Равномерное дискретное распределение в EXCEL
Рассмотрим Равномерное дискретное распределение, построим график функции распределения, вычислим среднее значение и дисперсию. Сгенерируем случайные значения (выборку) с помощью функции MS EXCEL СЛУЧМЕЖДУ() . На основании выборки оценим среднее и стандартное отклонение распределения.
Равномерное дискретное распределение (англ. Discrete uniform distribution) имеет место, например, при подбрасывании симметричной монеты. Пусть если выпал «орёл», то случайная величина принимает значение 1, если выпала «решка» — то 0. Т.к. вероятность наступления событий одинакова и всего 2 возможных исхода, то вероятность случайной величины принять значение 1 (или 0) равна 1/2=0,5.
Распределение называется равномерным, т.к. вероятность любого исхода одинакова.
Примечание : В данном случае, когда возможно всего 2 исхода, равномерное распределение является частным случаем Распределения Бернулли с параметром p = q =1- p =0,5.
Другой пример. Результат бросания симметричной игральной кости является равномерной дискретной случайной величиной , т.к. количество точек на грани кубика принимает одно из 6 равновероятных значений. Вероятность выпадения каждой из шести граней равна 1/6.
Для этого примера функция распределения будет выглядеть следующим образом.
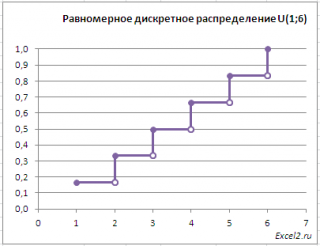
Примечание : Для построения графика использованы идеи из статьи про ступенчатый график .
СОВЕТ : Подробнее о Функции распределения см. статью Функция распределения и плотность вероятности в MS EXCEL .
Математическое ожидание и дисперсия
В файле примера на листе График приведен расчет математического ожидания по формуле =(a+b)/2.
Дисперсия (квадрат стандартного отклонения) для равномерного дискретного распределения может быть вычислена по формуле =((b-a+1)^2-1)/12.
Генерация случайных значений
Случайные числа, имеющие равномерное дискретное распределение , можно сгенерировать с помощью функции MS EXCEL СЛУЧМЕЖДУ() . В функции можно задать нижнюю и верхнюю границу интервала [a; b]. Функцией будут сгенерированы целые случайные числа из указанного интервала (см. файл примера лист Генерация ).
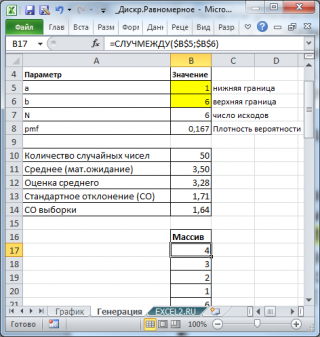
Обратите внимание, что массив случайных чисел, сгенерированных с помощью функции СЛУЧМЕЖДУ() , автоматически обновится при пересчете листа. Пересчет листа в MS EXCEL производится при вводе нового значения в ячейку или при нажатии клавиши F9 .
Примечание : Подробнее про функцию СЛУЧМЕЖДУ() см. статью Функция СЛУЧМЕЖДУ() — Случайное число из заданного интервала в MS EXCEL .
Чтобы сгенерировать нецелые случайные числа, например из интервала [1,1; 2,5], необходимо записать формулу = СЛУЧМЕЖДУ(1,1*10;2,5*10)/10 .
Множитель 10 отражает тот факт, что нецелые случайные числа будут сгенерированы с точностью до десятых. Если интервал задан с точностью до сотых, то нужно использовать множитель 100.
Как видно из формулы — границы интервала также могут быть нецелыми числами. Хотя, конечно, можно сгенерировать числа, например, с точностью до сотых с помощью формулы = СЛУЧМЕЖДУ(10*100;20*100)/100 . В этом случае случайные числа будут принадлежать интервалу [10;20] и иметь вид 10,37; 16,08; 15,43 и т.д.
Оценка среднего и стандартного отклонения
Сгенерируем 50 чисел (выборку) и разместим их в диапазоне B17:B66 . Нижнюю и верхнюю границу интервала возьмем [1; 6] и разместим их в диапазоне B5:B6 .
Математическое ожидание этого распределения =(B5+B6)/2 и равно (6+1)/2=3,5. Стандартное отклонение распределения равно = КОРЕНЬ(((B6-B5+1)^2-1)/12) =1,71
Чтобы оценить математическое ожидание воспользуемся значениями выборки =СУММ(B17:B66)/СЧЁТ(B17:B66) .
Оценить стандартное отклонение можно с помощью формулы =СТАНДОТКЛОН.В(B17:B66) в MS EXCEL 2010 или = СТАНДОТКЛОН(B17:B66) для более ранних версий.
Чтобы оценить дисперсию используйте формулу =ДИСП.В(B17:B66) в MS EXCEL 2010 или =ДИСП(B17:B66) для более ранних версий. Также можно использовать формулу =СТАНДОТКЛОН.В(B17:B66)^2 .
СОВЕТ : О других распределениях MS EXCEL можно прочитать в статье Распределения случайной величины в MS EXCEL .
Нормальное распределение. Непрерывные распределения в EXCEL
Рассмотрим Нормальное распределение. С помощью функции MS EXCEL НОРМ.РАСП() построим графики функции распределения и плотности вероятности. Сгенерируем массив случайных чисел, распределенных по нормальному закону, произведем оценку параметров распределения, среднего значения и стандартного отклонения .
Нормальное распределение (также называется распределением Гаусса) является самым важным как в теории, так в приложениях системы контроля качества. Важность значения Нормального распределения (англ. Normal distribution ) во многих областях науки вытекает из Центральной предельной теоремы теории вероятностей.
Определение : Случайная величина x распределена по нормальному закону , если она имеет плотность распределения :
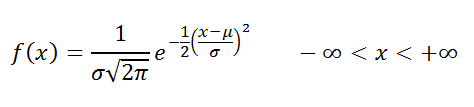
СОВЕТ : Подробнее о Функции распределения и Плотности вероятности см. статью Функция распределения и плотность вероятности в MS EXCEL .
Нормальное распределение зависит от двух параметров: μ (мю) — является математическим ожиданием (средним значением случайной величины) , и σ ( сигма) — является стандартным отклонением (среднеквадратичным отклонением). Параметр μ определяет положение центра плотности вероятности нормального распределения , а σ — разброс относительно центра (среднего).
Примечание : О влиянии параметров μ и σ на форму распределения изложено в статье про Гауссову кривую , а в файле примера на листе Влияние параметров можно с помощью элементов управления Счетчик понаблюдать за изменением формы кривой.
