Noise Reduction in an Audio file using Python [closed]
Closed. This question is seeking recommendations for books, tools, software libraries, and more. It does not meet Stack Overflow guidelines. It is not currently accepting answers.
We don’t allow questions seeking recommendations for books, tools, software libraries, and more. You can edit the question so it can be answered with facts and citations.
Closed 6 years ago .
We can perform noise reduction using Open-source Software like Audacity, which is commonly used for the purpose. Please click the below link for reference. denoising with audacity image Is there a python library that can perform a similar function?
2,237 7 7 gold badges 20 20 silver badges 33 33 bronze badges
asked Jul 15, 2017 at 12:17
samourayonly samourayonly
191 1 1 gold badge 1 1 silver badge 6 6 bronze badges
yeah there is lots of libraries which can do this
Jul 15, 2017 at 12:20
Thanks you for your answer @Arpit Solanki.I tried the scipy.filtfilt function but it smoothed the signal but didn’t remove the noise.Do you know what librarie i could use?
Jul 15, 2017 at 12:55
@samourayonly Updated my answer including a general guideline.
Jul 15, 2017 at 13:16
Thanks you so much @RussellB. I just applied a high-pass filter with audacity and it did the same work that the noise reduction. Now i know that i must use a high-pass filter.
Jul 15, 2017 at 13:45
1 Answer 1
If you want to reduce noise the audacity way, to my understanding, you should program your algorithm using scipy filters provided by scipy library.
Besides that pyaudio is one dedicated library for audio analysis and here is a kickstart tutorial.
If you are not restricted only to Python , you can check out on Essentia. This is by far an exhaustive library for music and audio analysis.
Nutshell: While python libraries provide functionalities, it is you who should code your noise reduction algorithm (tailored to your needs). May be you can follow the audacity’s approach.
You can refer this question for better, technical/implementation, clarity: Noise reduction on wave file
Good luck! Try to be precise and post questions focusing on implementation pertaining to programming languages rather than generic things.
As a general guideline: Understand the behavior of your noise and then you can choose your noise removal strategy accordingly.May be you need a simple low pass filter or high-pass filter.
Filtering a wav file using python
So i recently successfully built a system which will record, plot, and playback an audio wav file entirely with python. Now, I’m trying to put some filtering and audio mixing in between the when i record and when i start plotting and outputting the file to the speakers. However, i have no idea where to start. Right now I’m to read in a the intial wav file, apply a low pass filter, and then re-pack the newly filtered data into a new wav file. Here is the code i used to plot the initial data once i recorded it.
import matplotlib.pyplot as plt import numpy as np import wave import sys spf = wave.open('wavfile.wav','r') #Extract Raw Audio from Wav File signal = spf.readframes(-1) signal = np.fromstring(signal, 'Int16') plt.figure(1) plt.title('Signal Wave. ') plt.plot(signal) And here is some code i used to generate a test audio file of a single tone:
import numpy as np import wave import struct freq = 440.0 data_size = 40000 fname = "High_A.wav" frate = 11025.0 amp = 64000.0 sine_list_x = [] for x in range(data_size): sine_list_x.append(np.sin(2*np.pi*freq*(x/frate))) wav_file = wave.open(fname, "w") nchannels = 1 sampwidth = 2 framerate = int(frate) nframes = data_size comptype = "NONE" compname = "not compressed" wav_file.setparams((nchannels, sampwidth, framerate, nframes, comptype, compname)) for s in sine_list_x: wav_file.writeframes(struct.pack('h', int(s*amp/2))) wav_file.close() I’m not really sure how to apply said audio filter and repack it, though. Any help and/or advice you could offer would be greatly appreciated.
asked Jul 23, 2014 at 20:29
345 3 3 gold badges 4 4 silver badges 12 12 bronze badges
Have you tried looking at scipy ‘s lfilter?
Jul 23, 2014 at 20:35
Rather than the for loop to generate the sinusoid, you want something like sine_signal = np.sin(2*np.pi*freq*(np.arange(data_size)/frate)) , then something like wav_file.writeframes((sine_signal*amp/2).astype(‘h’).tostring()) .
Jul 24, 2014 at 14:27
2 Answers 2
First step : What kind of audio filter do you need ?
Choose the filtered band
- Low-pass Filter : remove highest frequency from your audio signal
- High-pass Filter : remove lowest frequencies from your audio signal
- Band-pass Filter : remove both highest and lowest frequencies from your audio signal
For the following steps, i assume you need a Low-pass Filter.
Choose your cutoff frequency
The Cutoff frequency is the frequency where your signal will be attenuated by -3dB.
Your example signal is 440Hz, so let’s choose a Cutoff frequency of 400Hz. Then your 440Hz-signal is attenuated (more than -3dB), by the Low-pass 400Hz filter.
Choose your filter type
Filter design is beyond the scope of Stack Overflow — that’s a DSP problem, not a programming problem. Filter design is covered by any DSP textbook — go to your library. I like Proakis and Manolakis’ Digital Signal Processing. (Ifeachor and Jervis’ Digital Signal Processing isn’t bad either.)
To go inside a simple example, I suggest to use a moving average filter (for a simple low-pass filter).
Mathematically, a moving average is a type of convolution and so it can be viewed as an example of a low-pass filter used in signal processing
This Moving average Low-pass Filter is a basic filter, and it is quite easy to use and to understand.
The parameter of the moving average is the window length.
The relationship between moving average window length and Cutoff frequency needs little bit mathematics and is explained here
The code will be
import math sampleRate = 11025.0 cutOffFrequency = 400.0 freqRatio = cutOffFrequency / sampleRate N = int(math.sqrt(0.196201 + freqRatio**2) / freqRatio) So, in the example, the window length will be 12
Second step : coding the filter
Hand-made moving average
Solution from Alleo is
def running_mean(x, windowSize): cumsum = numpy.cumsum(numpy.insert(x, 0, 0)) return (cumsum[windowSize:] - cumsum[:-windowSize]) / windowSize filtered = running_mean(signal, N) Using lfilter
Alternatively, as suggested by dpwilson, we can also use lfilter
win = numpy.ones(N) win *= 1.0/N filtered = scipy.signal.lfilter(win, [1], signal).astype(channels.dtype) Third step : Let’s Put It All Together
import matplotlib.pyplot as plt import numpy as np import wave import sys import math import contextlib fname = 'test.wav' outname = 'filtered.wav' cutOffFrequency = 400.0 # from http://stackoverflow.com/questions/13728392/moving-average-or-running-mean def running_mean(x, windowSize): cumsum = np.cumsum(np.insert(x, 0, 0)) return (cumsum[windowSize:] - cumsum[:-windowSize]) / windowSize # from http://stackoverflow.com/questions/2226853/interpreting-wav-data/2227174#2227174 def interpret_wav(raw_bytes, n_frames, n_channels, sample_width, interleaved = True): if sample_width == 1: dtype = np.uint8 # unsigned char elif sample_width == 2: dtype = np.int16 # signed 2-byte short else: raise ValueError("Only supports 8 and 16 bit audio formats.") channels = np.fromstring(raw_bytes, dtype=dtype) if interleaved: # channels are interleaved, i.e. sample N of channel M follows sample N of channel M-1 in raw data channels.shape = (n_frames, n_channels) channels = channels.T else: # channels are not interleaved. All samples from channel M occur before all samples from channel M-1 channels.shape = (n_channels, n_frames) return channels with contextlib.closing(wave.open(fname,'rb')) as spf: sampleRate = spf.getframerate() ampWidth = spf.getsampwidth() nChannels = spf.getnchannels() nFrames = spf.getnframes() # Extract Raw Audio from multi-channel Wav File signal = spf.readframes(nFrames*nChannels) spf.close() channels = interpret_wav(signal, nFrames, nChannels, ampWidth, True) # get window size # from http://dsp.stackexchange.com/questions/9966/what-is-the-cut-off-frequency-of-a-moving-average-filter freqRatio = (cutOffFrequency/sampleRate) N = int(math.sqrt(0.196196 + freqRatio**2)/freqRatio) # Use moviung average (only on first channel) filtered = running_mean(channels[0], N).astype(channels.dtype) wav_file = wave.open(outname, "w") wav_file.setparams((1, ampWidth, sampleRate, nFrames, spf.getcomptype(), spf.getcompname())) wav_file.writeframes(filtered.tobytes('C')) wav_file.close() Как убрать лишние звуки из аудио python
Здравствуйте, если вы зашли сюда. то вполне возможно вы встречались со следующей проблемой.
Когда необходимо убрать шумы, а также нормализовать аудиофайл (формат .wav), а также убрать пустые пробелы в аудиозаписи.
Знаю, что уйма библиотек для редактирования именно видеофайлов, но изначально оно не задумывалось для обработки только аудио.
В моём случае необходимо обработать только аудио, причём в автоматическом режиме. ИИ, к сожалению, не пойдёт, тк сейчас не имею возможности как-нибудь обучать и т.д.
Таким образом, возможно вы встречались с данной задачей и благополучно решили её, поделитесь своим опытом =)
P.S> обыскал всё, но пока не нашёл то, что мне нужно.
94731 / 64177 / 26122
Регистрация: 12.04.2006
Сообщений: 116,782
Ответы с готовыми решениями:
Есть ли библиотека для обработки звука??
Здраствуйте, нужна бесплатная библиотека для обработки звука, что можете посоветовать?
Библиотека bass, амплитуда сигнала (wav)
Здравствуйте, в силу некоторых причин у меня появилась задача написать программу которая бы.

