, действительно ли этот план более эффективен, чем тот, который выбрал оптимизатор.
Но я настоятельно не рекомендую использовать их в продакшене. Хотя они называются подсказками, на самом деле это директивы. База данных должна использовать индекс с подсказкой, если она в состоянии это сделать. Ваши данные могут измениться, в результате чего индекс будет работать медленнее, чем полное сканирование таблицы. Но запрос все равно вынужден его использовать. Это может создать для вас проблемы с обслуживанием в будущем.
Но что если ваш индекс действительно обеспечивает более быстрый план? Вы хотите каким-то образом заставить базу данных пойти по правильному пути, верно?
В этом случае я бы направил вас в сторону SQL Plan Management. Использование SQL Baselines гарантирует, что запросы используют нужный вам план, со встроенным процессом перехода на более быстрый план, если он доступен.
Заключительные слова
Сведите количество создаваемых индексов к минимуму.
Трудно доказать, что ваше приложение не нуждается в существующем индексе. Причины создания редко используемых индексов со временем забываются. Люди будут приходить и уходить из вашей команды. И никто не будет знать, почему кто-то создал это чудовище из пяти столбцов на основе функций. Вы не знаете, не используется ли он никогда, или он критически важен для отчетности на конец года и ни для чего другого.
Поэтому, как только вы создадите индекс в продакшене, отбрасывать его рискованно. Это может привести к странному случаю, когда в таблице больше индексов, чем столбцов!
Такие достижения, как невидимые индексы в 11.1 (версия Oracle) и улучшенный мониторинг индексов в 12.2, помогают снизить этот риск. Но он никогда не исчезает полностью. Если разрываться между созданием двух "идеальных" индексов и одного "достаточно хорошего", я обычно выбираю тот, который достаточно хорош.
В конце концов, если окажется, что вам действительно нужен более целевой индекс, я уверен, что ваши клиенты быстро расскажут вам, насколько медленно работает ваше приложение!
Но прежде всего, тестируйте!
Python: коллекции, часть 2/4: индексирование, срезы, сортировка
Данная статья является продолжением моей статьи "Python: коллекции, часть 1: классификация, общие подходы и методы, конвертация".
В данной статье мы продолжим изучать общие принципы работы со стандартными коллекциями (модуль collections в ней не рассматривается) Python.
Для кого: для изучающих Python и уже имеющих начальное представление о коллекциях и работе с ними, желающих систематизировать и углубить свои знания, сложить их в целостную картину.
ОГЛАВЛЕНИЕ:
1. Индексирование
1.1 Индексированные коллекции
Рассмотрим индексированные коллекции (их еще называют последовательности — sequences) — список (list), кортеж (tuple), строку (string).
Под индексированностью имеется ввиду, что элементы коллекции располагаются в определённом порядке, каждый элемент имеет свой индекс от 0 (то есть первый по счёту элемент имеет индекс не 1, а 0) до индекса на единицу меньшего длины коллекции (т.е. len(mycollection)-1).
1.2 Получение значения по индексу
Для всех индексированных коллекций можно получить значение элемента по его индексу в квадратных скобках. Причем, можно задавать отрицательный индекс, это значит, что будем находить элемент с конца считая обратном порядке.
При задании отрицательного индекса, последний элемент имеет индекс -1, предпоследний -2 и так далее до первого элемента индекс которого равен значению длины коллекции с отрицательным знаком, то есть (-len(mycollection).
| элементы | a | b | c | d | e |
|---|---|---|---|---|---|
| индексы | 0 (-5) | 1 (-4) | 2 (-3) | 3 (-2) | 4 (-1) |
my_str = "abcde" print(my_str[0]) # a - первый элемент print(my_str[-1]) # e - последний элемент print(my_str[len(my_str)-1]) # e - так тоже можно взять последний элемент print(my_str[-2]) # d - предпоследний элемент
Наши коллекции могут иметь несколько уровней вложенности, как список списков в примере ниже. Для перехода на уровень глубже ставится вторая пара квадратных скобок и так далее.