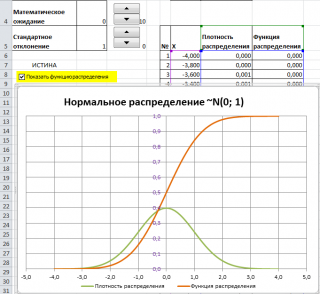
Нормальное распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для Нормального распределения имеется функция НОРМ.РАСП() , английское название — NORM.DIST(), которая позволяет вычислить плотность вероятности (см. формулу выше) и интегральную функцию распределения (вероятность, что случайная величина X, распределенная по нормальному закону , примет значение меньше или равное x). Вычисления в последнем случае производятся по следующей формуле:
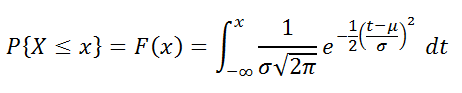
Вышеуказанное распределение имеет обозначение N (μ; σ). Так же часто используют обозначение через дисперсию N (μ; σ 2 ).
Примечание : До MS EXCEL 2010 в EXCEL была только функция НОРМРАСП() , которая также позволяет вычислить функцию распределения и плотность вероятности. НОРМРАСП() оставлена в MS EXCEL 2010 для совместимости.
Стандартное нормальное распределение
Стандартным нормальным распределением называется нормальное распределение с математическим ожиданием μ=0 и дисперсией σ=1. Вышеуказанное распределение имеет обозначение N (0;1).
Примечание : В литературе для случайной величины, распределенной по стандартному нормальному закону, закреплено специальное обозначение z.
Любое нормальное распределение можно преобразовать в стандартное через замену переменной z =( x -μ)/σ . Этот процесс преобразования называется стандартизацией .
Примечание : В MS EXCEL имеется функция НОРМАЛИЗАЦИЯ() , которая выполняет вышеуказанное преобразование. Хотя в MS EXCEL это преобразование называется почему-то нормализацией . Формулы =(x-μ)/σ и =НОРМАЛИЗАЦИЯ(х;μ;σ) вернут одинаковый результат.
В MS EXCEL 2010 для стандартного нормального распределения имеется специальная функция НОРМ.СТ.РАСП() и ее устаревший вариант НОРМСТРАСП() , выполняющий аналогичные вычисления.
Продемонстрируем, как в MS EXCEL осуществляется процесс стандартизации нормального распределения N (1,5; 2).
Для этого вычислим вероятность, что случайная величина, распределенная по нормальному закону N(1,5; 2) , меньше или равна 2,5. Формула выглядит так: =НОРМ.РАСП(2,5; 1,5; 2; ИСТИНА) =0,691462. Сделав замену переменной z =(2,5-1,5)/2=0,5 , запишем формулу для вычисления Стандартного нормального распределения: =НОРМ.СТ.РАСП(0,5; ИСТИНА) =0,691462.
Естественно, обе формулы дают одинаковые результаты (см. файл примера лист Пример ).
Обратите внимание, что стандартизация относится только к интегральной функции распределения (аргумент интегральная равен ИСТИНА), а не к плотности вероятности .
Примечание : В литературе для функции, вычисляющей вероятности случайной величины, распределенной по стандартному нормальному закону, закреплено специальное обозначение Ф(z). В MS EXCEL эта функция вычисляется по формуле =НОРМ.СТ.РАСП(z;ИСТИНА) . Вычисления производятся по формуле
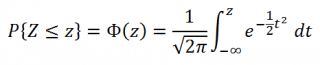
В силу четности функции плотности стандартного нормального распределения f(x), а именно f(x)=f(-х), функция стандартного нормального распределения обладает свойством Ф(-x)=1-Ф(x).
Обратные функции
Функция НОРМ.СТ.РАСП(x;ИСТИНА) вычисляет вероятность P, что случайная величина Х примет значение меньше или равное х. Но часто требуется провести обратное вычисление: зная вероятность P, требуется вычислить значение х. Вычисленное значение х называется квантилем стандартного нормального распределения .
В MS EXCEL для вычисления квантилей используют функцию НОРМ.СТ.ОБР() и НОРМ.ОБР() .
Графики функций
В файле примера приведены графики плотности распределения вероятности и интегральной функции распределения .
Как известно, около 68% значений, выбранных из совокупности, имеющей нормальное распределение , находятся в пределах 1 стандартного отклонения (σ) от μ(среднего или математического ожидания); около 95% — в пределах 2-х σ, а в пределах 3-х σ находятся уже 99% значений. Убедиться в этом для стандартного нормального распределения можно записав формулу:
которая вернет значение 68,2689% — именно такой процент значений находятся в пределах +/-1 стандартного отклонения от среднего (см. лист График в файле примера ).
В силу четности функции плотности стандартного нормального распределения: f ( x )= f (-х) , функция стандартного нормального распределения обладает свойством F(-x)=1-F(x). Поэтому, вышеуказанную формулу можно упростить:
Для произвольной функции нормального распределения N(μ; σ) аналогичные вычисления нужно производить по формуле:
Вышеуказанные расчеты вероятности требуются для построения доверительных интервалов .
Примечание : Для построения функции распределения и плотности вероятности можно использовать диаграмму типа График или Точечная (со сглаженными линиями и без точек). Подробнее о построении диаграмм читайте статью Основные типы диаграмм .
Примечание : Для удобства написания формул в файле примера созданы Имена для параметров распределения: μ и σ.
Генерация случайных чисел
С помощью надстройки Пакет анализа можно сгенерировать случайные числа, распределенные по нормальному закону .
СОВЕТ : О надстройке Пакет анализа можно прочитать в статье Надстройка Пакет анализа MS EXCEL .
Сгенерируем 3 массива по 100 чисел с различными μ и σ. Для этого в окне Генерация случайных чисел установим следующие значения для каждой пары параметров:
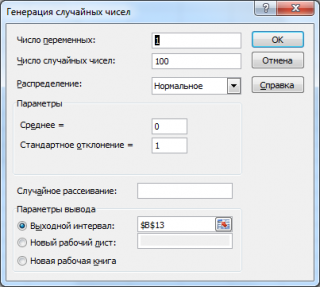
Примечание : Если установить опцию Случайное рассеивание ( Random Seed ), то можно выбрать определенный случайный набор сгенерированных чисел. Например, установив эту опцию равной 25, можно сгенерировать на разных компьютерах одни и те же наборы случайных чисел (если, конечно, другие параметры распределения совпадают). Значение опции может принимать целые значения от 1 до 32 767. Название опции Случайное рассеивание может запутать. Лучше было бы ее перевести как Номер набора со случайными числами .
В итоге будем иметь 3 столбца чисел, на основании которых можно, оценить параметры распределения, из которого была произведена выборка: μ и σ . Оценку для μ можно сделать с использованием функции СРЗНАЧ() , а для σ – с использованием функции СТАНДОТКЛОН.В() , см. файл примера лист Генерация .