Подскажите модуль для обработки Wav в RAW
Нужно определиться с модулем Pyton для выполнения следующих операций с wav-файлами: 1. свести.
Запись звука в WAV файл на Python. Библиотека sounddevice, playsound
Здравствуйте, программисты. Буду благодарен вашей помощи. Недавно начал изучать язык python и.
Удаление фрагментов аудио из файла по образцу
Есть задача удалить из аудио-дорожки видео файла некоторые фрагменты по образцу. Например, щелчки, хлопки, цоканье и т.п.
То есть берутся образцы звуков на вычищение и входные файлы (видео с аудио-дорожкой или просто аудио), на выходе — файлы, очищенные от звуков, подобных заданным сэмплам.
Возможно, тут понадобится machine learning, и на первом этапе будут на входе только звуковые сэмплы, чтобы получить некую модель, а на втором этапе эта модель будет применяться для очистки файлов.
В найденных фрагментах — либо просто заглушать в ноль всё аудио (на либо вычленять только сам звук, подходящий по характеристикам, оставляя все остальные звуки как есть. В принципе, первое проще, и этого достаточно. Второе — уже совсем в идеале.
Буду использовать Kotlin или Python, в зависимости от того, для какой платформы найдутся подходящие библиотеки.
Можете подсказать, какие библиотеки можно использовать для решения такой задачи?
P.S.:
Если вдруг уже существует какой-нибудь простой инструмент, который может делать это (выбрать фрагменты и удалить подобные в пачке файлов), было бы интересно узнать.
�� Подобається Сподобалось 0
До обраного В обраному 0