my_2lvl_list = [[1, 2, 3], ['a', 'b', 'c']] print(my_2lvl_list[0]) # [1, 2, 3] - первый элемент — первый вложенный список print(my_2lvl_list[0][0]) # 1 — первый элемент первого вложенного списка print(my_2lvl_list[1][-1]) # с — последний элемент второго вложенного списка 1.3 Изменение элемента списка по индексу
Поскольку кортежи и строки у нас неизменяемые коллекции, то по индексу мы можем только брать элементы, но не менять их:
my_tuple = (1, 2, 3, 4, 5) print(my_tuple[0]) # 1 my_tuple[0] = 100 # TypeError: 'tuple' object does not support item assignment А вот для списка, если взятие элемента по индексу располагается в левой части выражения, а далее идёт оператор присваивания =, то мы задаём новое значение элементу с этим индексом.
my_list = [1, 2, 3, [4, 5]] my_list[0] = 10 my_list[-1][0] = 40 print(my_list) # [10, 2, 3, [40, 5]] UPD: Примечание: Для такого присвоения, элемент уже должен существовать в списке, нельзя таким образом добавить элемент на несуществующий индекс.
my_list = [1, 2, 3, 4, 5] my_list[5] = 6 # IndexError: list assignment index out of range 2 Срезы
2.1 Синтаксис среза
Очень часто, надо получить не один какой-то элемент, а некоторый их набор ограниченный определенными простыми правилами — например первые 5 или последние три, или каждый второй элемент — в таких задачах, вместо перебора в цикле намного удобнее использовать так называемый срез (slice, slicing).
Следует помнить, что взяв элемент по индексу или срезом (slice) мы не как не меняем исходную коллекцию, мы просто скопировали ее часть для дальнейшего использования (например добавления в другую коллекцию, вывода на печать, каких-то вычислений). Поскольку сама коллекция не меняется — это применимо как к изменяемым (список) так и к неизменяемым (строка, кортеж) последовательностям.
Синтаксис среза похож на таковой для индексации, но в квадратных скобках вместо одного значения указывается 2-3 через двоеточие:
my_collection[start:stop:step] # старт, стоп и шагОсобенности среза:
- Отрицательные значения старта и стопа означают, что считать надо не с начала, а с конца коллекции.
- Отрицательное значение шага — перебор ведём в обратном порядке справа налево.
- Если не указан старт [:stop:step]— начинаем с самого края коллекции, то есть с первого элемента (включая его), если шаг положительный или с последнего (включая его), если шаг отрицательный (и соответственно перебор идет от конца к началу).
- Если не указан стоп [start:: step] — идем до самого края коллекции, то есть до последнего элемента (включая его), если шаг положительный или до первого элемента (включая его), если шаг отрицательный (и соответственно перебор идет от конца к началу).
- step = 1, то есть последовательный перебор слева направо указывать не обязательно — это значение шага по умолчанию. В таком случае достаточно указать [start:stop]
- Можно сделать даже так [:] — это значит взять коллекцию целиком
- ВАЖНО: При срезе, первый индекс входит в выборку, а второй нет!
То есть от старта включительно, до стопа, где стоп не включается в результат. Математически это можно было бы записать как [start, stop) или пояснить вот таким правилом:
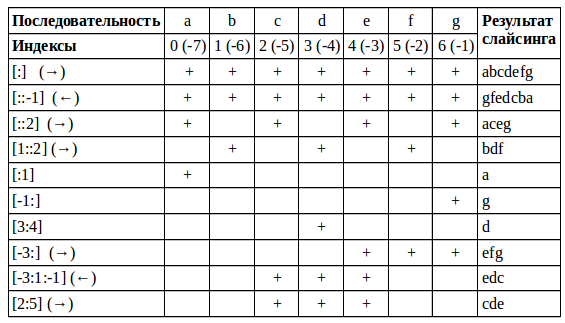
Примеры срезов в виде таблицы:
Код примеров из таблицы
col = 'abcdefg' print(col[:]) # abcdefg print(col[::-1]) # gfedcba print(col[::2]) # aceg print(col[1::2]) # bdf print(col[:1]) # a print(col[-1:]) # g print(col[3:4]) # d print(col[-3:]) # efg print(col[-3:1:-1]) # edc print(col[2:5]) # cde2.2. Именованные срезы
Чтобы избавится от «магических констант», особенно в случае, когда один и тот же срез надо применять многократно, можно задать константы с именованными срезами с пользованием специальной функции slice()()
Примечание: Nonе соответствует опущенному значению по-умолчанию. То есть [:2] становится slice(None, 2), а [1::2] становится slice(1, None, 2).