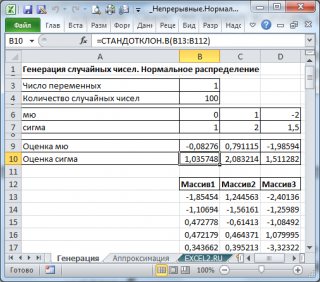
Примечание : Для генерирования массива чисел, распределенных по нормальному закону , можно использовать формулу =НОРМ.ОБР(СЛЧИС();μ;σ) . Функция СЛЧИС() генерирует непрерывное равномерное распределение от 0 до 1, что как раз соответствует диапазону изменения вероятности (см. файл примера лист Генерация ).
Задачи
Задача1 . Компания изготавливает нейлоновые нити со средней прочностью 41 МПа и стандартным отклонением 2 МПа. Потребитель хочет приобрести нити с прочностью не менее 36 МПа. Рассчитайте вероятность, что партии нити, изготовленные компанией для потребителя, будут соответствовать требованиям или превышать их. Решение1 : = 1-НОРМ.РАСП(36;41;2;ИСТИНА)
Задача2 . Предприятие изготавливает трубы, средний внешний диаметр которых равен 20,20 мм, а стандартное отклонение равно 0,25мм. Согласно техническим условиям, трубы признаются годными, если диаметр находится в пределах 20,00+/- 0,40 мм. Какая доля изготовленных труб соответствует ТУ? Решение2 : = НОРМ.РАСП(20,00+0,40;20,20;0,25;ИСТИНА)- НОРМ.РАСП(20,00-0,40;20,20;0,25) На рисунке ниже, выделена область значений диаметров, которая удовлетворяет требованиям спецификации.
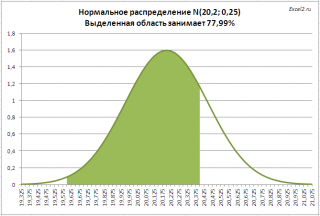
Решение приведено в файле примера лист Задачи .
Задача3 . Предприятие изготавливает трубы, средний внешний диаметр которых равен 20,20 мм, а стандартное отклонение равно 0,25мм. Внешний диаметр не должен превышать определенное значение (предполагается, что нижняя граница не важна). Какую верхнюю границу в технических условиях необходимо установить, чтобы ей соответствовало 97,5% всех изготавливаемых изделий? Решение3 : = НОРМ.ОБР(0,975; 20,20; 0,25) =20,6899 или = НОРМ.СТ.ОБР(0,975)*0,25+20,2 (произведена «дестандартизация», см. выше)
Задача 4 . Нахождение параметров нормального распределения по значениям 2-х квантилей (или процентилей ). Предположим, известно, что случайная величина имеет нормальное распределение, но не известны его параметры, а только 2-я процентиля (например, 0,5- процентиль , т.е. медиана и 0,95-я процентиль ). Т.к. известна медиана , то мы знаем среднее , т.е. μ. Чтобы найти стандартное отклонение нужно использовать Поиск решения . Решение приведено в файле примера лист Задачи .
Примечание : До MS EXCEL 2010 в EXCEL были функции НОРМОБР() и НОРМСТОБР() , которые эквивалентны НОРМ.ОБР() и НОРМ.СТ.ОБР() . НОРМОБР() и НОРМСТОБР() оставлены в MS EXCEL 2010 и выше только для совместимости.
Линейные комбинации нормально распределенных случайных величин
Известно, что линейная комбинация нормально распределённых случайных величин x ( i ) с параметрами μ ( i ) и σ ( i ) также распределена нормально. Например, если случайная величина Y=x(1)+x(2), то Y будет иметь распределение с параметрами μ (1)+ μ(2) и КОРЕНЬ(σ(1)^2+ σ(2)^2). Убедимся в этом с помощью MS EXCEL.
С помощью надстройки Пакет анализа сгенерируем 2 массива по 100 чисел с различными μ и σ.
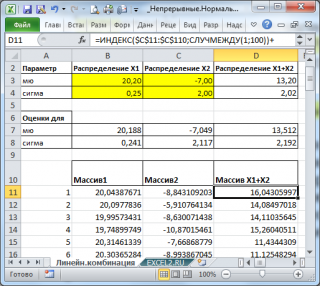
Теперь сформируем массив, каждый элемент которого является суммой 2-х значений, взятых из каждого массива.
С помощью функций СРЗНАЧ() и СТАНДОТКЛОН.В() вычислим среднее и дисперсию получившейся выборки и сравним их с расчетными.
Кроме того, построим График проверки распределения на нормальность ( Normal Probability Plot ), чтобы убедиться, что наш массив соответствует выборке из нормального распределения .
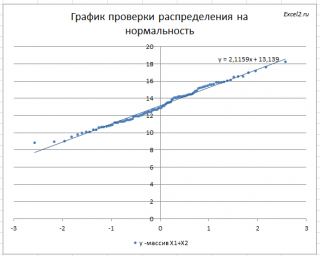
Прямая линия, аппроксимирующая полученный график, имеет уравнение y=ax+b. Наклон кривой (параметр а) может служить оценкой стандартного отклонения , а пересечение с осью y (параметр b) – среднего значения.
Для сравнения сгенерируем массив напрямую из распределения N (μ(1)+ μ(2); КОРЕНЬ(σ(1)^2+ σ(2)^2) ).
Как видно на рисунке ниже, обе аппроксимирующие кривые достаточно близки.
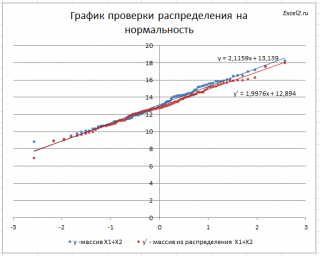
В качестве примера можно провести следующую задачу.
Задача . Завод изготавливает болты и гайки, которые упаковываются в ящики парами. Пусть известно, что вес каждого из изделий является нормальной случайной величиной. Для болтов средний вес составляет 50г, стандартное отклонение 1,5г, а для гаек 20г и 1,2г. В ящик фасуется 100 пар болтов и гаек. Вычислить какой процент ящиков будет тяжелее 7,2 кг. Решение . Сначала переформулируем вопрос задачи: Вычислить какой процент пар болт-гайка будет тяжелее 7,2кг/100=72г. Учитывая, что вес пары представляет собой случайную величину = Вес(болта) + Вес(гайки) со средним весом (50+20)г, и стандартным отклонением =КОРЕНЬ(СУММКВ(1,5;1,2)) , запишем решение = 1-НОРМ.РАСП(72; 50+20; КОРЕНЬ(СУММКВ(1,5;1,2));ИСТИНА) Ответ : 15% (см. файл примера лист Линейн.комбинация )
Аппроксимация Биномиального распределения Нормальным распределением
Если параметры Биномиального распределения B(n;p) находятся в пределах 0,1 10, то Биномиальное распределение можно аппроксимировать Нормальным распределением .
При значениях λ >15 , Распределение Пуассона хорошо аппроксимируется Нормальным распределением с параметрами: μ =λ , σ 2 = λ .