Дозволені теги: blockquote, a, pre, code, ul, ol, li, b, i, del.
Ctrl + Enter
32 коментарі
Дозволені теги: blockquote, a, pre, code, ul, ol, li, b, i, del.
Ctrl + Enter
Victor Gubin Programmer 02.01.2021 08:13
Gstreamer и Tensorflow. Но придется модель обучать. 2. Сразу вангую — переходи на C++ сильно проще будет с API и т.д.
Victor Gubin Programmer 02.01.2021 09:05
TF — это C++ с возможностью дергать ее из python (binding frontend) в том числе, что для разного рода маркетологов намного удобнее потому что для них программирование не профильная деятельность. C++ надмножество C, любые C библиотеки легко используются из C++ без дополнительных телодвижений, в чем и заключается очень большое преимущество. Впрочем если вы найдёте хорошие bindings к Java/Scala или к python (а они есть) то дерзайте.
Victor Gubin Programmer 03.01.2021 02:30
Старые версии не застал. Сейчас документация ± ok как и инпутами. Примеры прямо на сайте. Блазер только раздражает, почему они не делают цмейк как все — я хз.
Второе — это очень сложно делать даже руками. Невероятно сложно
Włodzimierz Rożkow інфлюенсер в t.me/full_of_hatred 27.12.2020 22:49
Dmytro Hrebeniuk Mobile Software Enginner в Self-Employment 27.12.2020 13:24
У вас задача: найти фрагмент в дорожке и вырезать из таймлайна или подавить этот звук но при этом оставить фоновый?
Если вариант 1, то с помощью нейронов не сложно делать:
* Формируете dataset со звуками
* Разделяете аудио на фреймы
* Перегоняете через фреймы STFT
* Обучаете классификатор
* Определяете какой типа звука находится в этом коротком фрейме
* Вырезаете
* Profit
Если вариант 2 то это все намного сложнее, но варианты решения используя те же GAN тоже есть.
* Формируете dataset — с подавленными звуками и с обычными
* Разделяете аудио на фреймы
* Перегоняете через фреймы STFT
* создаете pipeline для обучения и подбираете какую-то удачную архитектуру для GAN
* обучаете
* перегоняете аудио фреймы обратно через Inverse STFT(еще надо проблемы с фазой решить)
* Profit
Victor Musienkо Senior Engineer в Noibu.com 02.01.2021 03:25
Victor Musienkо Senior Engineer в Noibu.com 02.01.2021 08:10
Ну кто вас знает, мб вы боги ML
Полно разных тулзов в инете. Я удалял звук дрона, который висел передо мной, чтобы оставался только мой голос. Но результат далеко не идеальный будет
Звук дрона имеет чётко выраженный характер волны, если быть точным, 4 волн. Со всей вытекающей спектралкой. То есть идеально не будет, поскольку он глушит сам сенсор, превышая его амплитуду восприятия. Но можно попробовать поймать волновые составляющие голоса, и по сути оставить только их.
А реально с дрона писать звук — дохлый номер, для этого надо ему присобачить микрофон на проводе, ну или сделать очень направленный с суперкардиоидой — но придётся пободаться подвеску делать, хотя результат может того стоить.
Хороший результат может дать использование микрофонной матрицы. Хотя как по мне, лучше решать вопрос в лоб, и в место дрона с 4 винтами летать вертолётом с одним несущим винтом — и тогда не иметь столь сильных помех, снизив обороты. Но и тогда нужен хороший сенсор звука и запись в формат, позволяющий брать весь размах амплитуды.
Paul Loyanich CTO в CoreDev 27.12.2020 12:30
летать вертолётом с одним несущим винтом
такой не сможет зависнуть.
Прекрасный ответ, я уж думал как без таких советчиков обошлось, неужто подводное членистоногое на каменной возвышенности извергло сигнал звуковой частоты в высокой части спектра с выраженным резонансным пиком
Звук дрона — это равномерный фоновый шум, это другой случай. А я хочу удалять короткие звуки, отличающиеся неким всплеском.
Инструментов нет, ни простых, ни сложных. Причина в природе самого сигнала и помехи. Они живут на одних частотах. А значит либо нужно опознавать сам сигнал и перевоспроизводить его заново генератором, либо мириться с примитивной спектральной чисткой.
Типичный способ избавиться от шипящих шумов — эхо. Грубо говоря, переотражение с АЧХ-сдвигом. Это то, что тебе сделает редактор. А уж как писать скрипт под редактор, который тебе понравился — RTFM.
Пойми, кроме сэмпла нужен ещё и критерий, по которому этот сэмпл считается на что-то похожим. Потому что это твой мозг умеет опознавать эти сэмплы, зная примерно возможный их источник. А компьютеру сие неведомо, и он не сможет убрать, скажем, пердёж, с твоей пафосной речуги. Потому что пердёж пердежу рознь, настолько что можно симфонию сложить.
Я примерно понимаю цель: почистить от шумов и распознать. Но фокус в том, что для выделения сигнала от шума, как раз и требуется распознать сигнал. Не шум. Именно это делаешь ты, когда пытаешься что-то расслышать. Не веришь — попробуй распознать от шума разговор на малознакомом тебе языке. Шансов ноль.
Если нужно распознавать разговор, сделай на эквалайзере повышение частот именно там, где имеет место резонанс в человеческом ухе. Поидее алгоритмы распознавания (качественные) и сами должны это делать, но ради эксперимента попробуй. Не забывай перевести звук в формат с плавающей точкой, либо же уменьшить громкость — иначе тебе после преобразования не хватит запаса амплитуды и ты получишь ещё помех.
Общий смысл такой: сперва добейся. Сделай в редакторе то что тебе требуется, и когда будешь доволен качеством — ищи фильтры, которые из командной строки могут сделать требуемый тебе эффект. Но всегда помни, что распознавать будешь не ты, а программа, поэтому не верь себе на слух, давай итог правки на тест распознавателю.
Не идеальны — не то слово. Но можно подобрать параметры при которых искажения оставшегося звука будут не особо критичны. Я и предлагаю ТС взять редактор, сначала сделать руками, а уже потом написать скрипт или под сам редактор, или под программу автоматизации — которая будет вызываться из батника, а батник будет по очереди подменять одну и ту же ссылку на файлы по списку, после чего запускать прогу, которая будет давить нужные кнопки, в идеале, горячие клавиши.
Это тоже вполне нормальный вариант. Знать бы только какой редактор и какой плагин брать.
Разбираемся, как подавить шум в речи с помощью глубокого обучения и OpenVINO
Данная статья будет полезна студентам и тем, кто хочет разобраться с тем, как происходит шумоподавление речи (Speech Denoising) с помощью глубокого обучения. На Хабре уже были статьи по данной тематике несколько лет назад (раз, два), но нашей целью является желание дать несколько более глубокое понимание процесса работы со звуком.

Задача шумоподавления с помощью глубокого обучения и OpenVINO попала в руки к студентам ITlab – учебно-исследовательской лаборатории Университета Лобачевского при поддержке компании Intel. Студенты, начиная со 2 курса, под руководством преподавателей работают над интересными инженерными и научными проектами. Создание высокопроизводительного программного обеспечения требует применения специальных инструментов разработчика и технологий параллельного исполнения кода, и в рамках проектов лаборатории студенты с ними знакомятся. Данная статья является результатом работы студентов Вихрева Ивана, Рустамова Азера, Зайцевой Ксении, Кима Никиты, Бурдукова Михаила, Филатова Андрея.
Что есть звук в компьютере
Подавление фонового шума речи беспокоит людей уже очень давно, а с приходом дистанционной работы и обучения значимость проблемы возникла многократно. Разговаривать через интернет приходится все больше, и аудиосообщения встроены во все популярные мессенджеры. Как бы банально не звучало, но хороший, чистый звук человек воспринимает лучше. Однако хороший микрофон стоит денег, да и звукоизоляция в среднестатистической квартире оставляет желать лучшего, и мы слышим всё — от работы кулеров в ноутбуке и заканчивая дрелью надоедливого соседа (шум дрели у преподавателя особо мешает восприятию материала).
Как получить чистый звук, не покупая студийный микрофон и не обивая всю квартиру звукоизолирующими материалами? Над этим вопросом люди думают ещё с конца прошлого века. Решением стали программы, оцифровывающие и редактирующие входящий из микрофона звук.