person = ('Alex', 'Smith', "May", 10, 1980) NAME, BIRTHDAY = slice(None, 2), slice(2, None) # задаем константам именованные срезы # данные константы в квадратных скобках заменятся соответствующими срезами print(person[NAME]) # ('Alex', 'Smith') print(person[BIRTHDAY]) # ('May', 10, 1980) my_list = [1, 2, 3, 4, 5, 6, 7] EVEN = slice(1, None, 2) print(my_list[EVEN]) # [2, 4, 6] 2.3 Изменение списка срезом
Важный момент, на котором не всегда заостряется внимание — с помощью среза можно не только получать копию коллекции, но в случае списка можно также менять значения элементов, удалять и добавлять новые.
Проиллюстрируем это на примерах ниже:
-
Даже если хотим добавить один элемент, необходимо передавать итерируемый объект, иначе будет ошибка TypeError: can only assign an iterable
my_list = [1, 2, 3, 4, 5] # my_list[1:2] = 20 # TypeError: can only assign an iterable my_list[1:2] = [20] # Вот теперь все работает print(my_list) # [1, 20, 3, 4, 5] Срез аналоги .append() и insert()
my_list = [1, 2, 3, 4, 5] my_list[5:] = [6] # вставляем в конец — лучше использовать .append(6) print(my_list) # [1, 2, 3, 4, 5, 6] my_list[0:0] = [0] # вставляем в начало — лучше использовать .insert(0, 0) print(my_list) # [0, 1, 2, 3, 4, 5, 6] my_list[3:3] = [25] # вставляем между элементами — лучше использовать .insert(3, 25) print(my_list) # [0, 1, 2, 25, 3, 4, 5, 6] my_list = [1, 2, 3, 4, 5] my_list[1:3] = [20, 30] print(my_list) # [1, 20, 30, 4, 5] my_list[1:3] = [0] # нет проблем заменить два элемента на один print(my_list) # [1, 0, 4, 5] my_list[2:] = [40, 50, 60] # или два элемента на три print(my_list) # [1, 0, 40, 50, 60] my_list = [1, 2, 3, 4, 5] my_list[:2] = [] # или del my_list[:2] print(my_list) # [3, 4, 5] 2.4 Выход за границы индекса
Обращение по индексу по сути является частным случаем среза, когда мы обращаемся только к одному элементу, а не диапазону. Но есть очень важное отличие в обработке ситуации с отсутствующим элементом с искомым индексом.
Обращение к несуществующему индексу коллекции вызывает ошибку:
my_list = [1, 2, 3, 4, 5] print(my_list[-10]) # IndexError: list index out of range print(my_list[10]) # IndexError: list index out of range А в случае выхода границ среза за границы коллекции никакой ошибки не происходит:
my_list = [1, 2, 3, 4, 5] print(my_list[0:10]) # [1, 2, 3, 4, 5] — отработали в пределах коллекции print(my_list[10:100]) # [] - таких элементов нет — вернули пустую коллекцию print(my_list[10:11]) # [] - проверяем 1 отсутствующий элемент - пустая коллекция, без ошибки Примечание: Для тех случаев, когда функционала срезов недостаточно и требуются более сложные выборки, можно воспользоваться синтаксисом выражений-генераторов, рассмотрению которых посвещена 4 статья цикла.
3 Сортировка элементов коллекции
Сортировка элементов коллекции важная и востребованная функция, постоянно встречающаяся в обычных задачах. Тут есть несколько особенностей, на которых не всегда заостряется внимание, но которые очень важны.