Подробнее о связи этих распределений, можно прочитать в статье Взаимосвязь некоторых распределений друг с другом в MS EXCEL . Там же приведены примеры аппроксимации, и пояснены условия, когда она возможна и с какой точностью.
СОВЕТ : О других распределениях MS EXCEL можно прочитать в статье Распределения случайной величины в MS EXCEL .
Гистограмма распределения в EXCEL
Гистограмма распределения — это инструмент, позволяющий визуально оценить величину и характер разброса данных. Создадим гистограмму для непрерывной случайной величины с помощью встроенных средств MS EXCEL из надстройки Пакет анализа и в ручную с помощью функции ЧАСТОТА() и диаграммы.
Гистограмма (frequency histogram) – это столбиковая диаграмма MS EXCEL , в каждый столбик представляет собой интервал значений (корзину, карман, class interval, bin, cell), а его высота пропорциональна количеству значений в ней (частоте наблюдений).
Гистограмма поможет визуально оценить распределение набора данных, если:
- в наборе данных как минимум 50 значений;
- ширина интервалов одинакова.
Построим гистограмму для набора данных, в котором содержатся значения непрерывной случайной величины . Набор данных (50 значений), а также рассмотренные примеры, можно взять на листе Гистограмма AT в файле примера. Данные содержатся в диапазоне А8:А57 .
Примечание : Для удобства написания формул для диапазона А8:А57 создан Именованный диапазон Исходные_данные.
Построение гистограммы с помощью надстройки Пакет анализа
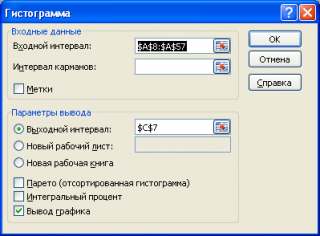
Вызвав диалоговое окно надстройки Пакет анализа , выберите пункт Гистограмма и нажмите ОК.
В появившемся окне необходимо как минимум указать: входной интервал и левую верхнюю ячейку выходного интервала . После нажатия кнопки ОК будут:
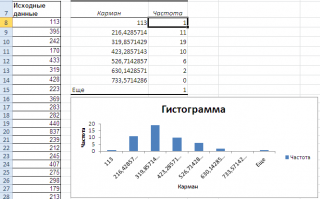
- автоматически рассчитаны интервалы значений (карманы);
- подсчитано количество значений из указанного массива данных, попадающих в каждый интервал (построена таблица частот);
- если поставлена галочка напротив пункта Вывод графика , то вместе с таблицей частот будет выведена гистограмма.
 Перед тем как анализировать полученный результат — отсортируйте исходный массив данных .
Перед тем как анализировать полученный результат — отсортируйте исходный массив данных . 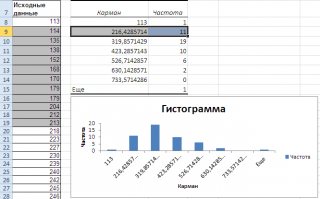
Как видно из рисунка, первый интервал включает только одно минимальное значение 113 (точнее, включены все значения меньшие или равные минимальному). Если бы в массиве было 2 или более значения 113, то в первый интервал попало бы соответствующее количество чисел (2 или более).
Второй интервал (отмечен на картинке серым) включает значения больше 113 и меньше или равные 216,428571428571. Можно проверить, что таких значений 11. Предпоследний интервал, от 630,142857142857 (не включая) до 733,571428571429 (включая) содержит 0 значений, т.к. в этом диапазоне значений нет. Последний интервал (со странным названием Еще ) содержит значения больше 733,571428571429 (не включая). Таких значений всего одно — максимальное значение в массиве (837).
Размеры карманов одинаковы и равны 103,428571428571. Это значение можно получить так: =(МАКС( Исходные_данные )-МИН( Исходные_данные ))/7 где Исходные_данные – именованный диапазон , содержащий наши данные.
Почему 7? Дело в том, что количество интервалов гистограммы (карманов) зависит от количества данных и для его определения часто используется формула √n, где n – это количество данных в выборке. В нашем случае √n=√50=7,07 (всего 7 полноценных карманов, т.к. первый карман включает только значения равные минимальному).
Примечание : Похоже, что инструмент Гистограмма для подсчета общего количества интервалов (с учетом первого) использует формулу =ЦЕЛОЕ(КОРЕНЬ(СЧЕТ( Исходные_данные )))+1
Попробуйте, например, сравнить количество интервалов для диапазонов длиной 35 и 36 значений – оно будет отличаться на 1, а у 36 и 48 – будет одинаковым, т.к. функция ЦЕЛОЕ() округляет до ближайшего меньшего целого (ЦЕЛОЕ(КОРЕНЬ(35))=5 , а ЦЕЛОЕ(КОРЕНЬ(36))=6) .
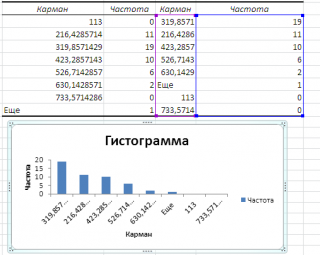
Если установить галочку напротив поля Парето (отсортированная гистограмма) , то к таблице с частотами будет добавлена таблица с отсортированными по убыванию частотами.
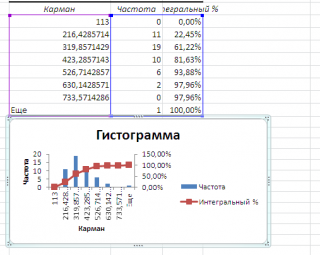
Если установить галочку напротив поля Интегральный процент , то к таблице с частотами будет добавлен столбец с нарастающим итогом в % от общего количества значений в массиве.
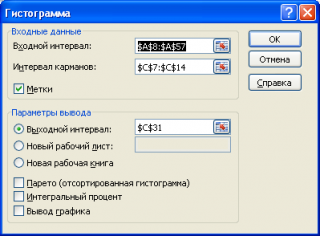
Если выбор количества интервалов или их диапазонов не устраивает, то можно в диалоговом окне указать нужный массив интервалов (если интервал карманов включает текстовый заголовок, то нужно установить галочку напротив поля Метка ).
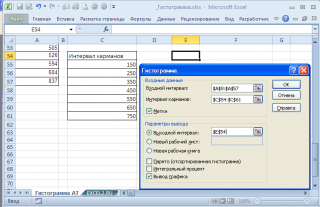
Для нашего набора данных установим размер кармана равным 100 и первый карман возьмем равным 150.
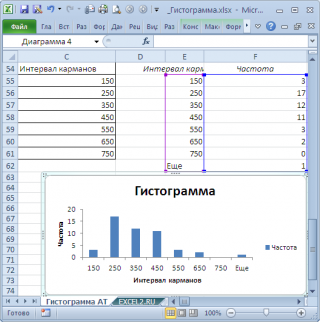
В результате получим практически такую же по форме гистограмму , что и раньше, но с более красивыми границами интервалов.