Записанный звук состоит из множества звуковых волн, одновременно попадающих на датчик микрофона в некоторый промежуток времени, в результате чего мы получаем длинный вектор из чисел — это амплитуды (громкость) сигнала в течение небольшого времени. Частота сигнала проводного телефона 8kHz, это значит что мы за секунду 8000 раз измеряем амплитуду (громкость) суммарного сигнала, звуковые карты как правило используют частоту 44.1 или 48kHz.

Воспроизвести аудиофайл в Python можно с помощью библиотек soundfile и sounddevice.
import sounddevice as sd import soundfile as sf path_wav = 'test_wav.wav' data, fs = sf.read(path_wav) sd.play(data, fs) status = sd.wait()Запись данных с микрофона тоже происходит очень просто — посмотрите и запустите record.py.
Кстати, важная для нас информация. Наша последовательность является суммой множества звуковых волн, и мы можем вычислить какие волны приняли участи в нашей сумме. Теоретически, любой сложный звук может быть разложен на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду и может быть описан числовыми параметрами (а вы говорили, что матан не нужен). Исследования по данной тематике входят в область цифровой обработки сигналов, на хабре есть информация об открытом курсе «Основы цифровой обработки сигналов».
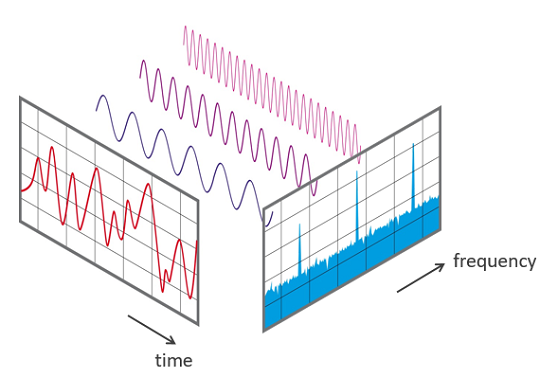
Чтобы делать с аудио сложные вещи, такие как распознавание человека по голосу, перевод речи речи в текст или удаление шума с помощью глубокого обучения, нам понадобится вычислить вклад различных частот в аудиопоследовательность — спектр. Спектр можно представить в виде спектрограммы — изображения, показывающего зависимость амплитуды сигнала во времени на различных частотах. Один столбец в спектрограмме соответствует спектру короткого участка исходного сигнала, более тёплые тона означают большее значение.

Спектр для спектрограммы можно вычислить с помощью дискретного преобразования Фурье, реализованного в библиотеке Numpy. Рассмотрим пример создания спектрограммы, описанный в сэмпле. Для этого используются две функции из файла features.py:
def calcSpec(y, params, channel=None): """compute complex spectrum from audio file""" fs = int(params["fs"]) # Константа, обозначающая частоту дискредитации # В нашем случае равна 16000 - наш wav файл записан с частотой 16 кГц if channel is not None and (len(y.shape)>1): # Если аудио содержит два канала (стерео) - берем только один канал sig = sig[:,channel] # STFT parameters N_win = int(float(params["winlen"])*fs) # Расчёт размера окна Хэннинга # В нашем случае 320 if 'nfft' in params: N_fft = int(params['nfft']) else: N_fft = int(float(params['winlen'])*fs) # Расчёт ширины окна для преобразования Фурье # В нашем случае 320 N_hop = int(N_win * float(params["hopfrac"])) # Расчёт прыжка для преобразования Фурье # В нашем случае 160 win = np.sqrt(np.hanning(N_win)) # Окно Хэннинга Y = stft(y, N_fft, win, N_hop) return Y Функция Stft проводит преобразование Фурье. Массив делится на части определённой длины (рассчитанной в calcSpec) и для каждой из частей применяется функция преобразования Фурье, взятая из Numpy возвращает готовую спектрограмму.
def stft(x, N_fft, win, N_hop, nodelay=True): """ short-time Fourier transform x - Входной сигнал N_fft - Количество точек, на которых используется преобразование win - Окно Хэннинга N_hop - Размер прыжка nodelay - Удаление первых точек из конечного массива (В них появляется побочный эффект преобразования) """ # get lengths if x.ndim == 1: x = x[:,np.newaxis] # Если подано несколько файлов, то создаётся дополнительная ось Nx = x.shape[0] # Количество точек во входных данных (в нашем случае 160000) M = x.shape[1] # Количество файлов во входных данных (в нашем случае 1) specsize = int(N_fft/2+1) N_win = len(win) # Размер окна Хэннинга N_frames = int(np.ceil( (Nx+N_win-N_hop)/N_hop )) # На сколько частей делим входной массив Nx = N_frames*N_hop # padded length x = np.vstack([x, np.zeros((Nx-len(x),M))]) # init X_spec = np.zeros((specsize,N_frames,M), dtype=complex) # Заполненная нулями матрица, которая станет спектрограммой win_M = np.outer(win,np.ones((1,M))) # Создаём матрицу, в которой каждый столбец равен окну Хэннинга x_frame = np.zeros((N_win,M)) # Заполненный нулями вектор (вектора в случае если на вход дали несколько файлов) for nn in range(0,N_frames): idx = int(nn*N_hop) x_frame = np.vstack((x_frame[N_hop. ], x[idx:idx+N_hop,:])) # Разделяем входной массив на куски размера N_hop x_win = win_M * x_frame X = np.fft.rfft(x_win, N_fft, axis=0) # Преобразование возвращает столбец комплексных, где действительная часть - амплитуда, а комплексная - фазовый сдвиг X_spec[:,nn,:] = X # Добавляем полученный столбец в спектрограмму if nodelay: delay = int(N_win/N_hop - 1) X_spec = X_spec[:,delay. ] # Удаляем лишний столбец из начала if M==1: X_spec = np.squeeze(X_spec) # Удаляем лишнюю ось return X_specТакже важной функцией является calcFeat, позволяющая нам прологарифмировать спектрограмму, растягивая нижние частоты и сжимая верхние. Голос человека лежит в диапазоне 85-3000Гц, а диапазон звуковых частот в нашей записи 16кГц — маленький промежуток на всем диапазоне, и помощью логарифмирования мы “растягиваем” нужные нам низкие частоты и “поджимаем” ненужные высокие
def calcFeat(Spec, cfg): """compute spectral features""" if cfg['feattype'] == "MagSpec": inpFeat = np.abs(Spec) elif cfg['feattype'] == "LogPow": pmin = 10**(-12) powSpec = np.abs(Spec)**2 # Все значения спектрограммы возводятся в квадрат inpFeat = np.log10(np.maximum(powSpec, pmin)) # и логарифмируются с обрезанием слишком низких значений else: ValueError('Feature not implemented.') return inpFeat Наша глубокая модель удаления шума обучена на логарифмированных спектрограммах, поэтому предобработка данной функцией обязательна. Чтобы преобразовать спектрограмму, полученную применением фильтра (выход нейросети) на образ-Фурье, полученный с помощью функции calcSpec, в звук используется функция Spec2sig. В ней вычисляются параметры обратного преобразования Фурье и вызывается функция istft (обратное быстрое преобразование Фурье).
def spec2sig(Spec, params): """Конвертирует спектрограмму в звук""" # частота дискретизации fs = int(params["fs"]) # ширина окна N_win = int(float(params["winlen"])*fs) if 'nfft' in params: N_fft = int(params['nfft']) else: # длина быстрого преобразования Фурье N_fft = int(float(params['winlen'])*fs) #длина сегментов окна N_hop = int(N_win * float(params["hopfrac"])) # окно Хеннинга win = np.sqrt(np.hanning(N_win)) # обратное преобразование Фурье x = istft(Spec, N_fft, win, N_hop) return xВ istft обратное преобразование Фурье также выполняется при помощи функции взятой из Numpy.
def istft(X, N_fft, win, N_hop): # get lengths specsize = X.shape[0] # Спектрограмма N_frames = X.shape[1] # кол-во кадров if X.ndim < 3: X = X[. np.newaxis] # Приведение размера до 3 M = X.shape[2] # кол-во каналов N_win = len(win) # длина окна хеннинга Nx = N_hop*(N_frames - 1) + N_win # Умножение матрицы win и единичной матрицы размера 1,M win_M = np.outer(win,np.ones((1, M))) x = np.zeros((Nx,M)) # нулевая матрица Nx,M для сохранения ответа for nn in range(0, N_frames): X_frame = np.squeeze(X[:,nn,:]) # Вектор по данному фрейму # обратное преобразование фурье для X_frame ,N_fft x_win = np.fft.irfft(X_frame, N_fft, axis=0) x_win = x_win.reshape(N_fft,M) # изменяем размер # получаем окно хеннинга нужного размера x_win = win_M * x_win[0:N_win,:] # добавляем результат для данного фрейма idx1 = int(nn*N_hop); idx2 = int(idx1+N_win) x[idx1:idx2,:] = x_win + x[idx1:idx2,:] if M == 1: x = np.squeeze(x) # Убираем лишние измерения если канал один return xЗвуковой сигнал, записываемый в реальных акустических условиях, часто содержит нежелательные шумы, которые могут порождаться окружающей средой или звукозаписывающей аппаратурой. Значит, полученное цифровое описание также будет содержать нежелательные шумы.