3.1 Функция sorted()
Мы может использовать функцию sorted() для вывода списка сортированных элементов любой коллекции для последующее обработки или вывода.
- функция не меняет исходную коллекцию, а возвращает новый список из ее элементов;
- не зависимо от типа исходной коллекции, вернётся список (list) ее элементов;
- поскольку она не меняет исходную коллекцию, ее можно применять к неизменяемым коллекциям;
- Поскольку при сортировке возвращаемых элементов нам не важно, был ли у элемента некий индекс в исходной коллекции, можно применять к неиндексированным коллекциям;
- Имеет дополнительные не обязательные аргументы:
reverse=True — сортировка в обратном порядке
key=funcname (начиная с Python 2.4) — сортировка с помощью специальной функции funcname, она может быть как стандартной функцией Python, так и специально написанной вами для данной задачи функцией и лямбдой.
my_list = [2, 5, 1, 7, 3] my_list_sorted = sorted(my_list) print(my_list_sorted) # [1, 2, 3, 5, 7] my_set = my_set_sorted = sorted(my_set, reverse=True) print(my_set_sorted) # [7, 5, 3, 2, 1] Пример сортировки списка строк по длине len() каждого элемента:
my_files = ['somecat.jpg', 'pc.png', 'apple.bmp', 'mydog.gif'] my_files_sorted = sorted(my_files, key=len) print(my_files_sorted) # ['pc.png', 'apple.bmp', 'mydog.gif', 'somecat.jpg'] 3.2 Функция reversed()
Функция reversed() применяется для последовательностей и работает по другому:
- возвращает генератор списка, а не сам список;
- если нужно получить не генератор, а готовый список, результат можно обернуть в list() или же вместо reversed() воспользоваться срезом [: :-1];
- она не сортирует элементы, а возвращает их в обратном порядке, то есть читает с конца списка;
- из предыдущего пункта понятно, что если у нас коллекция неиндексированная — мы не можем вывести её элементы в обратном порядке и эта функция к таким коллекциям не применима — получим «TypeError: argument to reversed() must be a sequence»;
- не позволяет использовать дополнительные аргументы — будет ошибка «TypeError: reversed() does not take keyword arguments».
my_list = [2, 5, 1, 7, 3] my_list_sorted = reversed(my_list) print(my_list_sorted) # print(list(my_list_sorted)) # [3, 7, 1, 5, 2] print(my_list[::-1]) # [3, 7, 1, 5, 2] - тот же результат с помощью среза3.3 Методы списка .sort() и .reverse()
У списка (и только у него) есть особые методы .sort() и .reverse() которые делают тоже самое, что соответствующие функции sorted() и reversed(), но при этом:
- Меняют сам исходный список, а не генерируют новый;
- Возвращают None, а не новый список;
- поддерживают те же дополнительные аргументы;
- в них не надо передавать сам список первым параметром, более того, если это сделать — будет ошибка — не верное количество аргументов.
my_list = [2, 5, 1, 7, 3] my_list.sort() print(my_list) # [1, 2, 3, 5, 7] Обратите внимание: Частая ошибка начинающих, которая не является ошибкой для интерпретатора, но приводит не к тому результату, который хотят получить.
my_list = [2, 5, 1, 7, 3] my_list = my_list.sort() print(my_list) # None 3.4 Особенности сортировки словаря
В сортировке словаря есть свои особенности, вызванные тем, что элемент словаря — это пара ключ: значение.
UPD: Так же, не забываем, что говоря о сортировке словаря, мы имеем ввиду сортировку полученных из словаря данных для вывода или сохранения в индексированную коллекцию. Сохранить данные сортированными в самом стандартном словаре не получится, они в нем, как и других неиндексированных коллекциях находятся в произвольном порядке.