Как видно из рисунков выше, надстройка Пакет анализа не осуществляет никакого дополнительного форматирования диаграммы . Соответственно, вид такой гистограммы оставляет желать лучшего (столбцы диаграммы обычно располагают вплотную для непрерывных величин, кроме того подписи интервалов не информативны). О том, как придать диаграмме более презентабельный вид, покажем в следующем разделе при построении гистограммы с помощью функции ЧАСТОТА() без использовании надстройки Пакет анализа .
Построение гистограммы распределения без использования надстройки Пакет анализа
Порядок действий при построении гистограммы в этом случае следующий:
- определить количество интервалов у гистограммы;
- определить ширину интервала (с учетом округления);
- определить границу первого интервала;
- сформировать таблицу интервалов и рассчитать количество значений, попадающих в каждый интервал (частоту);
- построить гистограмму.
СОВЕТ : Часто рекомендуют, чтобы границы интервала были на один порядок точнее самих данных и оканчивались на 5. Например, если данные в массиве определены с точностью до десятых: 1,2; 2,3; 5,0; 6,1; 2,1, …, то границы интервалов должны быть округлены до сотых: 1,25-1,35; 1,35-1,45; … Для небольших наборов данных вид гистограммы сильно зависит количества интервалов и их ширины. Это приводит к тому, что сам метод гистограмм, как инструмент описательной статистики , может быть применен только для наборов данных состоящих, как минимум, из 50, а лучше из 100 значений.