Чтобы “очистить” звук, к цифровому описанию необходимо применить фильтр, который убирает нежелательные шумы. Но возникает другая проблема. Каждый из видов шумов требует свой фильтр, который необходимо подбирать вручную или искать в банках данных фильтров. Отфильтровать шум на частотах, отличающихся от человеческой речи, проблем нет, от них избавлялись еще до этих ваших нейросетей. А вот убрать детский плач или стучание клавиш без значительного ухудшения качества голоса было проблематично.
В решении данной проблемы могут помочь модели глубокого обучения. Основное преимущество нейросетей перед заранее подготовленными фильтрами заключается в большем охвате различных видов шумов. Нейросеть можно натренировать, постоянно добавляя всё новые виды шума.
В нашем случае мы воспользуемся моделью NSNet2. Эта нейронная сеть использовалась в Deep Noise Suppression Challenge, проводимом компанией Microsoft. Целью разработки данной сети было создание модели для очистки звука от шума в реальном времени. Данная модель состоит из полносвязного слоя с ReLU, двух рекуррентных GRU (Gated Recurrent Unit) блоков и полносвязных слоев (FF, feed forward) с ReLU и sigmoid активацией.

На речь влияет большое количество внешних условий. Человек может говорить громко или тихо, быстро или медленно, говорить он может в большой комнате или в маленькой, далеко от микрофона или близко к нему. Для моделирования этих более сложных условий, были применены аугментации. В частности, в данном случае, для модификации звука использовались случайные биквадратные фильтры. Благодаря применения таких аугментаций, зашумление звука наиболее приближено к реальным условиям.
Представленные результаты по качеству работы можно посмотреть в статье Data augmentation and loss normalization for deep noise suppression. Построенная модель имеет хорошие показатели для различных типов шума.
Конвертация модели в OpenVINO
При работе с нашей моделью мы использовали OpenVINO (Open Visual Inference & Neural Network Optimization) - продукт, разрабатываемый компанией Intel. Как видно из названия, OpenVINO - это набор инструментов для исполнения и оптимизации нейронных сетей.
Существует множество фреймворков для создания и тренировки нейросетей. Для того, чтобы можно было запускать нейросети из различных фреймворков на любом интеловском железе, в составе OpenVINO есть модуль Model Optimizer.

По факту, Model Optimizer - это набор python-скриптов, которые позволяют привести нейронные сети различных форматов к некоторому универсальному представлению, называемому IR (Intermediate Representation). Это позволяет OpenVINO работать с любой нейросетью, независимо от того, из какого фреймворка она взята.
В процессе своей работы Model Optimizer также оптимизирует структуру сверточных нейронных сетей. Например, объединяя результаты сверток, заменяя слои на последовательность линейных операций и т.д.

В последнее время, с появлением API, в Model Optimizer проводится все меньше оптимизаций, и основная его работа сводится к конвертации моделей без каких-либо серьезных изменений.
Конвертация в IR-представление различается для моделей из Open Model Zoo и других моделей. Open Model Zoo – репозиторий глубоких нейросетевых моделей, содержащий большое количество обученных моделей, которые могут исполняться при помощи OpenVINO. Данный репозиторий хранит не только модели, но и параметры для конвертации моделей из разных фреймворков в промежуточный формат OpenVINO.
Для конвертации моделей, загруженных из Open Model Zoo, нужно воспользоваться инструментом Model Optimizer и входящим в него скриптом converter.py. Данный модуль имеет доступ к параметрам конвертации моделей из зоопарка моделей.
Консольная команда для конвертации загруженной модели:
python converter.py --name --download_dir
Чтобы сконвертировать собственную модель, необходимо использовать скрипт mo.py с дополнительными параметрами:
python mo.py --input_model --output_dir --input_shape
Для конвертации нашей ONNX модели в формат OpenVINO (в Windows) вышеприведенная команда выглядит так:
python mo.py --input_model \nsnet2-20ms-baseline.onnx -output_dir --input_shape [1, 1000, 161] где 1 - количество каналов, 1000 - временных интервалов, 161 - частот.
Также, можно указать больше дополнительных параметров для удобства. Весь список возможных параметров можно посмотреть командой:
python mo.py --helpОтличие converter.py от mo.py лишь в том, что converter.py использует параметры для конвертации из описания модели в Open Model Zoo и передает их в mo.py
Надо отметить, что проблема шумоподавления до сих пор не решена полностью. Методике улучшения речи с помощью нейронных сетей в последнее время уделяется огромное внимание как в научных исследованиях, так и в коммерческих приложениях. Одним из важнейших преимуществ использования нейронных сетей для подавления шума является то, что они способны очищать звук от нестационарных шумов. Ранее известные подходы не позволяли этого сделать.
Нейросети не идеальны и избавиться абсолютно ото всех шумов не представляется возможным. Однако, представленная модель показала хорошие результаты в очистке речи в “домашних” условиях.
- глубокое обучение
- openvino
- шумоочистка
нейросеть Deepface
Нейросеть умеет распознавать лица. Процесс прост — сравниваем две фотографии и она говорит с какой долей вероятности на обоих фотографиях один и тот же человек.
1
Я проверил на своих фотографиях. Две фото в фас распознало отлично:

2
Сравнение фотографий одна из которых со смещенным ракурсом уже не сработало, не помогла даже фуражка:

3
Самое интересное, что для процесса сравнения можно использовать разные предобученные модели от всяких крутых контор типа Google и Facebook: VGG-Face , Google FaceNet, OpenFace, Facebook DeepFace, DeepID, ArcFace, Dlib.
Автор даже сделал обзор и тесты на все эти модели. Самая лучшая оказалась Facenet от Facebook. Но и она не смогла справиться с моим фото в ракурсе.
4
Прикольная штука. DeepFace может в режиме реального времени отслеживать эмоции.
Распознает сносно, но нужен мощный компьютер, видео на моем маке с i5 под капотом тормозит. Думаю, что любая более-менее мощная видеокарта это дело поправит.




5
Ещё она умеет определять пол, расу и возраст. На некоторых фотографиях мне нейросеть нагадала 48 лет. Я обиделся на нее окончательно.
Еремин Л.В. Оцифровка и реставрация звука
Руководство уже устарело в плане того, что здесь разбирается обработка в программе Adobe Audition версии 2.0. Эта версия была выпущена в 2002 году, почти 20 лет назад (!). В самом же руководстве тема реставрации звука дана не в самой доходчивой форме и на мой взгляд неполно. Для понимания текста требуется предварительная подготовка. Но, из положительных моментов можно сказать, что довольно детально разобраны несколько фильтров, которые применяются и сейчас. В тексте есть различные определения каких-либо явлений. Интересные факты полезные для понимания природы звука в целом.
Архивотерапия
Этот текст написан для того, что бы его отправлять в случае необходимости в качестве ответа на очередной призыв спасать фольклор.
Вдохновил меня на это Сергей Николаевич Старостин, а идея была позаимствована у хорошего аналогичного текста непривет . Ознакомьтесь на досуге и с ним тоже. Не помешает.
Итак, периодически в интернете всплывает очередной призыв к спасению фольклора. Как правило содержание призыва сводится к тому, что нужно спасать архивы, нужно их оцифровывать, выкладывать в интернет и вообще что-то делать. Гибнет культура русского народа и всё в таком духе. Последний прочитанный мной призыв был подкреплен тремя фотографиями автора в разных позах. Для чего это было сделано мне неясно, но к спасению фольклора отношение имело явно весьма посредственное.
Делать что-то надо. Есть проблема, точнее две проблемы.
1) Пропадает культурное наследие
2) Сильное беспокойство по этому поводу (фрустрация)
Вывод напрашивается сам собой, надо идти и спасать и тем самым избавляться от неприятного чувства.
И с этим я как раз могу помочь. У Центра русского фольклора есть что спасать.
Перечень требующихся работ примерно таков:
Есть несколько тысяч единиц разных носителей Фольклорной комиссии, которые не были вывезены в Пушкинский дом и достались на хранение Центру русского фольклора. На сегодняшний день все носители получили свой регистрационный номер.


Так выглядит коробка с бобиной и на ней новый регистрационный номер
Все эти носители и их реестры отсняты на фотоаппарат и выложены в облако.
Задача первая — прочесть надписи на фотографиях и занести эти данные в exel файл вместе с присвоенным номером.