- sorted(my_dict) — когда мы передаем в функцию сортировки словарь без вызова его дополнительных методов — идёт перебор только ключей, сортированный список ключей нам и возвращается;
- sorted(my_dict.keys()) — тот же результат, что в предыдущем примере, но прописанный более явно;
- sorted(my_dict.items()) — возвращается сортированный список кортежей (ключ, значение), сортированных по ключу;
- sorted(my_dict.values()) — возвращается сортированный список значений
my_dict = mysorted = sorted(my_dict) print(mysorted) # ['a', 'b', 'c', 'd', 'e', 'f'] mysorted = sorted(my_dict.items()) print(mysorted) # [('a', 1), ('b', 2), ('c', 3), ('d', 4), ('e', 5), ('f', 6)] mysorted = sorted(my_dict.values()) print(mysorted) # [1, 2, 3, 4, 5, 6] Отдельные сложности может вызвать сортировка словаря не по ключам, а по значениям, если нам не просто нужен список значений, и именно выводить пары в порядке сортировки по значению.
Для решения этой задачи можно в качестве специальной функции сортировки передавать lambda-функцию lambda x: x[1] которая из получаемых на каждом этапе кортежей (ключ, значение) будет брать для сортировки второй элемент кортежа.
population = # отсортируем по возрастанию населения: population_sorted = sorted(population.items(), key=lambda x: x[1]) print(population_sorted) # [('Delhi', 16787941), ('Beijing', 21516000), ('Karachi', 23500000), ('Shanghai', 24256800)] UPD от ShashkovS: 3.5 Дополнительная информация по использованию параметра key при сортировке
Допустим, у нас есть список кортежей названий деталей и их стоимостей.
Нам нужно отсортировать его сначала по названию деталей, а одинаковые детали по убыванию цены.
shop = [('каретка', 1200), ('шатун', 1000), ('седло', 300), ('педаль', 100), ('седло', 1500), ('рама', 12000), ('обод', 2000), ('шатун', 200), ('седло', 2700)] def prepare_item(item): return (item[0], -item[1]) shop.sort(key=prepare_item) Результат сортировки
for det, price in shop: print(' цена: 5>р.'.format(det, price)) # каретка цена: 1200р. # обод цена: 2000р. # педаль цена: 100р. # рама цена: 12000р. # седло цена: 2700р. # седло цена: 1500р. # седло цена: 300р. # шатун цена: 1000р. # шатун цена: 200р. Перед тем, как сравнивать два элемента списка к ним применялась функция prepare_item, которая меняла знак у стоимости (функция применяется ровно по одному разу к каждому элементу. В результате при одинаковом первом значении сортировка по второму происходила в обратном порядке.
Чтобы не плодить утилитарные функции, вместо использования сторонней функции, того же эффекта можно добиться с использованием лямбда-функции.
# Данные скопировать из примера выше shop.sort(key=lambda x: (x[0], -x[1]))- wiki.python.org/moin/HowTo/Sorting#Key_Functions (на английском).
- habrahabr.ru/post/319200/#comment_10011882 — еще один комментарий с детальным примером ShashkovS к данной статье
UPD от ShashkovS: 3.6 Устойчивость сортировки
Допустим данные нужно отсортировать сначала по столбцу А по возрастанию, затем по столбцу B по убыванию, и наконец по столбцу C снова по возрастанию.
Если данные в столбце B числовые, то при помощи подходящей функции в key можно поменять знак у элементов B, что приведёт к необходимому результату.
А если все данные текстовые? Тут есть такая возможность.
Дело в том, что сортировка sort в Python устойчивая (начиная с Python 2.2), то есть она не меняет порядок «одинаковых» элементов.
Поэтому можно просто отсортировать три раза по разным ключам:
data.sort(key=lambda x: x['C']) data.sort(key=lambda x: x['B'], reverse=True) data.sort(key=lambda x: x['А']) Дополнительная информация по устойчивости сортировки и примеры: wiki.python.org/moin/HowTo/Sorting#Sort_Stability_and_Complex_Sorts (на наглийском).
Приглашаю к обсуждению:
- Если я где-то допустил неточность или не учёл что-то важное — пишите в комментариях, важные комментарии будут позже добавлены в статью с указанием вашего авторства.
- Если какие-то моменты не понятны и требуется уточнение — пишите ваши вопросы в комментариях — или я или другие читатели дадут ответ, а дельные вопросы с ответами будут позже добавлены в статью.