В наших расчетах для определения количества интервалов мы будем пользоваться формулой =ЦЕЛОЕ(КОРЕНЬ(n))+1 .
Примечание : Кроме использованного выше правила (число карманов = √n), используется ряд других эмпирических правил, например, правило Стёрджеса (Sturges): число карманов =1+log2(n). Это обусловлено тем, что например, для n=5000, количество интервалов по формуле √n будет равно 70, а правило Стёрджеса рекомендует более приемлемое количество — 13.
Расчет ширины интервала и таблица интервалов приведены в файле примера на листе Гистограмма . Для вычисления количества значений, попадающих в каждый интервал, использована формула массива на основе функции ЧАСТОТА() . О вводе этой функции см. статью Функция ЧАСТОТА() — Подсчет ЧИСЛОвых значений в MS EXCEL .
В MS EXCEL имеется диаграмма типа Гистограмма с группировкой , которая обычно используется для построения Гистограмм распределения .
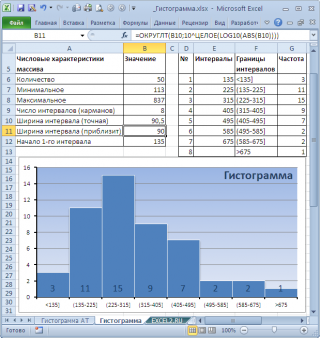
В итоге можно добиться вот такого результата.
Примечание : О построении и настройке макета диаграмм см. статью Основы построения диаграмм в MS EXCEL .
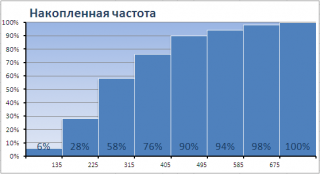
Одной из разновидностей гистограмм является график накопленной частоты (cumulative frequency plot).