Папки с фотографиями носителей в облаке
Задача вторая — оцифровать эти носители. Часть из них не имеет опознавательных знаков вообще, поэтому в процессе оцифровки нужно прослушать запись и в случае если собиратель продиктовал, что и где он записывает так же внести эти данные в exel файл.
Записи ФК не единственные нуждающиеся в оцифровке. Я привел их лишь для примера.
И на этом работа с материалом не закончится, так как его нужно будет далее заносить в банк данных и описывать уже досконально.
Итак, теперь вы знаете что делать.
К сожалению, мой опыт работы в архиве показывает, что благородного порыва хватает на один — два дня работы. Но, как результат, человек наконец-то избавляется от гложущего его беспокойства по поводу гибнущего наследия. Архивотерапия работает безотказно.
Если вас не устраивает такой оффлайн способ, то у меня есть и удаленный способ.
Спасибо covid-19, он научил нас работать в онлайне!
Для этого я могу вам рассказать о краудфандинге у фольклористов. Бусти, Патреон и прочее в наличии. Пара сотен рублей отправленных на благое дело резко снимают острые приступы беспокойства.
Терапия абсолютно безвредна. Привыкания нет, синдрома отмены тоже.
Создание рабочей копии архива экспедиционных записей
Рабочая копия
В конце концов наступает момент, когда кассеты оцифровали, файлы собрали на один диск и нужна рабочая копия архива, для детальной описи и возможно публикации. На первый взгляд, технических сложностей нет, но, если архив занимает 1-5 терабайт несжатого звука в сложной и неоднородной структуре папок, то о копировании речь уже не идет. Описывать архив лучше на сжатом звуке, а стоимость жестких дисков не настолько еще мала, что бы этим можно было пренебречь.
Перед тем как сжать наш архив, полную копию все-таки придется сделать, но если нет для этого диска достаточного объема, то копировать и сжимать нужно по частям. Главное, что бы это делалось на копии, рекомендую сделать как минимум одну полную копию записей, в идеале же две копии и оригинал, хранить не в одном и том же здании.
Закон о сохранении информации
Сохранность информации прямо пропорциональна количеству копий данной информации.
Конвертация
Есть много программ конвертеров для аудио в том числе и бесплатных и в принципе для нашей задачи может подойти и простой Freemake или Avidemux конвертер, но поскольку мы имеем дело с большим объемом данных, то имеет смысл подумать о более надежном и гибком варианте.
Требования такие: возможность ведения лога конвертации (для того, что бы в случае ошибки можно было понять где произошла поломка и почему), максимальная поддержка существующих форматов и максимальная производительность.
Из бесплатных лучшим выбором будет консольный конвертер ffmpeg.
Он может быть собран из исходников с поддержкой вычислений на GPU
видео карт, что существенно повысит скорость конвертации.
Конвертер распространяется по лицензии GNU GPL, то есть бесплатен. Проект был образован в 2000 году, имеет активное обширное сообщество поддержки и может быть скомпилирован под различные платформы (Windows, Linux, MacOS и так далее). Для ffmpeg существует большое количество графических оболочек облегчающих работу новичкам, но они нас не интересуют, поскольку вся работа у нас производится в консоли.
Операционная система в которой мы конвертируем — Linux, в теории все то же самое можно проделать и в Windows, но это может оказаться нетривиальной задачей и в итоге возможно проще будет запустить Linux Live CD, что бы сделать конвертацию.
В консоли используем встроенную в Linux утилиту find , которая умеет искать файлы как по названию, так и по другим критериям (дата создания, размер, тип файла и прочее). Главной особенностью find является способность программы производить требуемое действие над найденным объектом.
В нашем случае, это будет передача wav файл на конвертацию программе ffmpeg. Вот команда которая запустит конвертацию архива в формат ogg
find ./ -type f -name '*.wav' -execdir ffmpeg -i <> -acodec libvorbis <>.ogg \; 1>>log.txt 2>>err.txtДословно команда делает следующее:
- find ./ -type f -name ’*.wav’ — найти в текущем каталоге тип объекта — файл, имя объекта любое которое оканчивается на .wav
- -execdir ffmpeg -i <> -acodec libvorbis <>.ogg \; — выполнить в текущей директории команду ffmpeg которой передаются следующие аргументы: -i <> имя найденного объекта, -acodec libvorbis применить к нему кодек libvorbis (ogg),
и сохранить его как <>.ogg \; — найденное имя файла с добавлением
расширения .ogg (файл будет сохраняться как audiofile.wav.ogg , конечно можно убрать лишние буквы wav в имени файла, но это может усложнит синтаксис и ухудшит понимание команды для тех, кто никогда не имел дела с консолью Linux). - 1>> log.txt 2>>error.txt — отправить весь вывод выполняемой команды в текстовый файл log.txt, а ошибки в error.txt. Оба файла будут сохранены в той директории откуда была запущена команда find.
Процесс сжатия архива в 2ТБ занимает около суток без применения вычислений на GPU, на процессоре Intel i7, в случае если процесс прошел без каких-либо критических ошибок, мы можем запустить команду удаления всех wav файлов.
find ./ -type f -name '*.wav' -execdir rm -f <> \;rm -f <> — удалить (сокращение от remove) найденный файл.
В итоге из архива размером в 2ТБ мы получаем примерно 80ГБ.
Это не предел, поскольку при сжатии мы использовали настройки кодека по умолчанию, можно добиться более существенного сокращения объема если снизить битрейт и перевести записи в моно.
Донская вязь
Когда-то у нас был ансамбль Донская вязь
Михаил Масловский
Наталья Волкова
Сергей Стерликов
Василий Фоменко
Кирилл Чеботарёв
В 2009 году все это началось, а в 2017 собрались в последний раз.
Я лично считаю, что мы не выдержали испытания студийной записью.
Но было весело, это было хорошее время.
UPD 2022 Ансамбль возродили.
Новый состав:
Михаил Масловский
Кирилл Чеботарёв
Ирина Деревянкина