На этом графике каждый столбец представляет собой число значений исходного массива, меньших или равных правой границе соответствующего интервала. Это очень удобно, т.к., например, из графика сразу видно, что 90% значений (45 из 50) меньше чем 495.
СОВЕТ : О построении двумерной гистограммы см. статью Двумерная гистограмма в MS EXCEL .
Примечание : Альтернативой графику накопленной частоты может служить Кривая процентилей , которая рассмотрена в статье про Процентили .
Примечание : Когда количество значений в выборке недостаточно для построения полноценной гистограммы может быть полезна Блочная диаграмма (иногда она называется Диаграмма размаха или Ящик с усами ).
Как создать частотное распределение в Excel
Распределение частоты описывает, как часто разные значения встречаются в наборе данных. Это полезный способ понять, как значения данных распределяются в наборе данных.
К счастью, легко создать и визуализировать частотное распределение в Excel, используя следующую функцию:
=ЧАСТОТА(массив_данных,массив_бинов)
- data_array : массив необработанных значений данных
- bins_array: массив верхних пределов для бинов
В следующем примере показано, как использовать эту функцию на практике.
Пример: частотное распределение в Excel
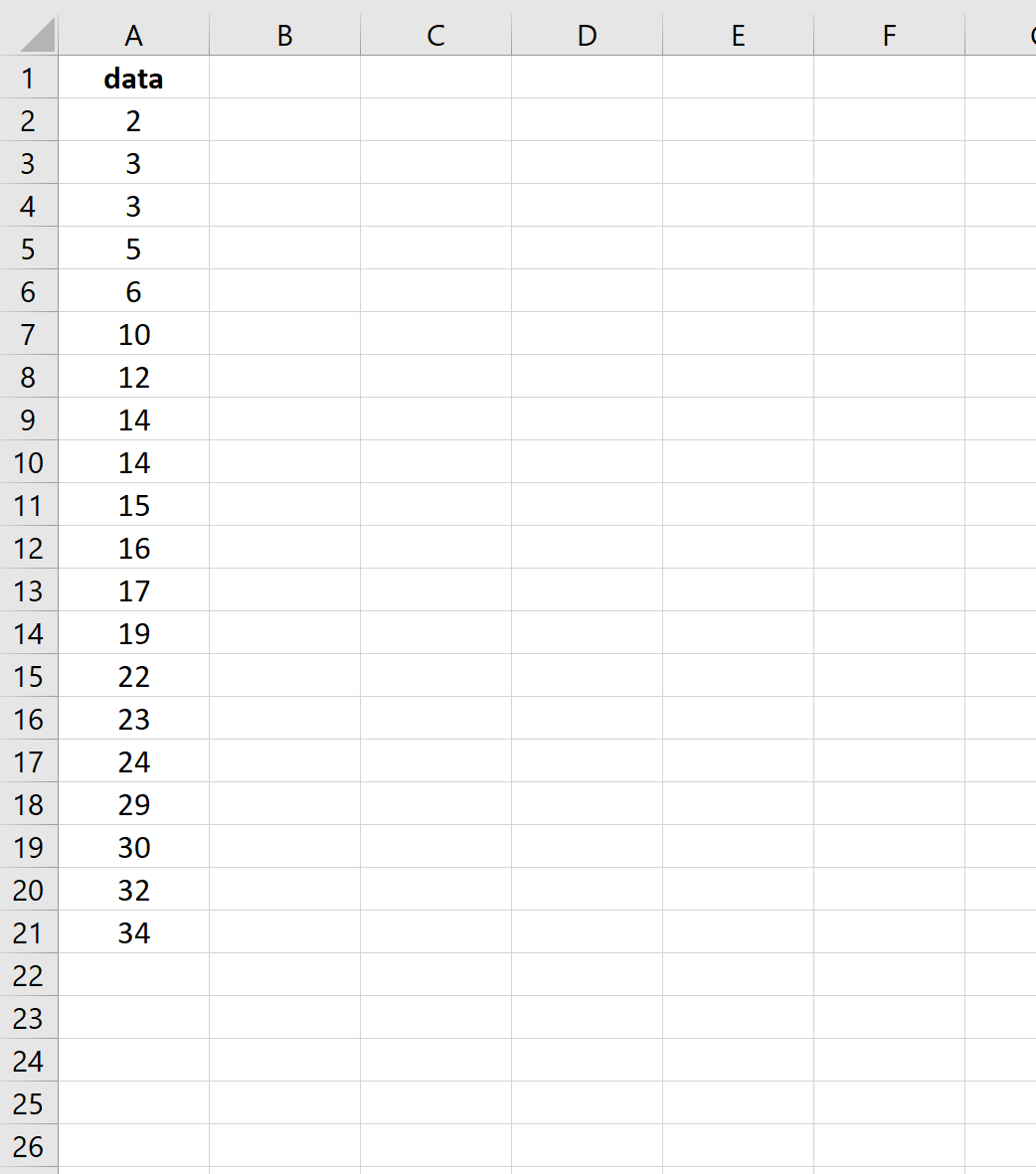
Предположим, у нас есть следующий набор данных из 20 значений в Excel:
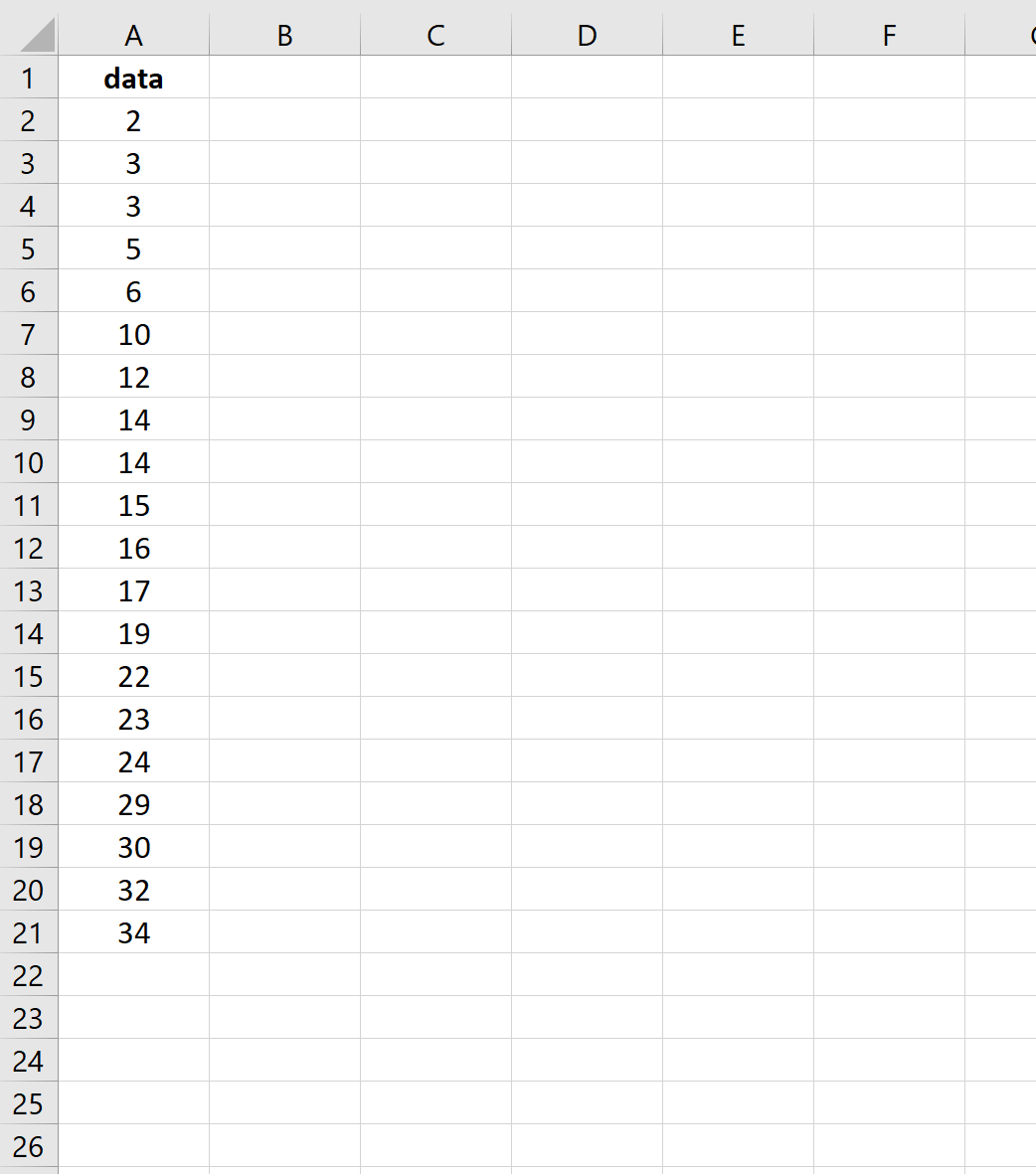
Во-первых, мы укажем Excel, какие верхние пределы мы хотели бы использовать для интервалов нашего частотного распределения. Для этого примера мы выберем 10, 20 и 30. То есть мы найдем частоты для следующих интервалов:
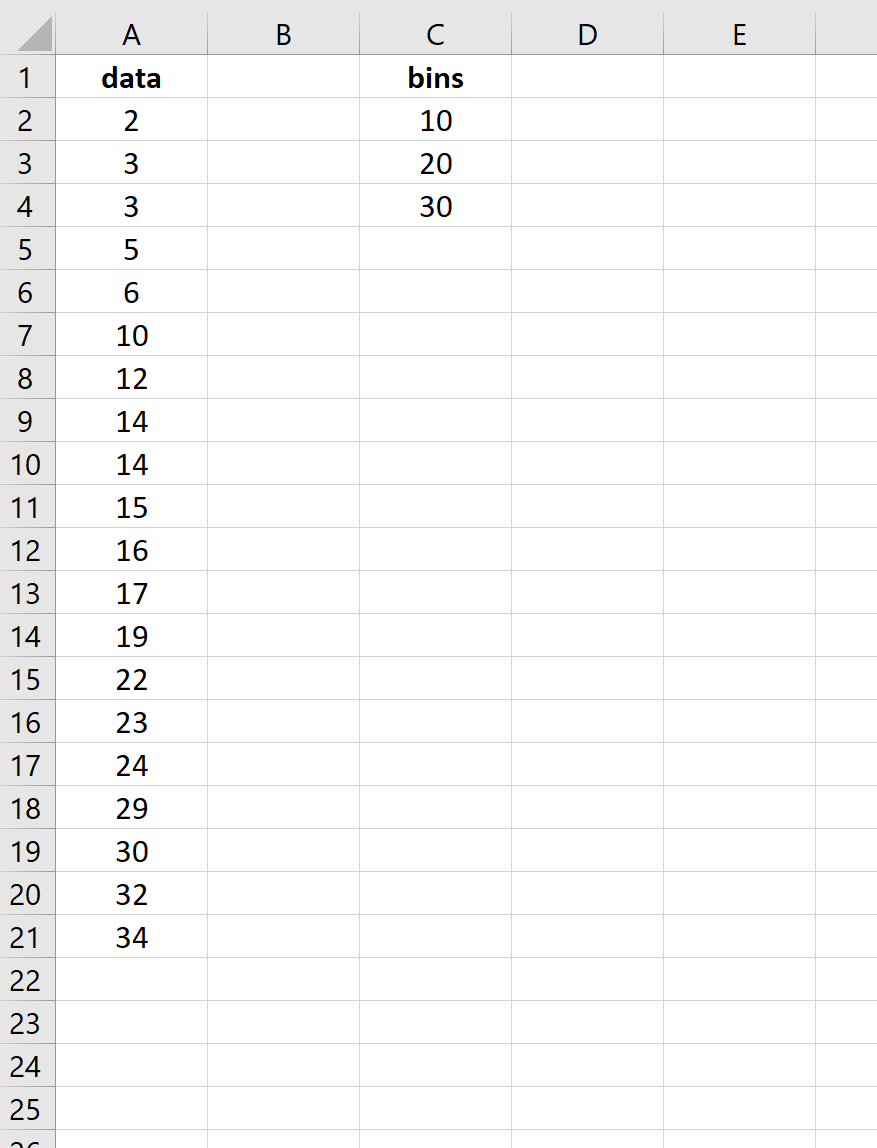
- от 0 до 10
- с 11 до 20
- от 21 до 30
- 30+
Далее мы будем использовать следующую функцию =FREQUENCY() для вычисления частот для каждого бина:
=ЧАСТОТА( A2:A21 , C2:C4 )
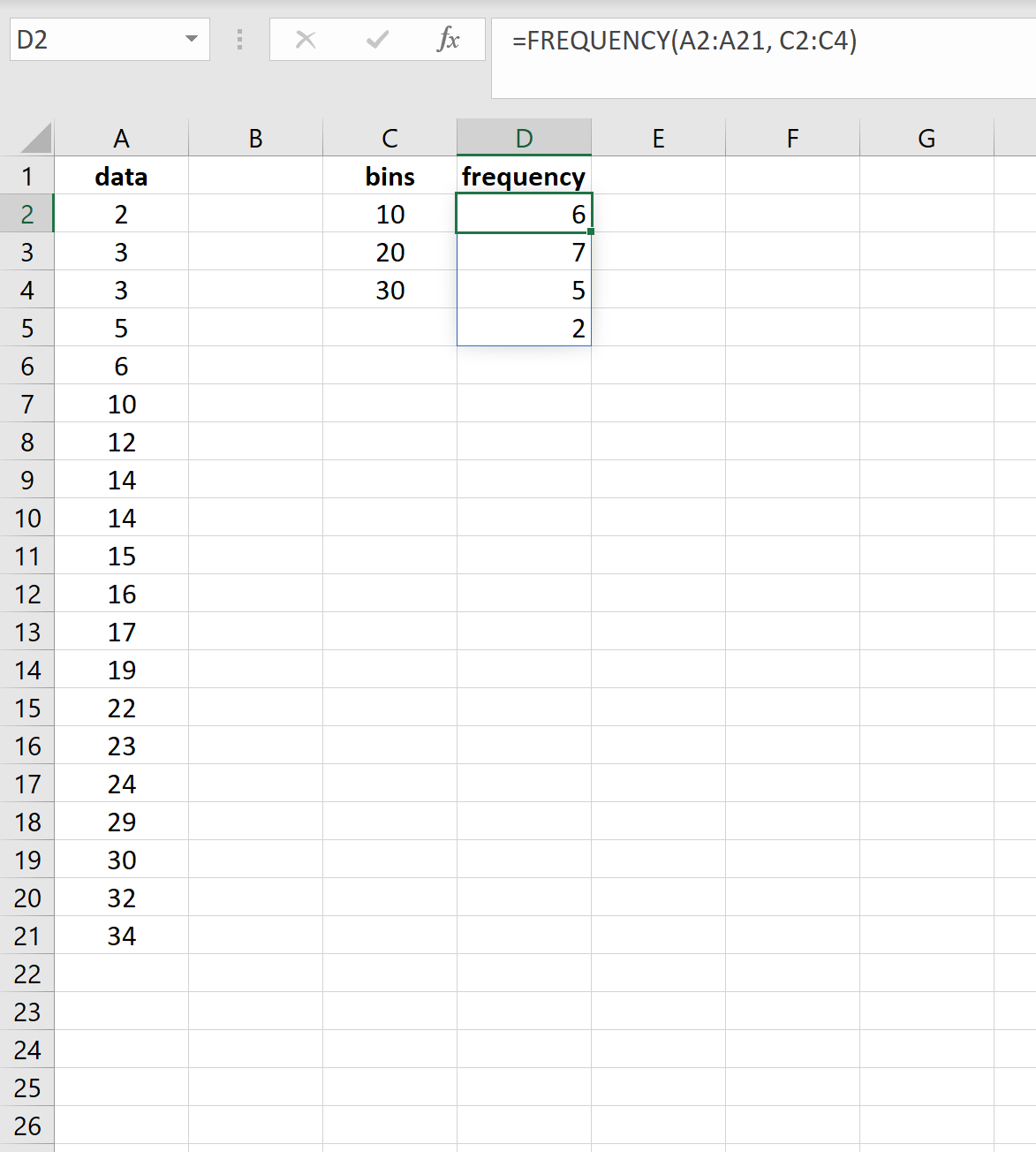
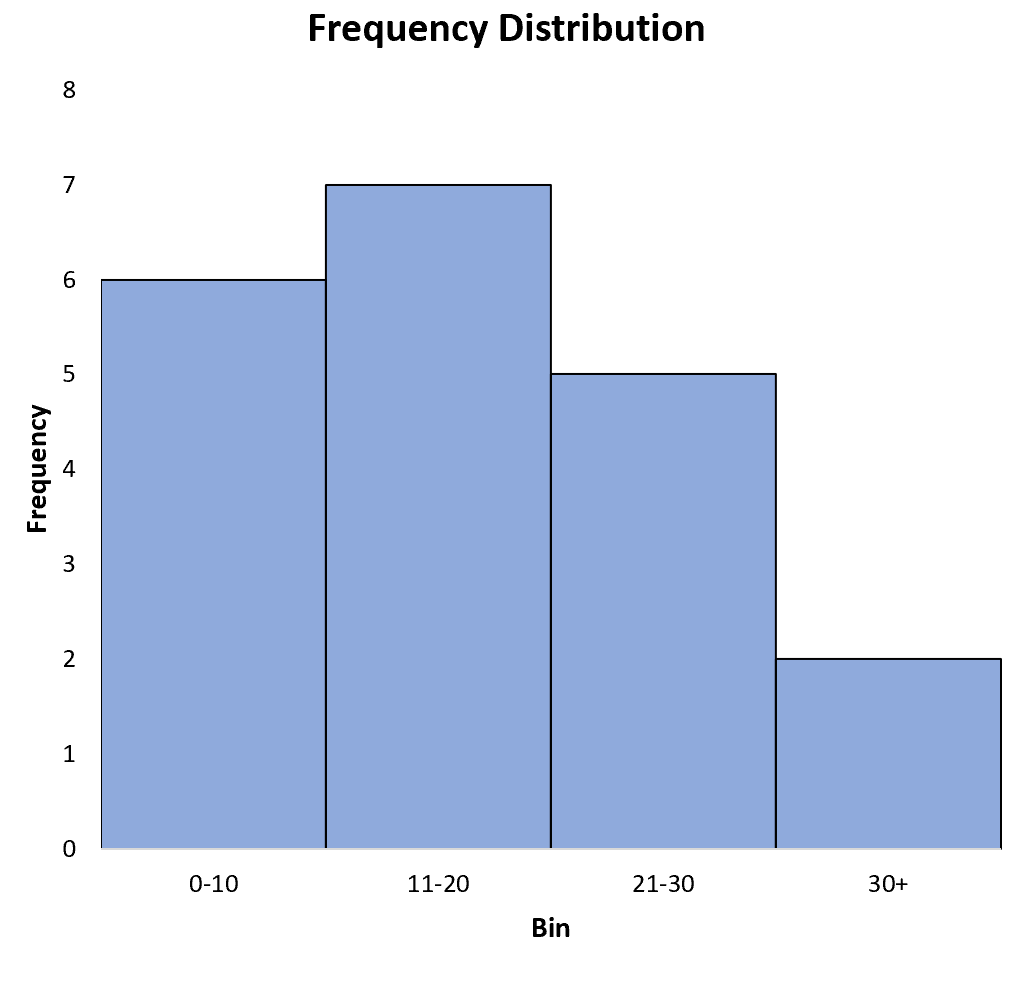
Результаты показывают, что:
- 6 значений в наборе данных находятся в диапазоне от 0 до 10.
- 7 значений в наборе данных находятся в диапазоне 11-20.
- 5 значений в наборе данных находятся в диапазоне 21-30.
- 2 значения в наборе данных больше 30.
Затем мы можем использовать следующие шаги для визуализации этого частотного распределения:
- Выделите частоты в диапазоне D2:D5 .
- Нажмите на вкладку « Вставка », затем нажмите на диаграмму под названием « Двухмерный столбец » в группе « Диаграммы ».
Появится следующая диаграмма, отображающая частоты для каждого бина:
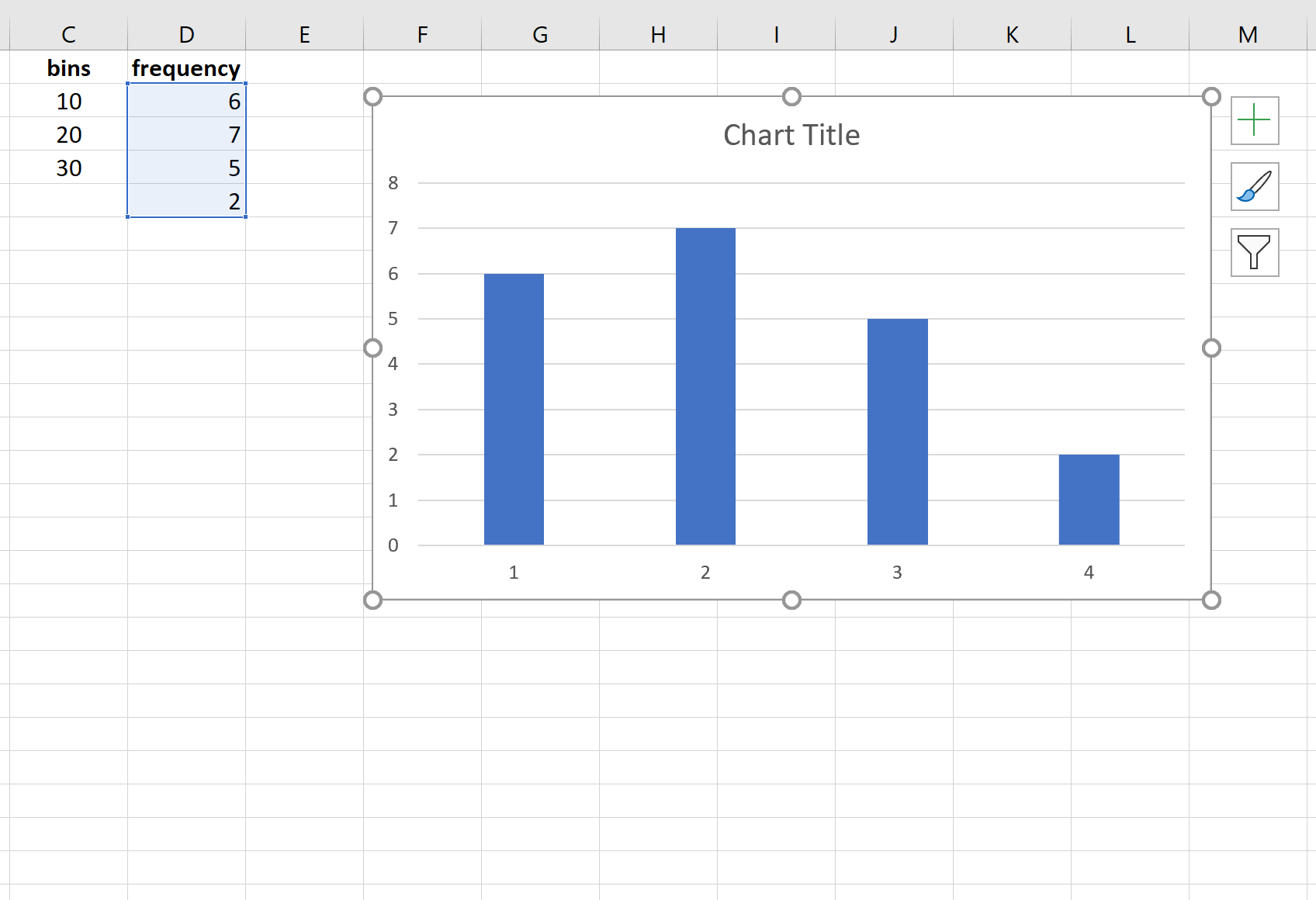
Не стесняйтесь изменять метки осей и ширину полос, чтобы сделать диаграмму более эстетичной:
Вы можете найти больше учебников по Excel здесь .