Это та самая запись в студии, она нам по большей части не понравилась. Писались наложением на один микрофон в домашней студии. Была мысль все это как-то дописать, переписать и довести до ума, но так и не собрались. Пусть будет здесь. Как памятник.
Похожие публикации:
- В чем легко запутаться 100 к 1 ответ
- В чем преимущество контейнеров перед виртуальными машинами
- Сколько клеток занимает карабас
- Что такое const в js
Noise reduction in python using spectral gating
Noisereduce is a noise reduction algorithm in python that reduces noise in time-domain signals like speech, bioacoustics, and physiological signals. It relies on a method called "spectral gating" which is a form of Noise Gate. It works by computing a spectrogram of a signal (and optionally a noise signal) and estimating a noise threshold (or gate) for each frequency band of that signal/noise. That threshold is used to compute a mask, which gates noise below the frequency-varying threshold.
The most recent version of noisereduce comprises two algorithms:
- Stationary Noise Reduction: Keeps the estimated noise threshold at the same level across the whole signal
- Non-stationary Noise Reduction: Continuously updates the estimated noise threshold over time
Version 3 Updates:
- Includes a PyTorch-based implementation of Spectral Gating, an algorithm for denoising audio signals.
- You can now create a noisereduce nn.Module object which allows it to be used either as a standalone module or as part of a larger neural network architecture.
- The run time of the algorithm decreases substantially.
Version 2 Updates:
- Added two forms of spectral gating noise reduction: stationary noise reduction, and non-stationary noise reduction.
- Added multiprocessing so you can perform noise reduction on bigger data.
- The new version breaks the API of the old version.
- The previous version is still available at from noisereduce.noisereducev1 import reduce_noise
- You can now create a noisereduce object which allows you to reduce noise on subsets of longer recordings
Stationary Noise Reduction
- The basic intuition is that statistics are calculated on each frequency channel to determine a noise gate. Then the gate is applied to the signal.
- This algorithm is based (but not completely reproducing) on the one outlined by Audacity for the noise reduction effect (Link to C++ code)
- The algorithm takes two inputs:
- A noise clip containing prototypical noise of clip (optional)
- A signal clip containing the signal and the noise intended to be removed
Steps of the Stationary Noise Reduction algorithm
- A spectrogram is calculated over the noise audio clip
- Statistics are calculated over spectrogram of the the noise (in frequency)
- A threshold is calculated based upon the statistics of the noise (and the desired sensitivity of the algorithm)
- A spectrogram is calculated over the signal
- A mask is determined by comparing the signal spectrogram to the threshold
- The mask is smoothed with a filter over frequency and time
- The mask is appled to the spectrogram of the signal, and is inverted If the noise signal is not provided, the algorithm will treat the signal as the noise clip, which tends to work pretty well
Non-stationary Noise Reduction
- The non-stationary noise reduction algorithm is an extension of the stationary noise reduction algorithm, but allowing the noise gate to change over time.
- When you know the timescale that your signal occurs on (e.g. a bird call can be a few hundred milliseconds), you can set your noise threshold based on the assumption that events occuring on longer timescales are noise.
- This algorithm was motivated by a recent method in bioacoustics called Per-Channel Energy Normalization.
Steps of the Non-stationary Noise Reduction algorithm
- A spectrogram is calculated over the signal
- A time-smoothed version of the spectrogram is computed using an IIR filter aplied forward and backward on each frequency channel.
- A mask is computed based on that time-smoothed spectrogram
- The mask is smoothed with a filter over frequency and time
- The mask is appled to the spectrogram of the signal, and is inverted
Installation
pip install noisereduce
Usage
See example notebook: Parallel computing example:
reduce_noise
Simplest usage
from scipy.io import wavfile import noisereduce as nr # load data rate, data = wavfile.read("mywav.wav") # perform noise reduction reduced_noise = nr.reduce_noise(y=data, sr=rate) wavfile.write("mywav_reduced_noise.wav", rate, reduced_noise) Arguments to reduce_noise
y : np.ndarray [shape=(# frames,) or (# channels, # frames)], real-valued input signal sr : int sample rate of input signal / noise signal y_noise : np.ndarray [shape=(# frames,) or (# channels, # frames)], real-valued noise signal to compute statistics over (only for non-stationary noise reduction). stationary : bool, optional Whether to perform stationary, or non-stationary noise reduction, by default False prop_decrease : float, optional The proportion to reduce the noise by (1.0 = 100%), by default 1.0 time_constant_s : float, optional The time constant, in seconds, to compute the noise floor in the non-stationary algorithm, by default 2.0 freq_mask_smooth_hz : int, optional The frequency range to smooth the mask over in Hz, by default 500 time_mask_smooth_ms : int, optional The time range to smooth the mask over in milliseconds, by default 50 thresh_n_mult_nonstationary : int, optional Only used in nonstationary noise reduction., by default 1 sigmoid_slope_nonstationary : int, optional Only used in nonstationary noise reduction., by default 10 n_std_thresh_stationary : int, optional Number of standard deviations above mean to place the threshold between signal and noise., by default 1.5 tmp_folder : [type], optional Temp folder to write waveform to during parallel processing. Defaults to default temp folder for python., by default None chunk_size : int, optional Size of signal chunks to reduce noise over. Larger sizes will take more space in memory, smaller sizes can take longer to compute. , by default 60000 padding : int, optional How much to pad each chunk of signal by. Larger pads are needed for larger time constants., by default 30000 n_fft : int, optional length of the windowed signal after padding with zeros. The number of rows in the STFT matrix ``D`` is ``(1 + n_fft/2)``. The default value, ``n_fft=2048`` samples, corresponds to a physical duration of 93 milliseconds at a sample rate of 22050 Hz, i.e. the default sample rate in librosa. This value is well adapted for music signals. However, in speech processing, the recommended value is 512, corresponding to 23 milliseconds at a sample rate of 22050 Hz. In any case, we recommend setting ``n_fft`` to a power of two for optimizing the speed of the fast Fourier transform (FFT) algorithm., by default 1024 win_length : [type], optional Each frame of audio is windowed by ``window`` of length ``win_length`` and then padded with zeros to match ``n_fft``. Smaller values improve the temporal resolution of the STFT (i.e. the ability to discriminate impulses that are closely spaced in time) at the expense of frequency resolution (i.e. the ability to discriminate pure tones that are closely spaced in frequency). This effect is known as the time-frequency localization trade-off and needs to be adjusted according to the properties of the input signal ``y``. If unspecified, defaults to ``win_length = n_fft``., by default None hop_length : [type], optional number of audio samples between adjacent STFT columns. Smaller values increase the number of columns in ``D`` without affecting the frequency resolution of the STFT. If unspecified, defaults to ``win_length // 4`` (see below)., by default None n_jobs : int, optional Number of parallel jobs to run. Set at -1 to use all CPU cores, by default 1 torch_flag: bool, optional Whether to use the torch version of spectral gating, by default False device: str, optional A device to run the torch spectral gating on, by default "cuda" Torch
See example notebook:
Simplest usage
import torch from noisereduce.torchgate import TorchGate as TG device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu") # Create TorchGating instance tg = TG(sr=8000, nonstationary=True).to(device) # Apply Spectral Gate to noisy speech signal noisy_speech = torch.randn(3, 32000, device=device) enhanced_speech = tg(noisy_speech) Arguments
| Parameter | Description |
|---|---|
| sr | Sample rate of the input signal. |
| n_fft | The size of the FFT. |
| hop_length | The number of samples between adjacent STFT columns. |
| win_length | The window size for the STFT. If None, defaults to n_fft. |
| freq_mask_smooth_hz | The frequency smoothing width in Hz for the masking filter. If None, no frequency masking is applied. |
| time_mask_smooth_ms | The time smoothing width in milliseconds for the masking filter. If None, no time masking is applied. |
| n_std_thresh_stationary | The number of standard deviations above the noise mean to consider as signal for stationary noise. |
| nonstationary | Whether to use non-stationary noise masking. |
| n_movemean_nonstationary | The number of frames to use for the moving average in the non-stationary noise mask. |
| n_thresh_nonstationary | The multiplier to apply to the sigmoid function in the non-stationary noise mask. |
| temp_coeff_nonstationary | The temperature coefficient to apply to the sigmoid function in the non-stationary noise mask. |
| prop_decrease | The proportion of decrease to apply to the mask. |
Choosing between Stationary and non-stantionary noise reduction
I discuss stationary and non-stationary noise reduction in this paper.
Figure caption: Stationary and non-stationary spectral gating noise reduction. (A) An overview of each algorithm. Stationary noise reduction typically takes in an explicit noise signal to calculate statistics and performs noise reduction over the entire signal uniformly. Non-stationary noise reduction dynamically estimates and reduces noise concurrently. (B) Stationary and non-stationary spectral gating noise reduction using the noisereduce Python package (Sainburg, 2019) applied to a Common chiffchaff (Phylloscopus collybita) song (Stowell et al., 2019) with an airplane noise in the background. The bottom frame depicts the difference between the two algorithms.
Citation
If you use this code in your research, please cite it:
@article, author=, journal=, volume=, number=, pages=, year=, publisher= > @software, title = , month = jun, year = 2019, publisher = , version = , doi = , url = >
Project based on the cookiecutter data science project template. #cookiecutterdatascience